
This article was originally posted to the Ingeniously Simple Medium publication.
Having attended the last two European KubeCon events (2018 and 2019), it’s become increasingly obvious that operators are becoming a hot topic within the community.
There were zero sessions on operators in 2018, whereas there were 9 in 2019. There’s even a dedicated OperatorCon hosted by Loodse at this year’s (unfortunately postponed) KubeCon!
I also had the pleasure of attending the Operator Framework Workshop session delivered by Red Hat. This was an excellent session which covered the basics of Operators and how to create them using the Operator Framework.
So what is an operator?
The CoreOS documentation does an excellent job of explaining this, so I’ll only try and summarise it here.
An operator is an application that runs in Kubernetes, acting upon the presence of Kubernetes Custom Resources based on their definition. Typically, you might use an operator to handle the management of services within Kubernetes by encapsulating the operational knowledge of a given service in code. Ultimately, the operator runs as a pod within the cluster (possibly with more supporting pods).
As an example, take a look at the Zalando Postgres Operator. Running databases in Kubernetes can be tricky, since it requires persistent volumes, stateful sets, and services to expose them. Instead, the Zalando Postgres Operator encapsulates all the complexity of this behind a single “custom resource” in the cluster of type “postgresql”. You can see an example of a minimal postgresql configuration custom resource here.
Notice how it defines things such as the users and databases you want in the instance when it starts. Creating the users and databases is possible without an operator provided that the container image you use supports it. If it doesn’t, you’ll need to explore different options for initialising the database after the pod enters a ready state. Furthermore, you’ll have to handle the persistent volumes, statefulsets, and services yourself, including how all of those link up with each other.
Instead, the operator will create all of these resources for you without you needing to know the details. All you do as a consumer of the operator is create the postgresql custom resource and submit it to the cluster. The operator will do the rest — creating the associated resources in the cluster for you and performing any post-setup actions you defined. It can also (optionally) do things you already come to expect from Kubernetes such as deployments ensuring the correct number of pod replicas are always available. The details depend on the operator implementation.
In summary, the operator is effectively giving you a higher level abstraction over Kubernetes from the point of view of running and managing Postgres.

Operators add a level on top of the existing Kubernetes API — letting you work at a higher level of abstraction
How do you build an operator?
Whilst operators are a recognised pattern for building these solutions, there are also some opinionated frameworks that make it easy to get started with creating one.
The one I’ve had experience with is the operator-sdk, which is part of the Operator Framework.
This scaffolds all the boilerplate required for creating a Kubernetes Operator. It autogenerates things such as the custom resource definitions, the controller for consuming those custom resources, and all of the plumbing to communicate with the Kubernetes cluster itself.
The operator-sdk documentation is the best place to understand how to actually generate all these things, so I won’t repeat it here. If you’re looking to build an operator yourself, this is an excellent place to start.
How have we used operators?
One of the projects we’re working on at Redgate is Spawn. The idea of this is to provision databases for dev/test purposes instantly, irrespective of the underlying size of that database. You can also save arbitrary states of the database, instantly reverting destructive changes or jumping between known checkpoints to support and accelerate development.
We use a combination of different technologies within Spawn, but one of the key components is the Spawn Kubernetes Operator.
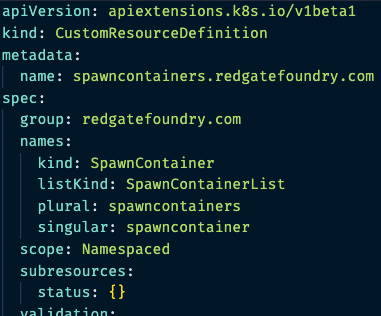
“spawncontainer” Kubernetes Custom Resource Definition (CRD)
This is responsible for provisioning database pods in a Kubernetes cluster according to a spawncontainer custom resource submitted to the cluster. The spawncontainer custom resource defines a few things in its specification:
- The database engine to provision
- Database engine-specific configuration parameters (e.g, admin credentials)
- The network location of the filesystem to use as the underlying filesystem for the database
This provides a nice abstraction for provisioning those databases. Typically, you’d have to handle creating a pod, with a mounted persistent volume claim that refers to a persistent volume, and then exposing that pod with a service.
Instead, the spawncontainer custom resource is submitted to the cluster with the desired configuration and the Spawn Operator consumes that, constructing and connecting all the necessary underlying Kubernetes primitive resource types. When it comes time to clean up this resource, we don’t have to worry about deleting each individual Kubernetes primitive. We simply delete the spawncontainer custom resource, which causes a cascade of deletions for all primitive resources that were created as a result.
This dramatically simplifies things for the supporting services that compose Spawn. They simply request a spawncontainer, and then at some point a database engine is available configured appropriately. The complexity of Kubernetes is hidden behind this abstraction, and operations are performed on the custom resource directly.
Building this operator has made developing Spawn significantly easier. We can take advantage of many of the benefits of Kubernetes without having to undertake constructing hand-crafted requests to the cluster API and figuring out how to watch resources and react to changes. Instead, we rely on the scaffolding from the operator-sdk and simply concern ourselves with writing the business logic — the piece that constructs and links all the Kubernetes resources together that represent a spawncontainer custom resource.
Conclusion
Operators are an excellent way to build applications that extend the Kubernetes API with domain-specific knowledge. You can hide the complexities of running a system by putting it behind a custom resource that represents the desired state of the system. Users simply interact with that object, and the important changes are made by the operator which effectively translates the domain specific resource into Kubernetes primitive resources.
If you’re looking to do this, then I’d recommend checking out the operator-sdk and having a play to see what you can do. If you’re trying to run a service in the cluster, then operatorhub.io is a great place to go to see if an operator already exists for managing it.
Thanks to our operator, we’ve also just launched a closed beta programme for Spawn. If you’re wanting to accelerate your dev/test workflows with instant isolated copies of large production-like database environments that you can immediately spin up, tear down, checkpoint and reset, then sign up at spawn.cc/beta.
You can also read more about Spawn here.

Top comments (0)