
TL;DR
- Don't use regular expressions for parsing
- Parser combinators are a way to construct composable computations with higher-order functions
- Examples:
many1(digit1)alt((tag("hello"), tag("sveiki")))-
pair(description, preceded(space0, tags))
- Parser combinators are easy to use to get results quickly
- They are sufficient for 99% of pragmatic uses, falling short only if your library's sole purpose is parsing
Role of parsing in computing
Data processing is a pillar of computing. To run an algorithm, one must first build up some data structures in memory. The way to populate data structures is to get some raw data and load it into memory. Data scientists work with raw data, clean it and create well-formatted data sets. Programming language designers tokenise source code files and then parse those into abstract syntax trees. Web-scraper author navigates scraped HTML and extracts values of interest.
Informally, each of these steps can be called "parsing". This post talks about how to do complete, composable and correct parsing in anger. What do we mean by this?
- Parsing in anger considers the problem of data transformation pragmatically. A theoretically optimal solution is not required. Instead, the goal is to write a correct parser as quickly as possible.
- Composable parsing means that the resulting parser may consist of "smaller" components. It can itself be later on used as a component in "bigger" parsers.
- Complete parsing means that the input shall be consumed entirely. If the input can have any deviations or errors, its author shall encode them in the resulting parser.
So how do we achieve it? Let's first talk about how to not do it.
Forget about regular expressions
Thanks to the popularity of now perished Perl programming language, a whole generation of computer programmers was making futile attempts to parse non-regular languages with regular expressions. Regular expressions are no more than encodings of finite-state automata.
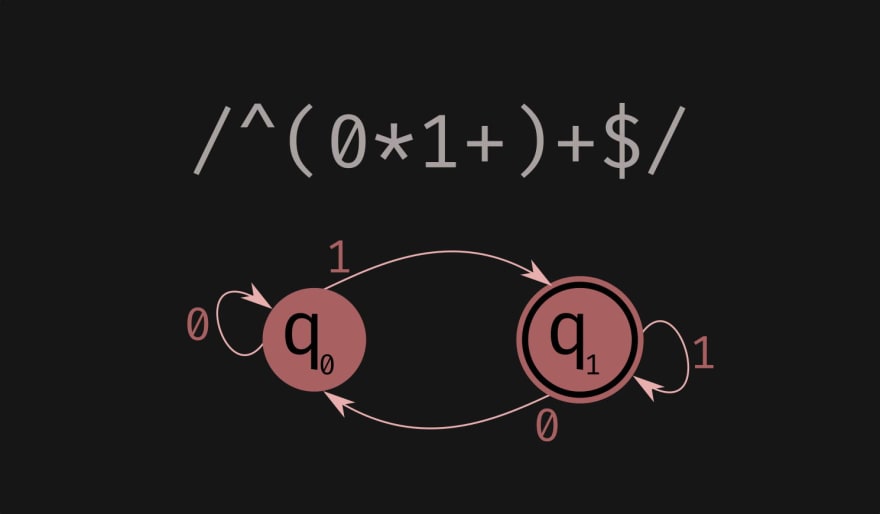 Items over arrows are characters of {0, 1} alphabet. Circles are states, q1 is "accepting state". Arrows denote state transitions.
Items over arrows are characters of {0, 1} alphabet. Circles are states, q1 is "accepting state". Arrows denote state transitions.
Non-deterministic finite-state automata can rather elegantly accept many non-trivial languages. Classical example is that no regular expression exists that accepts strings of form "ab", "aabb", "aaabbb", ... Equivalently, one can't solve the matching parentheses problem with a regular expression. The simplest stack machine is needed for that.
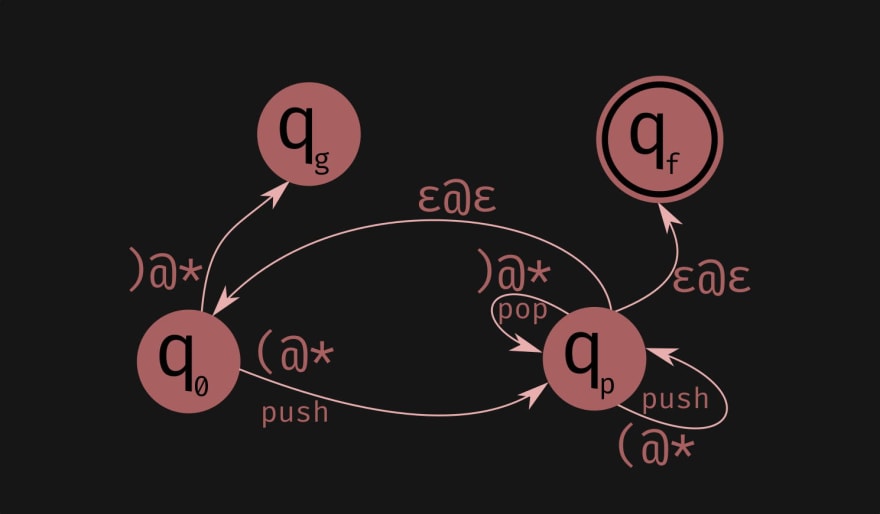 Stack automaton can be in several states at once. A state with no transitions "fizzles" on any input.
Stack automaton can be in several states at once. A state with no transitions "fizzles" on any input. (@\* matches character '(' with any stack state. ε@ε matches instantaneously as the automaton gets to state p, but only if the stack is empty. The best introductory book for those interested in formal languages.
Thus, regular expressions are nowhere close to providing enough facilities to work with context-free grammars. But they may be sufficiently powerful to clean data or extract some values, so why are we saying you shouldn't use them ever? Practicality reasons!
Let's take an example from some Regex Cookbook post (medium-paywalled link). This way we know it's an actual approach used in the industry. Here is one of the regular expressions author offers:
^(((h..ps?|f.p):\/\/)?(?:([\w\-\.])+(\[?\.\]?)([\w]){2,4}|(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\[?\.\]?){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)))*([\w\/+=%&_\.~?\-]*)$
Many can superficially understand what is going on here. This regex seemingly has something to do with links, but even when we resort to automated explanation, things don't get much clearer. Well, according to the author, this regex is supposed to detect "defanged" URLs. Now let's see all ways in which it and any other sufficiently large regular expression fail.
- It is wrong: it doesn't match
https://ctflearn.com/(notice zero-width spaces). - It requires external tokenising, so no plug-and-play: it doesn't match
␣https://ctflearn.com/(notice leading space). - External tokenisation is specific to this expression: it doesn't match
https://ctflearn.com,(notice trailing comma). - It's impossible to fix it: matching optional characters around each printable character would turn it from a large and poorly readable piece of code into a huge and completely unreadable one. Your brain wouldn't even be able to guess
h..psandf.pbits. - It can't be used to extract values. Regexps don't "parse data into data structures". Rather they accept or decline strings. Thus, additional post-processing is required to make use of their output.
Regular expressions have intrinsic problems. To us, it means that only short expressions should be used. The author uses them exclusively with grep, find, and vim.
These days, gladly, a better parsing methodology becomes mainstream with working libraries in all the popular languages. As you can guess from the title, it's called "parser combinators".
Step-by-step guide to composable parsing
In the spirit of our previous blogs, let's solve some practical task. Consider you have to write an interactive TODO application, the pinnacle of practicality. It specifies the following commands:
-
add ${some word}* ${some #hashtag}*(appends item ID) -
done ${some item ID}(marks entry at item ID as resolved) -
search ${some word or some #hashtag}+(searches across entries, returns a list of matching item IDs)
Let's first define how will we represent parsed data, omitting the boring bits:
pub enum Entry {
Done (Index),
Add (Description, Vec<Tag>),
Search (SearchParams),
}
Now let's use the nom library to enjoy expressive and declarative parsing. It has or used to have macro API and function API. Since in v5 of the library macro API was very glitchy, we shall use function API, which we have tested with v6.
We will be parsing the commands line by line. Begin with declaring the top-level parse for a line and meet your first parser combinator: alt.
pub fn command(input: &str)
-> IResult<&str, Entry> { /* A */
alt((done, add, search))(input) /* B */
}
In (A) is declared that our function command is a parser.IResult captures parsed type (in our case, str&) and output data structure (in our case, Entry).
In (B) we combine three parsers: add, done, and search with nom::branch::alt combinator. It attempts to apply each of these parsers starting from the leftmost until one succeeds.
Now, let's have a look at the simplest parser out of the three:
fn done(input: &str) -> IResult<&str, Entry> {
let (rest, value) = preceded( /* A */
pair(tag("done"), ws), /* B */
many1(digit1) /* C */
)(input)?;
Ok((
rest,
Entry::Done( /* D */
Index::new( vec_to_u64(value) )
)
))
}
The first combinator we see straight away is preceded. It forgets parse (B) and keeps only the output of (C).(B) still will consume input, however! Generally speaking, it combines two computations into a composition that runs both of them, returning what the second one returns. It is not the same as just running them in a sequence because here we build up a computation, but we will run it later on!
Interestingly, if we were writing Haskell we wouldn't find "preceded" combinator in our parser library. The reason is that what we described in the previous paragraph is called "right applicative arrow", or, as was coined during Ben Clifford's wonderful talk "right sparrow":
λ> :t (*>)
(*>) :: Applicative f => f a -> f b -> f b
The other two combinators are pretty self-explanatory.pair combines parsers into a sequence, with the ws parser being a parser that consumes single whitespace. Here is a naive definition of ws: one_of(" \t").many1 repeats a digit1 parse at least one time to succeed. digit1 is implemented in nom itself.
Now let's solidify the understanding of how to make sure that our parsers can be used by others.
We have already discussed that to achieve that, we need to return IResult. Now it's time to remember that it's still a "Result" type, so its constructors are still Err and Ok:
-
Errvariant of Result is constructed via the?modifier, that passes any potential error arising in parse(A)through. -
Okvariant of Result is constructed in(D)by transformingmany1output (which is a vector of digits) into an unsigned 64-bit integer. It's done withvec_to_u64function, which is omitted for brevity.
The shape of Ok value for IResult<in, out> is Ok((rest: in, value: out)). Here rest is the remaining input to be parsed, and value is the output result of the parser. You can see that preceded parse in (A) followed the very same pattern.
Here are more advanced parsers, that should solidify your intuition about how to use parser combinators in anger:
fn add(input: &str) -> IResult<&str, Entry> {
let (rest, (d, ts)) = preceded( /* B */
pair(tag("add"), ws),
pair(description, preceded(space0, tags)) /* A */
)(input)?;
Ok( (
rest,
Entry::Add( Description::new(&d), ts )
) )
}
fn search(input: &str) -> IResult<&str, Entry> {
let (rest, mash) = preceded(
pair(tag("search"), ws),
separated_list(
tag(" "),
alt((tag_contents, search_word)) /* C */
)
)(input)?;
Ok((rest, mash_to_entry(mash)))
}
fn mash_to_entry(mash: Vec<SearchWordOrTag>) -> Entry /* D */
{ /* ... */ }
Parsing with combinators is so self-descriptive, it's hard to find things that need to be clarified, but here are a couple of highlights:
- Repeat
precededto focus on the data you need to parse out, see(A)and binding in(B). - Sometimes, you have to parse heterogeneous lists of things. The best way to do that in our experience is to create a separate data type to enclose this heterogeneity (
SearchWordOrTag, in our case) and then useseparated_listparser overaltof options, like in(C). Finally, when you have a vector of matches, you can fold it into a neater data structure as needed by using a conversion function (see(D)).
This should be enough guidance for you to start getting comfortable with this amazing combinator-based parsing methodology. Here are some parting thoughts:
- Pay close attention to whitespaces, which can be a little tricky, especially since we're not aware of the automatic tokenisation option in nom.
- Take a look at choosing a combinator documentation page for the version of nom you are using (NB! entries in this table are pointing to macro versions of combinators rather than function versions).
- If you so choose, you can check out code truly written in anger, which inspired the snippets in this blog post. The code is authored by Chris Höppner and Jonn Mostovoy.
If parsing is not your product or the main purpose of your library, odds are, parser combinators shall be sufficiently expressive and sufficiently performant for your tasks. We hope you liked this post and happy parsing!
If you have any questions, you can reach out to Jonn and Pola directly. Start the conversation in the comments of the mirrors of this article on Dev.to and Medium.

Top comments (0)