

Introduction
When developing a predictive model, one of the most important phases is feature engineering. Its major objective is to help our model understand some of the underlying features in our datasets so that our model can predict on those features. Remember that machine learning models operate best with numerical values because they are based on mathematical equations, therefore feeding the model with values other than numerical values may be daunting for our model. So, through feature engineering, we can assist our model in understanding specific features in our datasets.
I'll be writing a series of posts in which I'll discuss several types of feature engineering. This is the first post of the series.
To give you a quick rundown of what I'll be covering in this post. This is a summary of the posts.
- What is Feature Engineering?
- The Categories of Feature Engineering
- What is a Categorical Feature?
- What are the type of Categorical Feature
- How do you encode a Categorical feature and what are the use cases that will allow you to use a particular encoding technique.
What is Feature Engineering?
In order for me to clarify what feature engineering entails. I'd like to start with this Wikipedia definition because it gave me an intuition of what Feature Engineering is all about.
According to Wikipedia, feature engineering is the process of extracting features from raw data using domain knowledge . The purpose for this is to leverage the extra features to improve the quality of a machine learning process rather than providing merely raw data to the machine learning process.
As we all know, for ML models to perform well, the data must be in an appropriate format (mostly numerical values), and in order for us to do that, there must be domain knowledge or expertise that will guide us as to how we want to engineer these features so that after we are finished with the engineering, the new features will still portray what the older ones are all about.
Consider the following scenario: you have a categorical feature that you want to encode in your dataset. As a data scientist, you must have domain knowledge or seek expertise so that when you encode a variable using a specific technique, how will it effect the data and will the encoding technique still convey what the data is all about?
So my take on feature engineering will be that: In layman's words, feature engineering is the process of selecting, extracting, manipulating, and transforming data using domain expertise so that the resulting features still reflect what the data is all about and are easily understood by the model.
Feature engineering can be a difficult process to do because it involves expertise knowledge and takes a long time. However, it is critical to concentrate on. When I think of feature engineering, I always think of these two quotes from two of the data space's most famous figures.
Coming with features is difficult, time consuming, requires expert knowledge. Applied Machine learning is basically feature engineering — Prof. Andrew NG.
The feature you use influences more than everything else the result. No algorithm alone, to my knowledge, can supplement the information gain given by correct feature engineering — Luca Massaron
Categories of Feature Engineering
Feature Engineering is divided into 4 different categories which include:
- Feature Transformation.
- Feature Extraction.
- Feature Creation.
- Feature Selection.
As our topic suggests in this post, we will discuss feature transformation; other categories will be discussed in later series.
Feature Transformation
The process of turning raw features into a format suitable for model construction is known as feature transformation. Our model will be able to understand what each feature represents thanks to feature transformation. Feature transformation includes things like numerical transformation and scaling, categorical variable encoding, and so on. We will talk about numerical transformation and scaling in the next series.
What are Categorical Variables/Features?
Categorical features represent data that may be classified into groups. Colors, animals, and other things could be represented by them. Examples include race, color, animal, and so on.
Type of Categorical Features
Categorical variables can be divided into 3 categories which include:
Binary Values: They often depict two quantities. They are regarded as either/or values. Examples include yes or no, True or False.
Nominal Values: In the real world, this type of category feature does not depict order. When you try to order them, nothing makes sense. Example include (Colors: black, blue, and red), (Animal: cat, dog, fox), etc. We can see that each element represents a separate unit, therefore attempting to organize them makes no sense.
Ordinal Values: In the real world, this type of data can be ordered. For example, (cold, hot, very hot), (low, medium, high), grade score(A, B, C) and so on.
How to Encode Categorical Features
We can encode our category features using a variety of encoding techniques. We'll go through the most common one you'll come across on a daily basis. However, encoding binary and ordinal categorical features is simple and does not need much effort, whereas encoding nominal data can be difficult and sometimes requires domain expertise when working with them. We'll go over how to encode all of these categorical features.
Note: For encoding categorical features I will be using a library in python called category_encoders if you don't have it installed you can use the following below code
#For Pip install
pip install category_encoders
#For conda environment
conda install -c conda-forge category_encoders
Encoding Binary Values
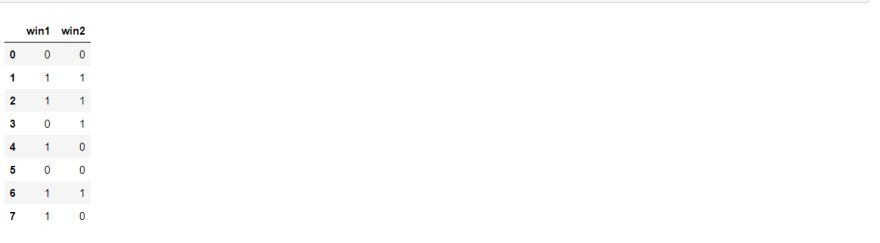
It is not difficult to encode binary categorical variables. Because binary categorical variables like True or False can be related to the value of a logic gate (0's and 1's). We may simply accomplish this with a Python function or method. True values will be treated as 1s, while false values will be treated as 0s. It also works for Yes and No. We can use either of these codes to achieve this.

#converting the first feature win1 using the replace method
df["win1"] = df["win1"].replace({"N":0, "Y":1})
#converting the second feature win2 using an anonymous function
df["win2"] = df["win2"].apply(lambda x: 1 if x=="T" else (0 if x == "F" else None))
Encoding Ordinal Values
Encoding ordinal values is also a pretty task to perform since they those values are ordered i.e. they can be ranked it is easier to get straight with them. Consider the following scenario. You have an ordinal value that ranges from extremely weak to weak to strong. Because extremely weak is the lowest value and strong is the highest, we can encode this value in the logical order of 1, 2, 3. 1 represents very weak, 2 represents weak, and 3 represents strong. Now that we've understood that for us to do this in python we type.

from category_encoders import OrdinalEncoder
transformer = OrdinalEncoder(mapping= [{'col': 'ordinal_data',
'mapping': {"strong": 3, 'weak': 2, 'extremely weak': 1}}])
df["ordinal_data"] = transformer.fit_transform(df["ordinal_data"])
You must provide the column that you want to encode in the mapping parameter (i.e. the one with the col key in the code above), otherwise it will encode any categorical feature it sees. Also, the mapping key tells the encoder how to rank the variable, because if you don't supply it, the encoder will choose the first value as 1. For example, in our scenario, if we don't provide the first value, it will be encoded as 1, and the other values will be encoded as they occur.

Encoding Nominal Data
As I previously stated, encoding nominal values can be tricky because it necessitates knowledge of how to encode them. Some of the most common methods of encoding nominal data are as follows.
One-Hot Encoding
Consider a column with three values: black, red, and blue to better comprehend one hot encoding. One-hot encoding will take each categorical value in that column and convert it into a new column, assigning the values 1 and 0 to them. Let's look at an example to better grasp what's going on.

from category_encoders import OneHotEncoder
transformer = OneHotEncoder(cols="one_hot_data", use_cat_names=True)
df = transformer.fit_transform(df)

As seen in the preceding figure, new columns were constructed from those values, and whenever each value occurs in that row, it will be allocated 1 while the others will be assigned 0. We can see in the previous image that black was the first value that occurred in the row, and in the second image that it was allocated 1 while other values were assigned 0 because only black occurred in the row. Similarly, blue occurred in the second row, therefore in the new image blue was assigned 1 only then black and blue column were assigned 0.
Frequency Encoding
It a very simpler technique. What is does is that it counts the number of times a nominal value occurs. Then it then maps the frequency back to the column. Let's go over an example so we understand what's going on.

from category_encoders import CountEncoder
transformer = CountEncoder(cols="one_hot_data")
df = transformer.fit_transform(df)

We can see that in the previous figure black occurred 2 times and red occurred 3 times. So Frequency encoder assigns the frequency at which those value occur to the column back. This technique is very efficient. You can also add a normalize parameter if you wish to have the relative frequency of each value. Something like this
from category_encoders import CountEncoder
transformer = CountEncoder(cols="one_hot_data", normalize=True)
df = transformer.fit_transform(df)

Note: You might be thinking when to use the relative frequency or the Frequency only. Consider for instance you have a column with high cardinality. It will be efficient for you to make use of the relative frequency rather than the normal frequency.
When To Use OneHot Or Frequency Encoding.
If the number of unique nominal values in your column is small, you can use OneHot encoding. However, if they are numerous, i.e. there is a high cardinality, utilize frequency or relative frequency. However, I prefer the relative frequency😀.
Conclusion and learning More.
Please keep in mind that there are other encoding techniques available, each with its own set of applications. If you want to learn more about them, I will employ you to investigate more online . However, the encodings listed above are some of the more typical ones you will see on a daily basis. Thank you for taking the time to read this. I'll be releasing my second series soon, which will cover numerical transformation and scaling. Watch out for it 🚀🚀.

Top comments (0)