
Overview
In the last years, I was very happy exposing REST Web Services consumed by Angular JS clients (and using Swagger for documenting the API). But it was a situation in the last year when we had a huge data model with hundreds of entities exposed as REST resources. In that case, the REST was not enough. So, my rest was over - I started to search for a better way to expose and consume web services and I found something named GraphQL.
This doesn't mean that REST is over. A GraphQL API can stand in front of a REST API or the tho APIs can coexist at the same time. The idea is that there is a new way of consuming/exposing an API. It is better in the case we have a schema on the server-side. There is GraphQL For The Rest of Us
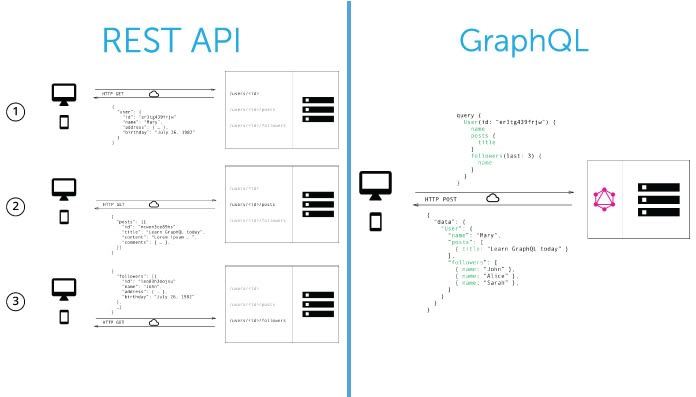
Image credit http://howtographql.com
The application story
The application was a classical client-server app with Java/EJB in the backend exposing a set of JAX-RS REST web services to an Angular client. We used JPA for persistence and we modeled the entire graph of entities using JPA annotations.
We split the domain in some aggregates with dozen of classes and with an aggregate root - mainly using IDs as fields instead of foreign keys. We exposed an end-point for some aggregate roots - in a rest-full way. The requirement of the project was to expose just CRUD operations in our endpoints (of corse not CRUD wasn't enough) because the business flows are part of the client application. This was good because we can respect the REST principle of having resources (NOUNS) with the state modified by the HTTP commands (VERBS).
We used Swagger for documented the API - the frontend team was able to call our API from Swagger UI in realtime. The Swagger/Open API documentation was generated dynamically from the annotated endpoints. The Angular front-end was generating the TypeScript client from Swagger using its code generation facilities. Everything seems to be fine.
But something wasn't all right. Our JPA entities are also our REST resources. In JPA the entities are linked together in a graph according to the database schema. When we get the aggregate root, we get the entire graph of entities with all fields. And because the entities are the resources the client is receiving a huge JSON file each time. Usually, in the Angular components, not the entire graph was needed, and not all the fields of the resources.
What we will do if we have a data model like in this story, a data model in which the company invested years to create. What we will do if we have a model like this GitHub data model:

Image credit: howtographql.com
There are a few patches
One is to use some annotation from the marshaling/un-marshaling framework @JsonIgnore, @XmlTransient on our entities to simplify the JSON received by the client. This is problematic because in some endpoints we need to send to the client some fields of the resources in other cases different fields - annotating the entities/resources will suppress the fields for all client calls.
Another solution is to create different WS endpoints and to hide some fields when we sent a response to the client. To use for example a different package of resources different from the domain entities and to populate them from entities when we send back the response. This is also problematic because we introduce more complexity - our API will be more in the RPC style (not REST) and we will have extra work in populating the resources from entities. And we have to write Named Queries or Criteria Queries to fetch the right data from the database and not just CRUD operations.
The last solution I know is to have real isolated resources and not graphs of objects exposed on the server-side. In this case, we will have multiple calls maybe 1+n calls on the cases of collections. So this is also a problem because of the multitude of calls we have to do.
The REST is not enough
This kind of project from the previews story shown a downside of the REST - it is not good for this case when we have a rich domain on the server-side - a graph of objects. In this case, the generated JSON is huge and enriched with un-necessary information. The solutions to solve this problem will lead us out of the REST style to remote procedures calls (RPC). Or to complicate the backend using some extra code - not use just simple ORM CRUD operations.
For these cases, it seems that GraphQL is the solution. We will ask the server just for the pice of information we need. Because we don't want the entire schema. REST is fine when we have isolated pieces of information like system messages, notifications. But is not good for the case we have a big schema.
And schemas are everywhere - documents (XML, PDF, JSON), the file/folders file systems, relational databases (even if is a forced schema), DOM, etc. REST is ok for non-relational databases (MONGO-DB) where we have collections of entities. But is a relational database we store a graph of objects (even if we do this in a forced way). That's how we store the majority of the data we have now.
Introducing GraphQL
GraphQL was born from the effort of the Facebook team to accommodate the application to the modern world of mobiles. It is used inside Facebook along with other technologies like React or Jest, also invented by this company. The complete story can be found in this GraphQL original documentary, presented by the developers of the technology.
GraphQL was at the beginning just a specification about how to interact with the data from the client perspective in a declarative way. First, a reference implementation was created for Java Script, and other developers started to implement it on other programming languages. It is not a way to expose an API on the server-side, but a way to consume data from the client-side. It doesn't specify the dataset that is exposed if it is a database or a REST API. It doesn't specify the communication protocol that is used - if it is HTTP or not!
GraphQL provides a method to document the API, a way to specify the API capabilities named Schema. Historically speaking, we have GraphQL/Schema as we have SOAP/WSDL, REST/Swagger-OpenAPI. We can start from this schema to generate de client or the server in the same way we do with the other types of web services APIs (REST or SOAP).
Steps to learn GraphQL

- First watch this video named GraphQL - The documentary to understand how, when and why this technology was born
- Learn as match you can from these GraphQL video tutorials
- Make some real calls with an existing UI client and on an real online APIs
- Study the support for GraphQL in your preferred programming language
- Implement an API on a simple schema
- Read the GraphQL spec
- See how Gatsby.js implements the source and transformers plugins
Gatsby.js vision
I can't finish this article without saying something about Gatsby.js. Why can I name it the next WordPress? Because it has everything, Wordpress has a pluggable system with themes, easy to extend by developers, based on the right abstractions. It is a way to create micro frontends combining React components with GraphQL schemas.

To be honest, I dreamed of this for a long time in the form of a combination of Web Components and Microservices - but it seems that React/GraphQL is offering this under the Gatsby.js umbrella right now when you read this.
Gatsby is offering a good option to create static progressive web apps. For the GraphQL part, Gatsby is offering a set of sources and transformers plugins that are letting you pull data from headless CMSs, SaaS services, APIs, databases, your file system or any other source.
Inspirational Resources Links
GraphQL documentation
- GraphQL documentary - https://youtu.be/783ccP__No8
- Technology site -https://graphql.org/
- How to GraphQL - https://www.howtographql.com/
- Introduction to GraphQL - https://graphql.org/learn/
- Play with online GraphQL APIs - https://www.graphqlhub.com/
- Build FB with React, GraphQL and Relay - https://www.youtube.com/watch?v=WxPtYJRjLL0
- GraphQL-conference -https://www.graphqlconf.org/
- Awesome GraphQL GitHub - https://github.com/chentsulin/awesome-graphql
Client support
- Apolo Client - https://github.com/apollographql/apollo-client
- Relay Client - https://relay.dev/
Server support
- Spring Boot Server support - https://www.pluralsight.com/guides/building-a-graphql-server-with-spring-boot
- Grails Gorm Server support - https://grails.github.io/gorm-graphql/snapshot/guide/index.html
IDE/UI Clients
- Voyager Client - https://apis.guru/graphql-voyager/
- GraphiQL Client - https://github.com/graphql/graphiql
- GraphiQL Client Electron packaged - https://electronjs.org/apps/graphiql
- Playground Client - https://github.com/prisma/graphql-playground
- Altair Client - https://altair.sirmuel.design/
Micro frontends
- Micro Frontends - https://micro-frontends.org/
- Micro Frontend Martin Fowler - https://martinfowler.com/articles/micro-frontends.html
Gatsby
- Gatsby static site generator - https://www.gatsbyjs.org/
- Gatsby source plugins - https://www.gatsbyjs.org/plugins/?=source
Others

Top comments (0)