At Dataroots, we are constantly exploring the latest advancements in the world of AI. In that regard, were currently developing a Q&A system powered by a Large Language Model (LLM). It has access to a vast array of internal documents, which it can search through at query time to produce accurate and context-aware responses. However, as the document volume grows, so does the challenge of maintaining data quality and consistency. In this blog post, we will delve deeper into this issue and show how we’re resolving it.
The Problem of Data Quality and Contradictions
Handling data quality and consistency for a small number of documents is feasible, but the task quickly scales beyond the realm of manual checks. Current strategies involve knowledge graphs, which offer a formal way to consolidate and visualise data. However, these methods are either too labor-intensive or offer no guarantee about the resulting data quality. Therefore we came up with a different approach, which works in a surprisingly similar way as our general Q&A system. Before we explain how it works, let’s first take a look at the current approaches and their limitations.
Knowledge Graph-Based Approaches
Knowledge graphs consolidate knowledge in a graphical format that is understandable for both humans and computers. Presented with new information, they allow assessing whether it supports, contradicts or extends the information that is already contained in the graph.
We found three different approaches to creating knowledge graphs:
- Manual creation of the knowledge graph. This requires you to describe all entities (like people, projects, events and concepts), as well as the relationships between them. Manual methods are accurate, but very time-consuming and challenging to keep up to date in large, evolving companies.
- Manual creation of a knowledge graph schema and use of an LLM to map free text documents onto the schema. This approach is less labor-intensive than the previous one, but still requires you to have an in-depth understanding of the knowledge contained in your documents. Additionally, it requires you to learn a schema modelling language, such asLinkML, resulting in a steep learning curve. If you're interested in this approach, theOntoGPT repository can be a good starting point.
- Using an LLM for both the schema creation and the free text mapping. This method minimizes manual effort, but lacks guarantees about the quality of the created knowledge graph. You can steer the LLM in the right direction with some prompt engineering, but then you might as well take the time to learn LinkML and create the knowledge graph schema yourself. An example of this approach (although on a different use case) can be found in thisblogpost.
Given the current impediments (lots of manual work or lack of quality guarantees), we decided not to proceed along this research path. Nevertheless, we believe in the potential of integrating knowledge graphs with LLMs. In that regard, it's worth keeping an eye out forNeo4j's efforts to explore the synergies between these two realms.
Our Solution: Ensuring Consistency by Leveraging Retrieval-Augmented Generation
To tackle the challenge of data quality and contradictions, we propose an innovative solution that leverages semantic retrieval and an LLM. Before adding a document to the knowledge base, we first retrieve the most similar documents. We then utilise an LLM to validate the consistency of the new document with the retrieved documents. This process ensures that only reliable and coherent information is added to the knowledge base, while documents with inconsistencies and contradictions are set aside for review.
First Things First: Knowledge Base Creation
To understand how our solution works in practice, it is useful to first grasp the process we follow when creating our knowledge base:
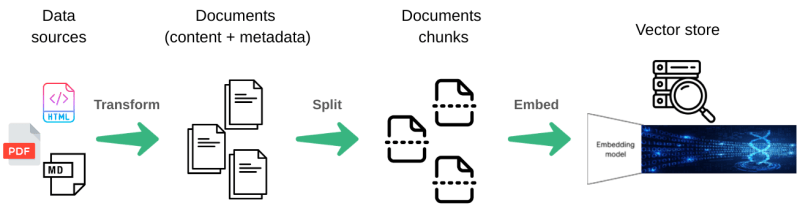
Initially, we extract the text and relevant metadata from various file formats, such as PDF and HTML. Next, we break down each document into smaller chunks, with a maximum size of 1000 characters per chunk. This approach ensures that each chunk contains a limited amount of information. We then convert the text within each chunk into vector representations using embedding techniques. These vector representations are stored in a dedicated vector store, which optimises storage requirements and facilitates efficient retrieval of semantically similar chunks.
Ensuring Data Consistency: Comparing New Chunks with Existing Documents
When it comes to incorporating new information into the vector store while maintaining data consistency, we employ semantic retrieval and an LLM.
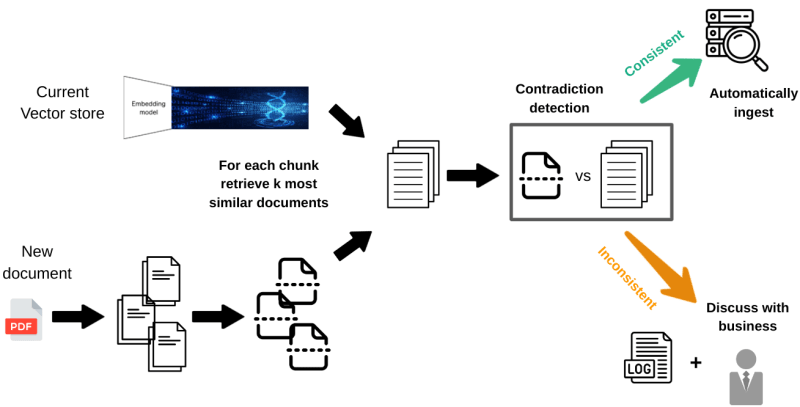
Similar to the initial knowledge base creation, the new documents are divided into smaller chunks. For each chunk, we conduct a search within the existing vector store to identify the most similar documents. By comparing the new document chunk with the retrieved documents, we assess whether the information aligns or contradicts the existing data. If there are no inconsistencies, the chunk is added to the knowledge base. However, if contradictions are identified, the document is temporarily withheld, and the inconsistencies are logged for further analysis.
To identify conflicts and inconsistencies between document chunks, different approaches are possible. We could employ knowledge graphs as we outlined before, but we chose to utilise the capabilities of an LLM, specifically GPT-3.5. We constructed a prompt that instructs GPT-3.5 to compare the new document chunks with the existing documents and identify any contradictions or inconsistencies. Roughly speaking, this prompt looks as follows:

The advanced language understanding capabilities of GPT-3.5 allow us to effectively assess the harmony between the new and existing information, thereby safeguarding the overall data consistency within the knowledge base.
Challenges and Future Considerations
- Distinguishing contradictions from new information : Crafting the prompt carefully is essential for reliable results, as we experienced ourselves during our experiments. We observed that the model was constantly classifying new information, of which nothing was mentioned in the retrieved documents, as inconsistencies. However, new information is something else than contradicting information. Therefore, we had to precisely explain the difference to the model.
- Chunk size : Determining the optimal size of document chunks is a balancing act. Smaller chunks offer the advantage of limited information within each, facilitating highly relevant document retrieval and simplifying the process of identifying contradictions. However, they also increase the computational cost as each chunk requires an LLM call. On the other hand, larger chunks reduce the computational cost but may risk missing the most relevant documents for certain parts of the chunk.
- Number of relevant documents: Balancing the retrieval of relevant documents with the constraints of the LLM's context window is a crucial consideration. A small number of documents guarantees that all information fits within the context window, but poses the risk of missing some relevant documents. This implies the possibility of adding documents to the vector store that may actually contain contradictory information. Conversely, retrieving too many documents may exceed the context window, limiting the comprehensive analysis. Note that the number of documents we can retrieve is also tightly coupled to the size of the chunks in the vector store.
- Consistent handling of all document chunks : Dividing documents into smaller chunks allows for granular analysis, but it introduces the challenge of managing consistency across these chunks. In some cases, a document may consist of multiple chunks, and while some chunks may align with the vector store, others may contain contradictions. Deciding whether to add the consistent chunks immediately or wait until all chunks are consistent is an important (use case specific) consideration, which we currently don't address.
Conclusion
Ensuring data quality and consistency within a knowledge base is a challenge which has not received a lot of attention in the research community. While typical approaches involve knowledge graphs, we believe to be the first to leverage semantic retrieval and LLMs. Our approach allows us to effectively identify and address inconsistencies and contradictions. While challenges remain in defining contradictions versus new information, determining optimal chunk size, choosing the number of relevant documents, and handling consistency across document chunks, these obstacles pave the way for future research and development. By continuously refining our approaches and leveraging the power of Large Language Models, we strive to enhance data quality and consistency in AI applications, opening up new possibilities for Q&A systems and beyond.
If you're excited to try out our contradiction detection method, stay tune!
You might also like
[
Data preparation for a Q&A application powered by LLMs - Andrea Benevenuta
Large Language Models (LLMs) have recently emerged as a groundbreaking advancement in the field of natural language processing. These models are designed to comprehend and generate human-like text, exhibiting a remarkable ability to understand context, grammar, and even nuances in language. One of…


](https://dataroots.io/research/contributions/aiden-data-ingestion/?ref=dataroots.ghost.io)

Top comments (0)