
What makes NodeJS distinguished from any other programming platforms is how it handles I/O. We hear this all the time when NodeJS is introduced by someone saying “A non-blocking, event-driven platform based on google’s v8 javascript engine”. What do all these mean? What do ‘non-blocking’ and ‘event-driven’ mean? Answer for all these lies at the heart of NodeJS, the Event Loop. In this series of posts, I’m going to describe what event loop is, how it works, how it affects our applications, how to get the best out of it and much more. Why series of posts instead of one? Well, it will be a really long post and I will definitely miss certain things, therefore I’m writing a series of posts about this. In this first post, I will describe how NodeJS works, how it accesses I/O and how it can work with different platforms, etc.
Post Series Roadmap
- Event Loop and the Big Picture (This article)
- Timers, Immediates and Next Ticks
- Promises, Next-Ticks, and Immediates
- Handling I/O
- Event Loop Best Practices
- New changes to timers and microtasks in Node v11
Reactor Pattern
NodeJS works in an event-driven model that involves an Event Demultiplexer and an Event Queue. All I/O requests will eventually generate an event of completion/failure or any other trigger, which is called an Event. These events are processed according to the following algorithm.
- Event demultiplexer receives I/O requests and delegates these requests to the appropriate hardware.
- Once the I/O request is processed (e.g, data from a file is available to be read, data from a socket is available to be read, etc.), event demultiplexer will then add the registered callback handler for the particular action in a queue to be processed. These callbacks are called events and the queue where events are added is called the Event Queue.
- When events are available to be processed in the event queue, they are executed sequentially in the order they were received until the queue is empty.
- If there are no events in the event queue or the Event Demultiplexer has no pending requests, the program will complete. Otherwise, the process will continue from the first step.
The program which orchestrates this entire mechanism is called the Event Loop.

Event Loop is a single-threaded and semi-infinite loop. The reason why this is called a semi-infinite loop is that this actually quits at some point when there is no more work to be done. In the developer’s perspective, this is where the program exits.
Note: Don’t get yourself confused with the event loop and the NodeJS Event Emitter. Event Emitter is totally a different concept than this mechanism. In a later post, I'll explain the difference between how they work in detail.
The above diagram is a high-level overview of how NodeJS work and displays the main components of a design pattern called the Reactor Pattern. But this is much more complex than this. So how complex is this?
Event demultiplexer is not a single component that does all the types of I/O in all the OS platforms.
The Event queue is not a single queue as displayed here where all the types of events are queued in and dequeued from. And I/O is not the only event type that is getting queued.
So let’s dig deep.
Event Demultiplexer
Event Demultiplexer is not a component which exists in the real world, but an abstract concept in the reactor pattern. In the real world, event demultiplexer has been implemented in different systems in different names such as epoll on Linux, kqueue on BSD systems (MacOS), event ports in Solaris, IOCP (Input Output Completion Port) in Windows, etc. NodeJS consumes the low-level non-blocking, asynchronous hardware I/O functionalities provided by these implementations.
Complexities in File I/O
But the confusing fact is, not all the types of I/O can be performed using these implementations. Even on the same OS platform, there are complexities in supporting different types of I/O. Typically, network I/O can be performed in a non-blocking way using these epoll, kqueue, event ports and IOCP, but the file I/O is much more complex. Certain systems, such as Linux does not support complete asynchrony for file system access. And there are limitations in file system event notifications/signaling with kqueue in MacOS systems (you can read more about these complications here). It is very complex/nearly impossible to address all these file system complexities in order to provide complete asynchrony.
Complexities in DNS
Similar to the file I/O, certain DNS functions provided by Node API also have certain complexities. Since NodeJS DNS functions such as dns.lookup accesses system configuration files such as nsswitch.conf,resolv.conf and /etc/hosts , file system complexities described above are also applicable to dns.resolve function.
The solution?
Therefore, a thread pool has been introduced to support I/O functions which cannot be directly addressed by hardware asynchronous I/O utils such as epoll/kqueue/event ports or IOCP. Now we know that not all the I/O functions happen in the thread pool. NodeJS has done its best to do most of the I/O using non-blocking and asynchronous hardware I/O, but for the I/O types which blocks or are complex to address, it uses the thread pool.
Gathering All Together
As we saw, in the real world it is really difficult to support all the different types of I/O (file I/O, network I/O, DNS, etc.) in all the different types of OS platforms. Some I/O can be performed using native hardware implementations while preserving complete asynchrony, and there are certain I/O types which should be performed in the thread pool so that the asynchronous nature can be guaranteed.
A common misconception among the developers about Node is that Node performs all the I/O in the thread pool.
To govern this entire process while supporting cross-platform I/O, there should be an abstraction layer that encapsulates these inter-platform and intra-platform complexities and expose a generalized API for the upper layers of Node.
So who does that? Please welcome….

From the official libuv docs,
libuv is cross-platform support library that was originally written for NodeJS. It’s designed around the event-driven asynchronous I/O model.
The library provides much more than a simple abstraction over different I/O polling mechanisms: ‘handles’ and ‘streams’ provide a high-level abstraction for sockets and other entities; cross-platform file I/O and threading functionality is also provided, amongst other things.
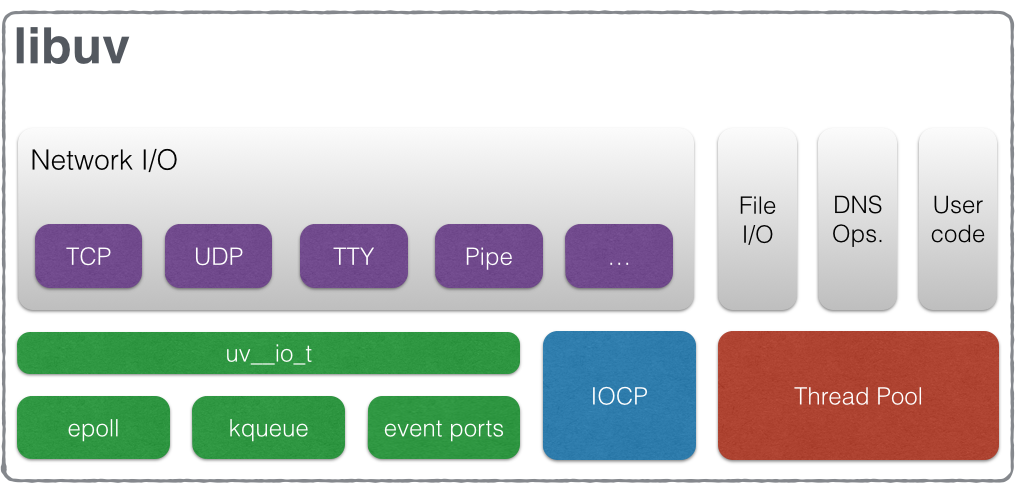
Now let’s see how libuv is composed. The following diagram is from the official libuv docs and describes how different types of I/O have been handled while exposing a generalized API.

Source: http://docs.libuv.org/en/v1.x/_images/architecture.png
Now we know that the Event Demultiplexer, is not an atomic entity, but a collection of an I/O processing APIs abstracted by the Libuv and exposed to the upper layers of NodeJS. It’s not only the event demultiplexer that libuv provides for Node. Libuv provides the entire event loop functionality to NodeJS including the event queuing mechanism.
Now let’s look at the Event Queue.
Event Queue
The event queue is supposed to be a data structure where all the events are getting enqueued and processed by the event loop sequentially until the queue is empty. But how this happens in Node is entirely different from how the abstract reactor pattern describes it. So how it differs?
There are more than one queues in NodeJS where different types of events getting queued in their own queue.
After processing one phase and before moving to the next phase, the event loop will process two intermediate queues until no items are remaining in the intermediate queues.
So how many queues are there? what are the intermediate queues?
There are 4 main types of queues that are processed by the native libuv event loop.
- Expired timers and intervals queue — consists of callbacks of expired timers added using
setTimeoutor interval functions added usingsetInterval. - IO Events Queue — Completed IO events
- Immediates Queue — Callbacks added using
setImmediatefunction - Close Handlers Queue— Any
closeevent handlers.
Please note that although I mention all these to be “Queues” for simplicity, some of them are actually different types of data structures (e.g, timers are stored in a min-heap)
Besides these 4 main queues, there are additionally 2 interesting queues which I previously mentioned as ‘intermediate queues’ and are processed by Node. Although these queues are not part of libuv itself but are parts NodeJS. They are,
- Next Ticks Queue — Callbacks added using
process.nextTickfunction - Other Microtasks Queue — Includes other microtasks such as resolved promise callbacks
How does it work?
As you can see in the following diagram, Node starts the event loop by checking for any expired timers in the timers queue, and go through each queue in each step while maintaining a reference counter of total items to be processed. After processing the close handlers queue, if there are no items to be processed in any queue and there are no pending operations, the loop will exit. The processing of each queue in the event loop can be considered as a phase of the event loop.
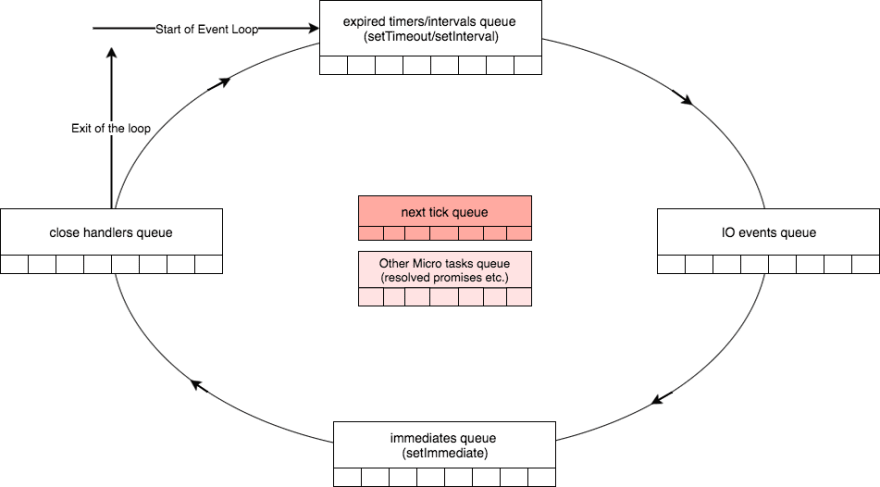
What’s interesting about the intermediate queues depicted in red is that, as soon as one phase is complete event loop will check these two intermediate queues for any available items. If there are any items available in the intermediate queues, the event loop will immediately start processing them until the two immediate queues are emptied. Once they are empty, the event loop will continue to the next phase.
E.g, The event loop is currently processing the immediates queue which has 5 handlers to be processed. Meanwhile, two handlers are added to the next tick queue. Once the event loop completes 5 handlers in the immediates queue, event loop will detect that there are two items to be processed in the next tick queue before moving to the close handlers queue. It will then execute all the handlers in the next tick queue and then will move to process the close handlers queue.
Next tick queue vs Other Microtasks
Next tick queue has even higher priority over the Other Micro tasks queue. Although, they both are processed in between two phases of the event loop when libuv communicates back to higher layers of Node at the end of a phase. You’ll notice that I have shown the next tick queue in dark red which implies that the next tick queue is emptied before starting to process resolved promises in the microtasks queue.
Priority for next tick queue over resolved promises is only applicable for the native JS promises provided by v8. If you are using a library such as
qorbluebird, you will observe an entirely different result because they predate native promises and has different semantics.
qandbluebirdalso differ in their own way of handling resolved promises which I will explain in a later blog post.
The convention of these so-called ‘intermediate’ queues introduces a new problem, IO starvation. Extensively filling up the next tick queue using process.nextTick function will force the event loop to keep processing the next tick queue indefinitely without moving forward. This will cause IO starvation because the event loop cannot continue without emptying the next tick queue.
To prevent this, there used to be a maximum limit for the next tick queue which can be set using
process.maxTickDepthparameter, but it has been removed since NodeJS v0.12 for some reason.
I will describe each of these queues in-depth in later posts with examples.
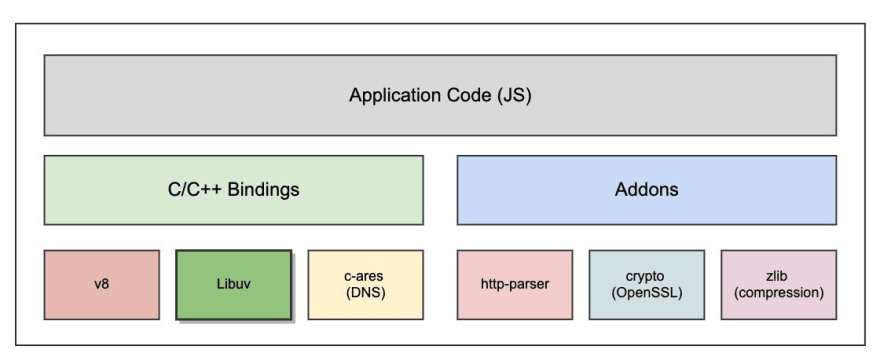
Finally, now you know what event loop is, how it is implemented and how Node handles asynchronous I/O. Let’s now look at where Libuv is in the NodeJS architecture.
This article is the first post of my series on NodeJS Event Loop originally posted on medium. You can find the originally posted article below and navigation links to the other articles in the series:

 blog.insiderattack.net
blog.insiderattack.net
References:
- NodeJS API Docs https://nodejs.org/api
- NodeJS Github https://github.com/nodejs/node/
- Libuv Official Documentation http://docs.libuv.org/
- NodeJS Design Patterns https://www.packtpub.com/mapt/book/web-development/9781783287314
- Everything You Need to Know About Node.js Event Loop — Bert Belder, IBM https://www.youtube.com/watch?v=PNa9OMajw9w
- Node’s Event Loop From the Inside Out by Sam Roberts, IBM https://www.youtube.com/watch?v=P9csgxBgaZ8
- asynchronous disk I/O http://blog.libtorrent.org/2012/10/asynchronous-disk-io/
- Event loop in JavaScript https://acemood.github.io/2016/02/01/event-loop-in-javascript/

{kind=link}
Top comments (0)