
In this article, we'll be discussing everything you need to know about the basics of AWS Lambda error handling and some popular methods using StepFunctions and X-Ray. Regardless if you're an AWS Lambda expert or if you're a new Lambda user, there's always something new to learn. You've probably already encountered Lambda errors that may seem pretty challenging since the mechanism that runs Lambda retries will often make it incredibly difficult to follow up on changes that occur within your serverless application.
Serverless is not all about straightforward execution of code on Lambda function, but it's a different type of architecture of your entire system. Distributed nodes within this architecture that are activated thanks to asynchronous events are what makes this system.
Every node has to be designed like a singular part with its own API.
To learn how to define all these nodes accurately, you have to know how to handle Lambda errors. In addition, it's necessary to deal appropriately with Lambda retry behavior as well.
Therefore, let's jump right into how do the AWS Lambda retries and errors work, as well as what's the whole buzz around it all.
Lambda Retry Behavior
Lambda functions can fail (they will), and when they do, it's because of one of these situations:
- Lack of memory --- if you're out of memory, Lambda often terminates with the message 'Process exited before completing the request.' The 'Memory Size' is always the same as 'Max Memory Used.' You can learn more about resource allocation and AWS Lambda memory here.
- Raised unhandled exception --- can happen because of a programming bug, failure of an external API, or if you've received an invalid input.
- Timeout --- 'Task timed out after X seconds' message appears when Lambda closes violently because it ran longer than the pre-configured timeout duration. The maximal value is five minutes, while the default value is set at six seconds.
When failure occurs, and it will occur at some point, you'll most likely notice Lambda retries based on these behaviors:
- Stream-based events -- if the current events are solely DynamoDB streams and AWS Kinesis Data Streams. When it happens, AWS triggers these failing Lambda functions again until they're processed successfully or until the data expires, and AWS will block the event's source until it happens.
- Synchronous events -- In event sources like synchronous invocation or API Gateway using the SDK, the invoked app is responsible for creating response-based retries that it gets from Lambda. This case scenario is the least interesting one since it resembles monolithic error handling.
- Asynchronous events -- Lambda invocation happens asynchronously for most event sources. This means that no app will respond to failure. Therefore, the AWS framework will take care of it on its own. It'll trigger the Lambda again with precisely the same event, which happens mostly twice within the upcoming ~3 minutes (in some sporadic cases, it takes up even to six hours, while a different number of continuous retries can happen). In case all retries fail, it's mandatory to record this event instead of throwing it away. That's why the crucial Dead Letter Queue (DLQ) feature enables the configuration of DLQ via AWS SQS that'll receive this type of event.
Consequences of AWS Lambda Retry Behavior
Every Lambda can be executed multiple times with the same input, while the "caller" didn't know about it happening. To successfully perform the same operation several times, Lambda has to be 'idempotent.' Idempotency means that no added effects will take place when it's run by the same input more than one time.
It's worth mentioning that serverless functions aren't the only example when it comes to idempotency terms. A standard model is the API network: when a request doesn't receive a response, the same request will be sent repeatedly.
For example, in Serverless architectures, it can come to a similar case when Lambda gets a timeout before receiving a response. Even though it's a highly unexpected thing to happen, in some cases, a wrong retry handling can be the cause of severe problems (a database (DB) structural violation).
What is AWS Lambda Idempotency?
The definition of idempotency states that it's the property of specific operations in computer science and mathematics. It's applicable several times without disrupting the result beyond the first application. However, it's still somewhat confusing.
What happens if you wish to execute the same operation several times and it's not actually a retry?
Let's say that Lambda received a user operation log as input, and it's solely responsible for recording that operation log into a database. In this example, we'll need to make a difference between Lambda's trigger input and a retry case since they're the same because the user has initiated the same operation again.
Referring to the Lambda's request ID as a part of the input itself is the right solution. Only when there's a Lambda retry, you'll obtain the same ID. To be able to extract it, utilize context.awsRequestId within Node.js or the appropriate field in any other language. What this method does is it provides the general approach that'll search for retry executions.
It's not always a convenient solution to utilize the request ID for being a genuine idempotent. You might have noticed within the previous example that this ID should've also been saved in the DB. That way, the following invocations would realize whether there's a need to add a new record. There's one more solution, and it's using some in-memory data store. However, it might add quite a significant overhead.
Using AWS Step Functions to Build a Control System for AWS Lambda Error Handling
AWS Lambda error handling can be done in different ways, like utilizing wrappers. On the other hand, AWS Step Functions have proved to be incredibly beneficial for building a serverless application that'll deal with retries and errors appropriately, making Step Functions an effective solution. You can learn more about AWS Step Functions in our Ultimate Guide to Step Functions.
Take the Next Step
Let's say that the application has to perform multiple operations in response to an event. By combining them all with the same Lambda, the code will have to check for every operation separately.
If you're trying to keep your Lambda idempotent, should it be redone?
Remember that this can cause severe headaches. It would help if you learned the difference between monolithic applications and the Step Function example we've mentioned. In a monolithic application, the application itself can become responsible for forcing retries because it's capable of waiting between them, and that's something that isn't possible in Serverless.
However, with Step Functions, you're able to run every operation on separate Lambda. In addition, you're able to define suitable transitions between them for each specific case. You can also control the retries' behavior -- their delay duration as well as their number. That way, you'll quickly adjust it to be the most suitable one for your particular case. You'll even disable it when you believe that's the right step to take. Even if needed by a single Lambda, creating a step machine is possibly the most straightforward solution for disabling unwanted retry behavior.
How to Implement Step Functions to Lambda?
As you probably know, all available Step Function triggers are quite limited; the only triggers that are available are API Gateway, including a manual execution utilizing SDK.
To successfully deploy this Lambda, you have to utilize the Serverless framework, along with the incredible 'serverless-resources-env' plugin so it could easily pass the state machine ARN. Additionally, you have to ensure that you use 'serverless-pseudo-parameters' and 'serverless-step-functions' so you'd be capable of defining the state machine like it's shown in the below example:

You can see that the artificial choice of implementing an SNS event is made purposely to trigger the state machine, and it's accessible as input by the initial step Lambda. Everything will become idempotent since we deliberately named the state machine's execution as the invoker 'Lambda request ID.' In case a retry happens to this invoker Lambda, AWS will give it the same request ID.
After that, AWS won't be executing the state machine again because it has the same name. In theory, the state machine's execution name is a part of its input as well. Even though this solution is advantageous in numerous case scenarios, you should know that it'll also add a significant complexity overhead, further affecting the system's overall observability and debugging.
Things to Note Regarding Step Functions Error Handling Mechanism
It's essential to comprehend that the Step Function's error handling mechanism is quite different than the AWS Lambda error handling mechanism. For each Task state, a timeout duration placeholder can be set, and in case the Task isn't completed in time, anStates.Timeout error will be generated. This particular timeout is unlimited in a way. Also, in a typical case of a Task that executes a Lambda, the case won't be the same. Lambda's actual timeout duration can be determined solely by its pre-configured value, and it can't get any longer by utilizing this method. Therefore, it's essential to ensure that you've configured the Task timeout so it'd be equal to the timeout of Lambda. The Task's retry behavior is disabled by default, and it can be configured in a certain way.
AWS Lambda Error Processor Sample Application
The Error Processor sample application shows the utilization of AWS Lambda to handle events that are coming from the AWS CloudWatch Logs subscription. Now, CloudWatch Logs will allow you to invoke a Lambda function if a log entry matches a particular pattern. The subscription within this application will monitor a function's log group for all entries with the word ERROR. In response, it'll invoke a processor Lambda function. The processor function will then retrieve the full log-stream and trace data for the request that have caused this error, and it'll store them so it could use them later.

Function code can be found in these files:
- Processor -- processor/index.js
- Random error -- random-error/index.js
You can quickly deploy the sample within a few minutes via AWS CloudFormation and AWS CLI.
Event Structure and Architecture
This sample application utilizes these AWS services:
- Amazon S3 -- which will store application output and deployment artifacts.
- Amazon CloudWatch Logs -- collect logs, but when a log entry matches a filter pattern, it'll also invoke a function.
- AWS X-Ray -- Generates a service map, indexes traces needed for search, and collects trace data.
- AWS Lambda -- Sends all the trace data to the X-Ray, sends logs to CloudWatch Logs, and runs a function code.
A Lambda function will generate errors randomly when found within the application. If CloudWatch Logs detect the word ERROR within the function's logs, it'll provide the processor function with an event for processing.

(CloudWatch Logs message event)
The data has details about the log event when it's decoded. The function will use all these details to successfully identify the log stream and parses the log message so it would obtain the ID of the particular request that has caused this error.

Decoded CloudWatch Logs event data
The processor function will utilize information obtained from the CloudWatch Logs event to download the X-Ray trace and the full log stream for a request that has caused an error. Both will be stored within the AWS S3 bucket. Moreover, to successfully allow the trace time and log stream to finalize, the function will wait for a short period before it starts accessing the data.
AWS X-Ray Instrumentation
The application utilizes AWS X-Ray to t*race function invocations and all the calls that functions make to AWS. X-Ray utilizes the received trace data from functions to create a service map that is of significant help for error identification.* This particular service map showcases the random error function that generates errors for some specific requests. Additionally, it showcases the processor function that calls CloudWatch Logs, Amazon S3, and X-Ray.

These two configured Node.js functions serve active tracing within the template and are instrumented with the AWS X-Ray SDK (Node.js) in code. Along with active tracing, Lambda tags will add a tracing header to all incoming requests, and they'll send a trace with timing details to AWS X-Ray. Moreover, the random error function utilizes X-Ray SDK to record the request ID and the user information within annotations. These annotations are attached to the trace, so you could use them to locate the specific request's trace.

The processor function will obtain the request ID from the CloudWatch Logs event, and it'll utilize the AWS SDK for JavaScript to search X-Ray for that particular request. It also utilizes AWS SDK clients, which are instrumented by the X-Ray SDK to download the log stream and the trace. After that, it'll store them in the output bucket. The X-Ray SDK will record all these calls, and they'll appear within the trace as subsegments.
AWS CloudFormation Template and Additional Resources
The application is implemented within the two Node.js modules, and it's deployed with shell scripts and AWS CloudFormation template. This template will create the processor function, the random error function, and all the following supporting resources:
- Execution role -- is an IAM role that allows function with permission to access other AWS services.
- Primer function -- is an additional function whose objective is to invoke the random error function to create a specific log group.
- Custom resource -- is another AWS CloudFormation custom resource that'll invoke the primer function during deployment, so it would make sure that this particular log group exists.
- CloudWatch Logs subscription -- is a subscription for the log stream triggering the processor function when ERROR word is successfully logged.
- Resource-based policy -- is a specific permission statement on the processor function which allows invocation via CloudWatch Logs.
- Amazon S3 bucket -- is an output storage location (processor function).

If you're trying to work around the limitations of integrating Lambda with CloudFormation successfully, the template will come up with an additional function that'll run during deployments. All Lambda functions will always come with a specific CloudWatch log group that'll store the output from all function executions. Additionally, this log group won't be created until the function has been invoked for the first time.
Creating a subscription that depends on the log group's sole existence, the application needs to utilize a 3^rd^ Lambda function to invoke the random error function. This template also includes the primer function inline code. Each AWS CloudFormation custom resource is capable of invoking it during its deployment. DependsOn properties will ensure that the resource-based policy and the log stream are created before the subscription.
How Dashbird can help handle your AWS Lambda Errors faster and easier?
Serverless architectures fundamentally change how we develop, deploy, and monitor applications. As you now know, services such as AWS Lambda also come with their own limits and idiosyncrasies: limited memory and execution time, retry-behavior, and many others may create side-effects that can easily become monitoring nightmares.
Composing multiple services for compute, data storage, queues, etc. magnifies the problem. The number of potential issues is multiplied by the interactions and dependencies throughout the cloud stack.
Running such architectures at scale is even more challenging. At each level of traffic, we cannot expect the stack will behave homogeneously. Perhaps AWS Lambda functions will scale faster than a database, for example.
Dashbird is designed to provide developers with ways to easily navigate such complex problems while achieving a high degree of visibility and quality in any serverless architecture.
Dashbird was created by serverless developers, for serverless developers to enhance monitoring and operating specifically for AWS services at scale. By continuously collecting and filtering your log data, Dashbird automatically detects all your code exceptions, timeouts, configuration errors, and other anomalies in real-time, and sends you a notification immediately if there's an error or something is about to break.
On top of that, the platform will give you actionable insights based on the AWS Well-Architected Framework to help you improve your infrastructure and make it truly reliable at any scale with the ability to take on added complexity over time.
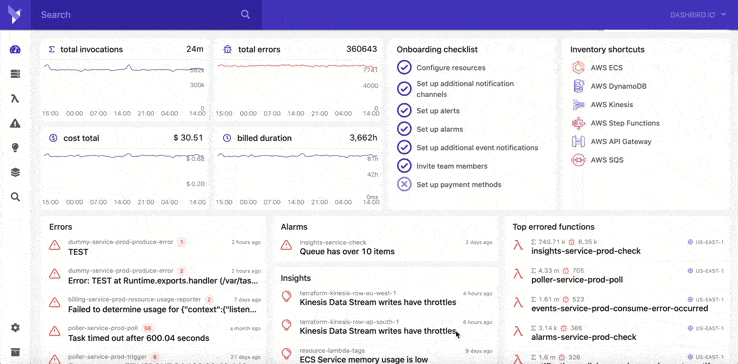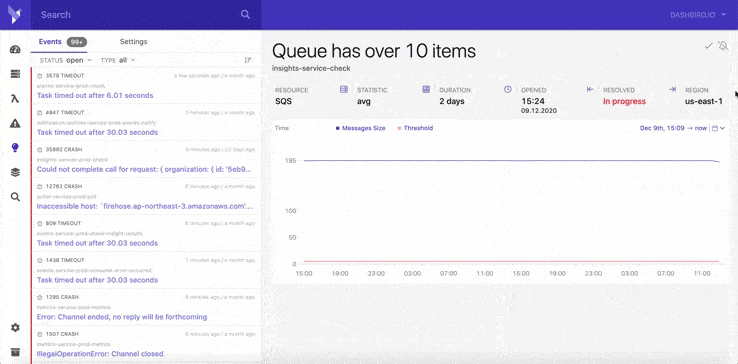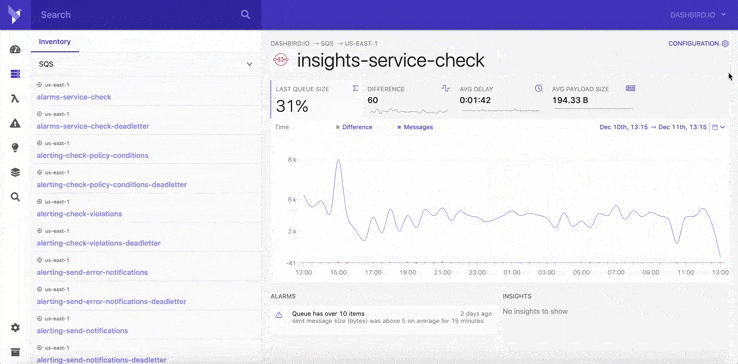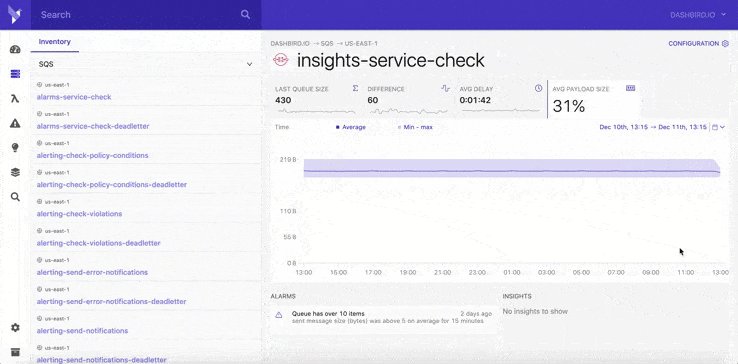
You can give Dashbird a try for free:
- No code changes
- No credit card required
- Simple 2-minute set up
- Get access to all premium features
- Start working with your data and troubleshooting immediately
Wrapping up
AWS Lambda error handling in serverless architecture may seem pretty confusing, but as much as it's hard to comprehend how it can affect your entire system, it's vital to thoroughly understand it. It's important that you know how to manage AWS Lambda retries behavior successfully, and the same goes for Step Functions. Every retry counter field within the context parameter is undoubtedly a feature that's been missing.
Besides the techniques mentioned in this article, there are various other methods that will help with AWS Lambda error handling, and utilizing wrappers is only one example.
The architecture with Step Functions that we've discussed today is quite useful in many cases, and AWS Lambda error handling is one of them. Even though it helps control Lambda retries appropriately, it also encourages the separation of elements, which is an excellent practice within the world of Serverless.

Top comments (0)