
After learning quite a few things about Machine Learning and having trained two to three models, the first thing (well... one of the first things) that comes to your mind is... Its time to put Machine Learning to work and predict the Stock Market and become rich!
Well the becoming rich part might be too far from reality (maybe) as the market is quite unstable and unpredictable, but there is no harm in trying out the amazing power of Machine Learning and analyzing the outcome. Well that's the fun in Machine Learning. We are never going to know the outcome unless we try!
So, this post is all about me trying to predict the Stock Market using LSTM (Long Short-Term Memory). Don't worry if you are unfamiliar with LSTM or heck with it, even Machine Learning, I have written this post in such a lucid manner that even a baby can understand and comprehend the working idea behind it (maybe).
If you are only interested in the code that I wrote, feel free to skip to the very end of this post. You will find the link to my GitHub repository.
The topics that I will be covering is mentioned below. Feel free to jump and skip through them as you wish.
Table of Contents
- A brief introduction to LSTM
- Background Information
- Predicting the Stock Market
- Tweaking the Hyper-parameters
- Bitcoin Market Models
- USD/CAD Forex Market Models
So Let's Begin.
A brief introduction to LSTM
LSTM or Long Short-Term Memory is an improvement over traditional RNN or Recurrent Neural Network in the sense that it can effectively “remember” long sequence of events in the past. Just like humans can derive information from the previous context and can chart his future actions, RNN and LSTM tends to imitate the same. The difference between RNN and LSTM is that RNN is used in places where the retention of memory is short, whereas LSTM is capable of connecting events that happened way earlier and the events that followed them.
Hence, it (LSTM) is one of the best choices when it comes to analyzing and predicting temporal dependent phenomena which spans over a long period of time or multiple instances in the past.
LSTM is capable of performing three main operations: Forget, Input and Output. These operations are made possible with the help of trained neural network layers like the tanh layer and the sigmoid layer. These layers decide whether an information needs to be forgotten, updated and what values need to be given as output. LSTM learns which parameter to learn, what to forget and what to be updated during the training process. That is the reason why LSTM requires a huge amount of dataset during its training and validation process for a better result. The sigmoid layer decides the flow of information. Whether it needs to allow all of the information or some of it or nothing.
There are multiple gates that performs the role of Forget, Input and Output. These gates perform the respective operation on the cell state which carries information from the past. The forget gate layer tells the LSTM cell whether to keep the past information or completely throw away. The input gate determines what new information should be added to the cell state. The output gate finally gives the output which is a filtered version of the cell state.
Background Information
What is Machine Learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
How is it Different from Deep Learning?
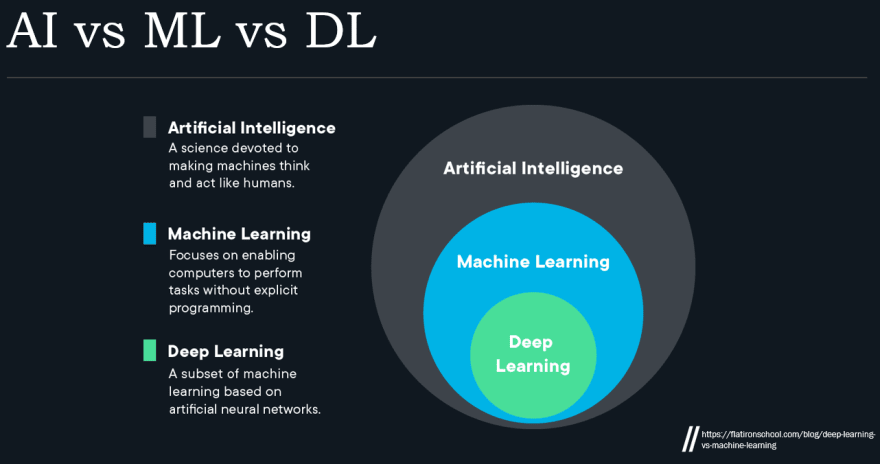
- Machine Learning is the superset. Deep Learning is the subset.
- ML is the ability of computers to learn and act with less human intervention.
- DL is all about mimicking the thinking capability of the human brain and arriving at a conclusion just like a human does after analyzing and thinking about it for a while.
Artificial Intelligence vs Machine Learning vs Deep Learning
Neural Networks
Neural networks, also known as Artificial Neural Networks (ANNs) are a subset of Machine Learning and are at the heart of Deep Learning algorithms. Their name and structure are inspired by the human brain, mimicking the way that biological neurons signal to one another.
It comprises of several nodes which represent neurons. A collection of nodes creates a node layer. These node layers play specific roles. Some acts as input layer, some hidden layers and some acts as output layer. Each node, or artificial neuron, connects to another and has an associated weight and threshold. It is by tweaking these weights and thresholds, that the network is able to learn progressively.
There are different types of neural nets : Convoluted Neural Networks, Recurrent Neural Networks, etc.
Simplest Neural Network

[ Source: https://www.ibm.com/in-en/cloud/learn/neural-networks ]
This is called a perceptron. It has only one input layer, one hidden layer comprising of only one node and one output layer.
Deep Neural Network

[ Source: https://www.ibm.com/in-en/cloud/learn/neural-networks ]
- Contains multiple hidden layers
- Since the depth of hidden layers is deep, hence the name.
Recurrent Neural Network
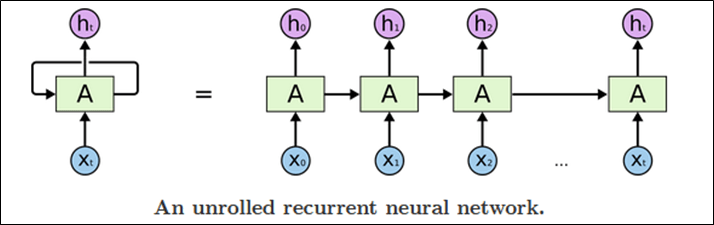
[ Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs ]
- Uses sequential data or time series
- Used in solving temporal dependent problems: Natural language processing, image captioning, speech recognition, voice search, translation, etc.
- Inefficient when it comes to prediction where the outcome is long term temporal dependent.
- The reason being Exploding and Vanishing gradient.
- LSTM overcomes the drawback
Long Short Term Memory
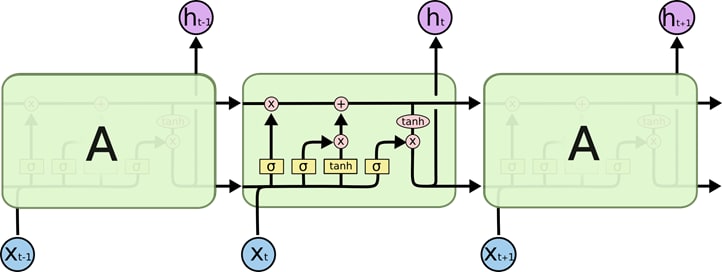
[ Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs ]
- Contains a cell state that carries information from one state to another
- Gates manipulate the info in the cell state. Three main gates used to do this are: Forget gate, Input gate, Output gate.
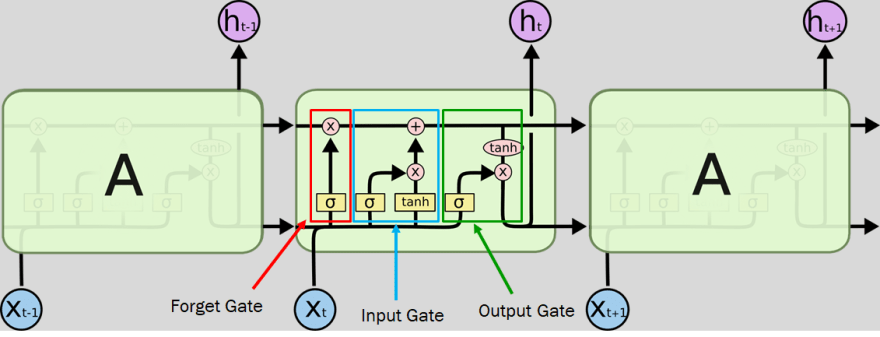
[ Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs ]
- Forget Gate: Responsible for removing useless information.
- Input Gate: Responsible for adding new information.
- Output Gate: Responsible for filtering the information.
Predict the Market
Description
- An attempt to predict the Stock Market Price using LSTM and analyze it's accuracy by tweaking its hyper-parameters.
- For this purpose, two Stocks have been used for training the model: Bitcoin Market and USD/CAD Forex.
- A total of 48 models will be trained for each Stock. Each model will be different from other in the sense they will be trained on different hyperparameters.
- The line charts of all the models will be plotted, its accuracy will be observed.
Plan Of Attack
- Data Acquisition
- Data Preprocessing
- Structuring Data
- Creating the model
- Training the model
- Prediction
- Plotting chart and accuracy analysis
Data Acquisition
- Yahoo finance maintains past data of hundreds of Stock Markets. One can easily download the data in the form of CSV files and use it for training.
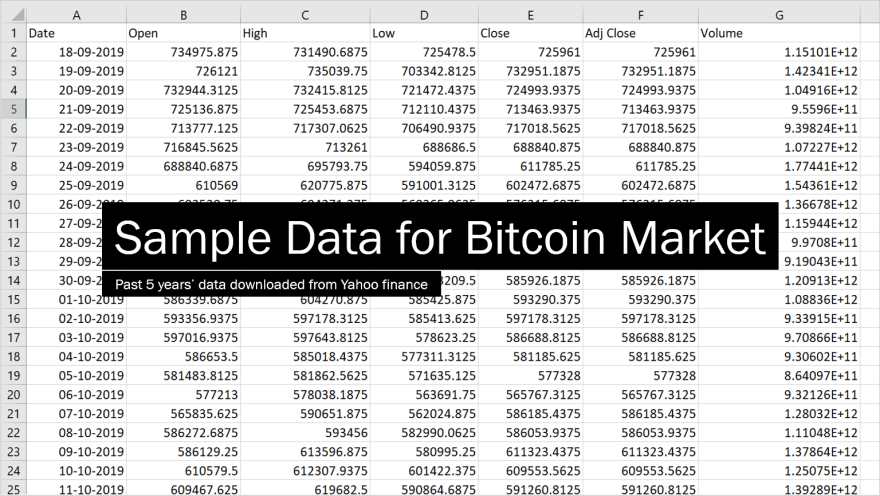
- Past 5 years data is downloaded for both Bitcoin and USD/CAD Forex.
Data Preprocessing
1. Data Cleaning
One of the many important stages in creating an efficient model. Data contains discrepancies. If not removed, they might cause hinderance in producing accurate results. Null values are the most common.

2. Data Extraction
Not all the data that we downloaded are necessary for training purpose. Fields like Date are unnecessary, hence we don't need them. In this project, I have chosen Open (which stores the opening price of the market) as the deciding variable that predicts the outcome. Remember that one can choose multiple deciding factors as well. The reason I have chosen Open field is because, certainly, the Stock Market price depends on the previous days' opening prices. If I were to buy a Stock, I will definitely look at opening price among other factors. Hence training the model on opening price seems feasible. But one can always opt for multiple deciding factors like considering both opening and closing price together.
Now the extracted data is stored in a 2D array for further processing.
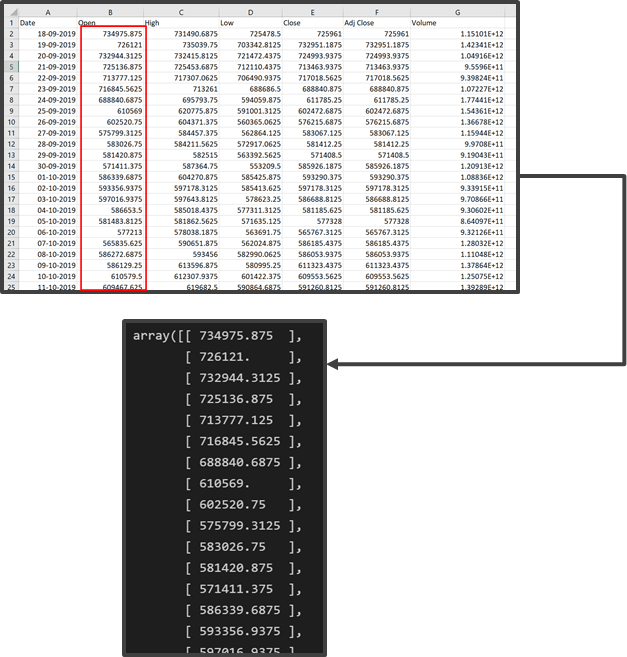
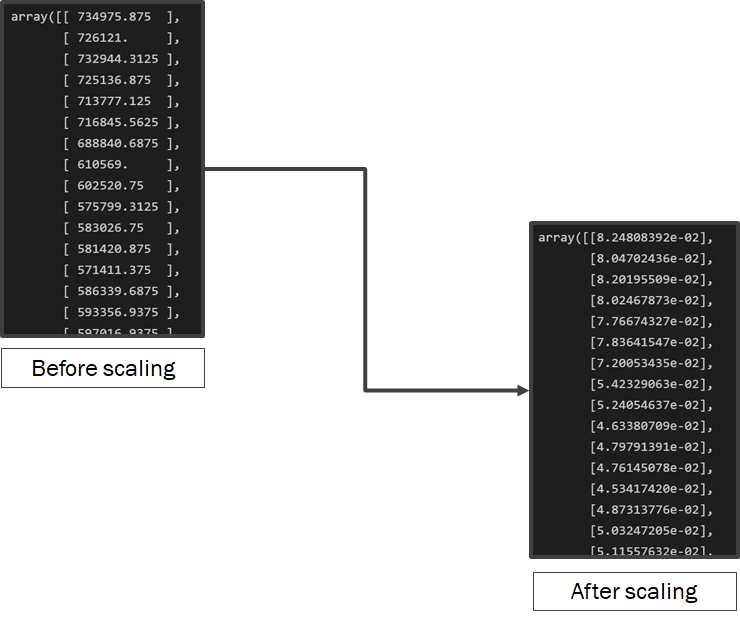
3. Feature Scaling
Feature scaling is the most important part of Data preprocessing. It helps in standardizing / normalizing the given dataset so that one entity is not given more importance than the other solely based on their quantity. Consider this as bringing all the scattered data within the same level for easier analysis. I have used MinMaxScaler() to scale all the values between 0 and 1.
Structuring Data
- The LSTM takes a series as an input. The length of the series is equivalent to the number of previous days.
- X_train will be the inputs for training set
- y_train is the output for training set Similar data structure is created for preparing prediction dataset.
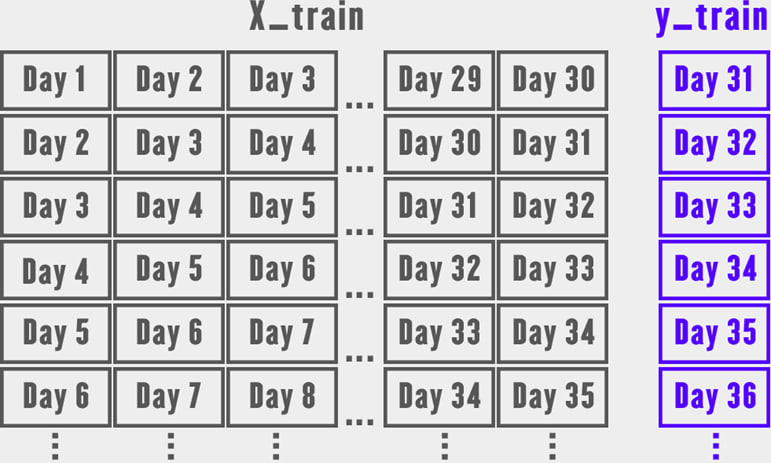
Structuring the data for training purpose. The model will use previous 30 days (it will be changed later while tweaking with hyper-parameters to improve accuracy) as the deciding factor and will predict the opening price for 31st day.
Creating the model

Training the model
This is the stage where we play with the hyper-parameters to bring about changes in the how the machine learns. The parameters which will be tweaked are: BATCH_SIZE for LSTM, EPOCHS and previous DAYS

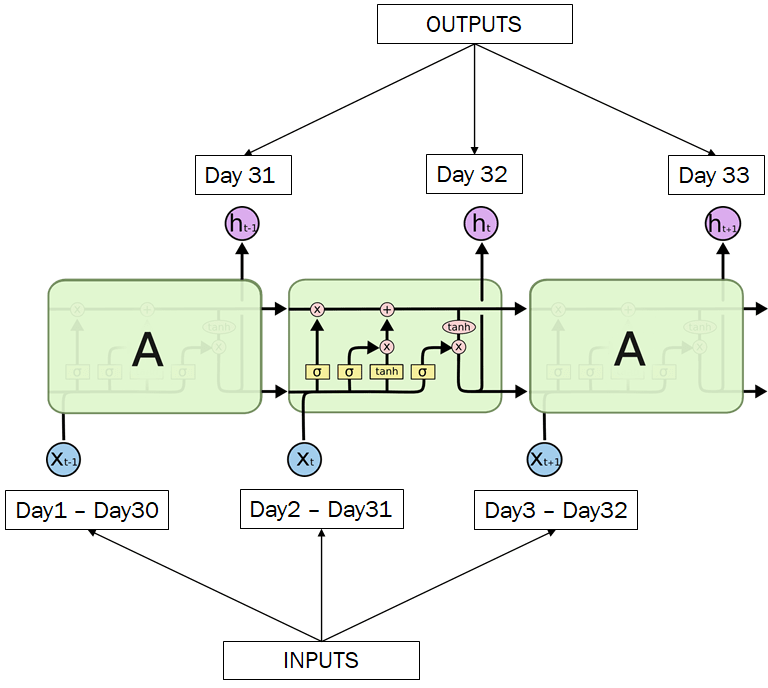
Prediction
The model has been trained. Now its time to predict the next day's price. For this purpose, a test dataset is created which contains past days' opening prices. This dataset is structured the same way as done in the Data Structuring step. Then these values are fed one by one to the LSTM input layer and the output is collected and stored in a 2D array for chart plotting and accuracy analysis.
Plotting the Chart
Based on the output we gathered, a line chart is plotted. The chart contains both the predicted and original price for accuracy analysis. From these charts we can clearly identify which model performed well. And... this chart definitely did not perform good at all.
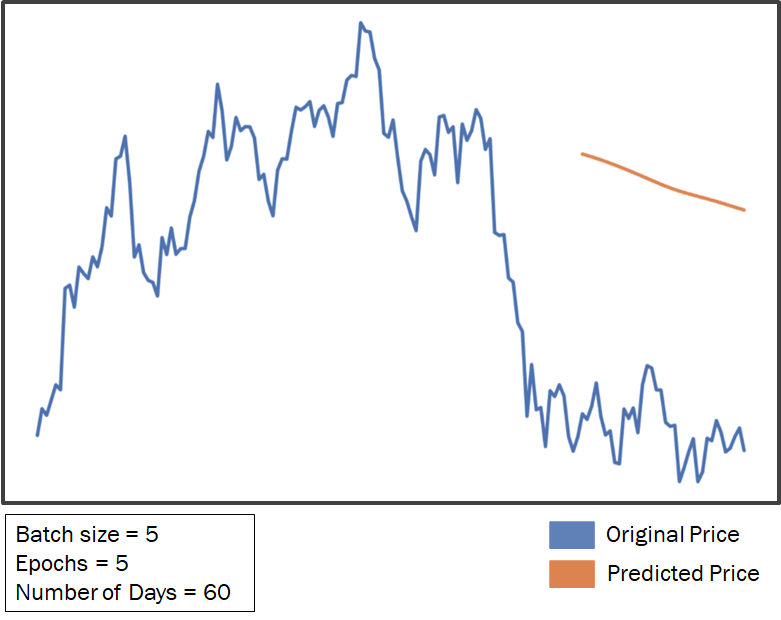
Hence, we are going to tweak some Hyper-parameters to make it more accurate!
Tweaking the Hyper-parameters
Tweaking hyper parameters brings about a change in how the model learns and analyzes the given data. Hyper parameters considered in this research project are: Batch Size, Number of Epochs, Number of Days. A total of 48 different models are created. Each containing different hyper-parameters.

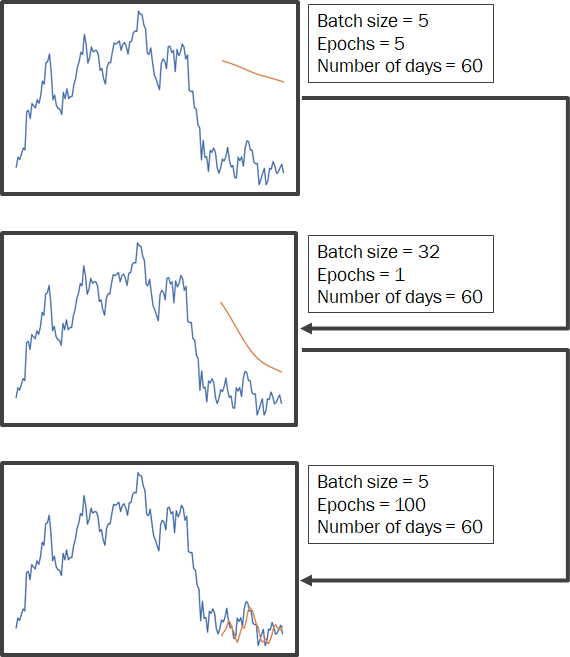
Now below are some Stock Markets I used to test the models' accuracy.
Bitcoin Market Models
All the 48 models of Bitcoin Market were trained. It is surprising to see some graphs with striking resemblance to the original one!
Worst Performing Model
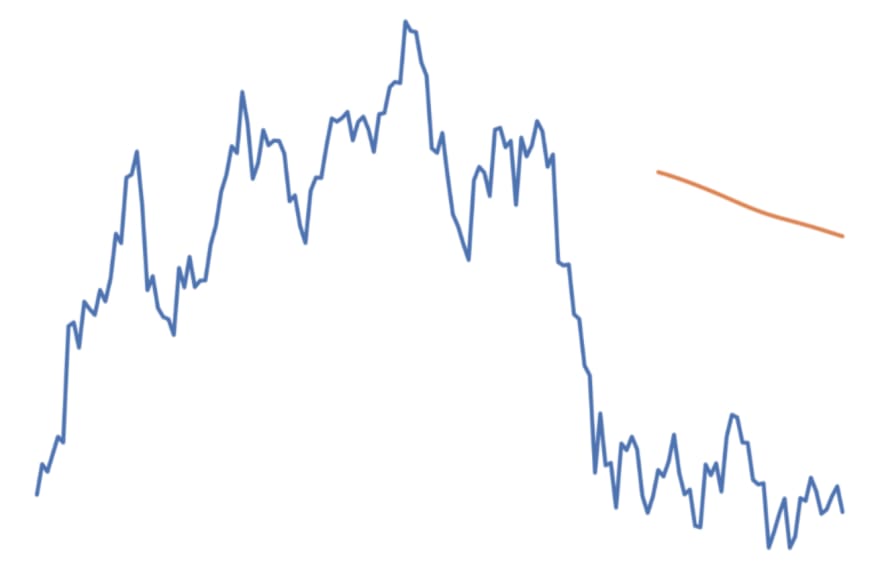
One of the Best Performing Models

USD/CAD Forex Market Models
All the 48 models were trained. It is surprising to see some graphs with striking resemblance to the original one!
Worst Performing Model

One of the Best Performing Model

Phew! Let's Conclude!
Isn't Machine Learning great? Although its a tough job to identify and play with the correct hyper-parameters, but in the end if you get it right, the outcome can be fruitful. In our case, even though the model is not absolutely perfect, but hey! The computer tried its best to learn and it did quite a good job! At least the computer can understand the Market much better than I do :(

Top comments (0)