
This deep dive into InsightEdge shows how it can be used for predictive analytics at scale, aggregating IoT data so it can be used for decision making.
The digital universe is estimated to see a 50-fold data increase in the 2010-2020 decade. Gartner expects 6.4 billion connected things will be in use worldwide in 2018, up 30 percent from 2015, and will reach 20.8 billion by 2020.
In every respect, Big Data is bigger than you can imagine, but moreover – it’s accelerating.
When it comes to the IoT, this involves an increasing number of complex projects encompassing hundreds of suppliers, devices, and technologies. Michele Pelino and Frank E. Gillett from Forrester predict fleet management in transportation, security and surveillance applications in government, inventory and warehouse management applications in retail and industrial asset management in primary manufacturing will be the hottest areas for IoT growth.
The impact of increasing the amount of data is the increase in velocity in which we have to ingest that data, perform data analysis and filter the relevant information. With a stream of millions of events per second coming in from IoT devices, organizations must equip themselves with flexible, comprehensive and cost-effective solutions for their IoT needs.
At GigaSpaces, we’ve come to a realization that the solution to this growing need is not radically changing an existing architecture, but rather extending it through in-memory computing to enable fast analytics and control against fast data. The combination of low latency streaming analytics, along with transactional workflow triggers, enables acting on IoT data in the moment. This includes predictive maintenance and anomaly detection again millions of sensor data points.
InsightEdge Fuels Magic’s Predictive Engines for All IoT Needs
The Challenge
Magic Software Enterprises, a global provider of enterprise-grade application development and business process integration software solutions and a vendor of a broad range of software and IT services, has been leveraging GigaSpaces XAP for years.
When Magic came out with their xpi Integration Platform, they were looking for a data aggregation solution to form an IoT Hub in front of Magic xpi. This solution needed to be flexible enough to meet a variety of applications regardless of the data and velocity requirements.
In the age of fast data, the xpi platform, although proving operational interoperability, it still faces the challenge of many existing platforms that are not ready to handle fast data ingestion scenarios. Magic was looking for a POC which could be implemented as quickly as possible while delivering fast results.
The Solution
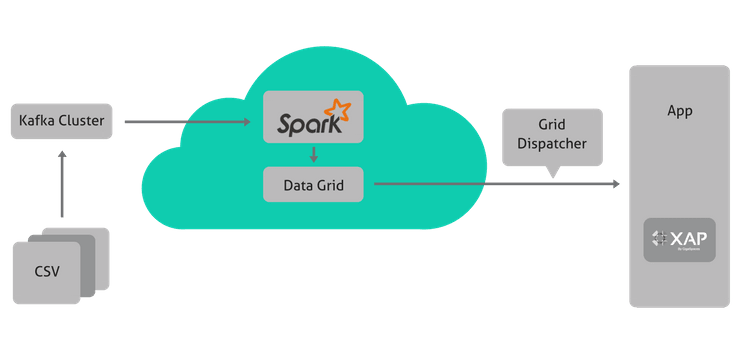
InsightEdge was the perfect choice to help the Magic IoT solutions handle all the difficult data transformation challenges, allowing customers to concentrate on designing the best processes and flows to support their business goals. The solution needed to be flexible and open to any type of data input, regardless of the type and structure of the data, the velocity, running in-memory. That’s where we came in. During our meeting, we suggested a simple solution based on Kafka and InsightEdge to help facilitate data velocity and variety in IoT use cases.
By integrating InsightEdge in-memory streaming technology, incoming sensor data is analyzed through a multitude of predefined filters and rules and aggregated by InsightEdge. The aggregated data is easily compared, correlated and merged and is transferred in batches to Magic xpi, where a prediction engine is first to predict when IoT equipment failure might occur and to prevent the occurrence of the failure by performing maintenance. Monitoring for future failure allows maintenance to be planned before the failure occurs.

Benefits
InsightEdge provides Magic with a few key benefits:
- Performance: Ability to ingest fast data from multiple IoT sensors.
- Data Aggregation: InsightEdge is able to handle streaming sensor data at high throughput and aggregate it in time windows that are relevant to each sensor’s notification rhythm.
- Fast Data Storage: The streamed data then becomes structured into a semantically-rich data model that can be queried from any application.
- Simplification of Big Data Architecture: InsightEdge easily enables Magic to combine the power of Apache Spark and Fast Data analytics without the need for large-scale data source integration or data replication (ETL).
Results
Using InsightEdge, Magic is able to provide its customers with fast data streaming and the ability to perform aggregations and calculation capabilities on the in-memory grid. Using the XAP data grid makes the streaming process it that much faster, hence eliminating the need for Hadoop.
InsightEdge facilities Magic’s customer needs for the IoT deployments with predictive manufacturing and maintenance, enabling them to receive real-time, fast, data-driven events from their systems.
InsightEdge Use Case: Car Telemetry Ingestion and Data Prediction Using Magic’s xpi
A live InsightEdge use case is Car Telemetry Ingestion and Data Prediction using Magic’s xpi. In the case of car telemetry, it is very hard to predict in advance what data will be useful. In the case of data prediction, we need to think about not only device telemetry but also diagnostic telemetry.
Predictive car maintenance requires car telemetry ingestion and data prediction. Magic’s solution stack needed one more component in the architecture to be fully compliant with fast data and scalable scenarios, assured innovation was needed and the correct puzzle piece to fit.
In this use case, we will cover post-data-collection (assuming we have CSV files but could have been streaming all the same) and up until the data sent to Magic’s xpi Integration Platform.
How We Built It
Kafka
Apache Kafka is a distributed streaming platform, or a reliable message broker on steroids but not limited to just that. It enables building real-time streaming data pipelines that reliably get data between systems or applications and building real-time streaming applications that transform or react to the streams of data.

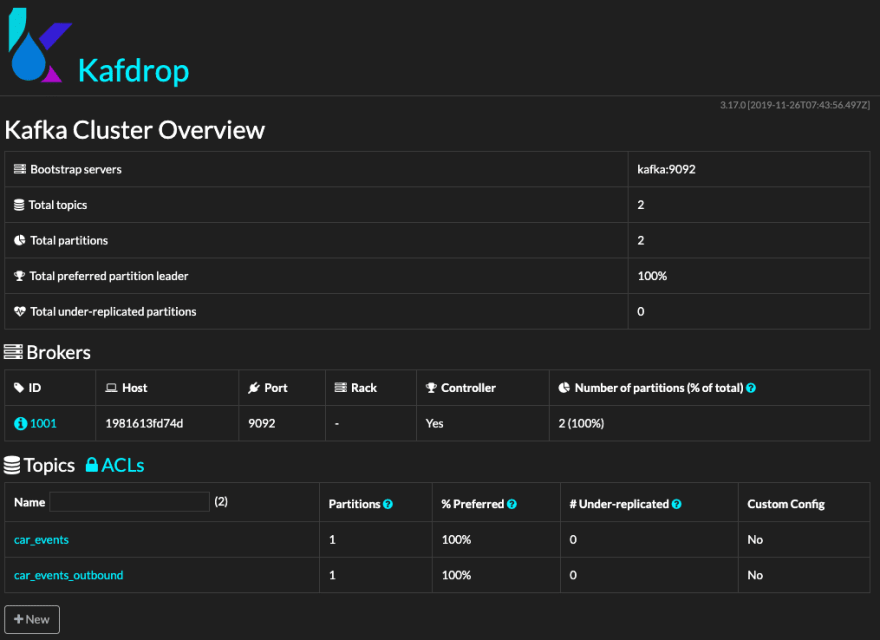
Kafdrop
Kafdrop is a simple UI monitoring tool for message brokers. In this case, we will use it for Kafka to moderate the topics and messages content during development. Download the Kafdrop Docker image and run using the instructions on DockerHub.
InsightEdge
InsightEdge is a high-performance Spark distribution designed for low latency workloads and extreme analytics processing in one unified solution. With a robust analytics capacity and virtually no latency, InsightEdge provides immediate results.
GigaSpaces’ Spark distribution eliminates dependency on Hadoop Distributed File System (HDFS) so as to break through the embedded performance “glass ceiling” of the “stranded” Spark offering. To this, GigaSpaces has added enterprise-grade features, such as high-availability and security. The result is a hardened Spark distribution that is thirty times faster than standard Spark.
Download InsightEdge here. No installation needed, simply unzip the file to the desired location. (Note: Not compatible with Windows)
Code Deep-Dive
Admin Work
First, we need to start Kafka and InsightEdge, so we’ll use the following two scripts:
1. start-kafka.sh

#!/usr/bin/env bash
echo "KAFKA_HOME=$KAFKA_HOME"
mkdir $KAFKA_HOME/logs
export ZLOGS=$KAFKA_HOME/logs/zookeeper.log
echo "Starting ZooKeeper, logs: $ZLOGS"
nohup $KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties > $ZLOGS 2>&1 &
echo "Waiting 10 seconds..."
sleep 10
export KLOGS=$KAFKA_HOME/logs/kafka.log
echo "Starting Kafka, logs: $KLOGS"
nohup $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties > $KLOGS 2>&1 &
echo "Waiting 15 seconds..."
sleep 15
echo "Creating Kafka topics for car_events"
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic car_events
2. start-insightedge.sh
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
$INSIGHTEDGE_HOME/sbin/insightedge.sh --mode demo
$INSIGHTEDGE_HOME/datagrid/bin/gs-webui.sh > /dev/null 2>&1 &
3. Next, we’ll start Kafdrop so we can have a UI on our Kafka broker. Launch Kafdrop using Docker:
docker run -it -p 9000:9000 \
-e KAFKA_BROKERCONNECT=<host:port> \
obsidiandynamics/kafdrop
Browse to the local instance to make sure it works link: http://localhost:9000.
4. Last but not least, we need to start an HTTP server stub (to later be replaced with some other integration endpoint), call the start-http-server.sh:
#!/usr/bin/env bash
# a one-line HTTP server ;)
while true ; do nc -l -p 80 -c 'echo -e "HTTP/1.1 200 OK\n\n Hello, World $(date)"'; done
Model Class
Now we’ll have to build our model, so let’s see how it should look like:
package com.magic.insightedge.model
import java.util
import java.util.Date
import org.insightedge.scala.annotation.SpaceId
import play.api.libs.json._
import play.api.libs.json. {
Json,
Writes
}
import scala.beans.BeanProperty
import org.insightedge.scala.annotation._
import scala.beans. {
BeanProperty,
BooleanBeanProperty
}
abstract class MagicEvent(ID: Int) {
def this() = this(-1)
}
case class CarEvent(
@BeanProperty @SpaceId
var ID: Int,
@BeanProperty
var COL1: String,
@BeanProperty
var COL2: Double,
@BooleanBeanProperty
var IsSentByHttp: Boolean
) extends MagicEvent() {
def this() = this(-1, null, -1.0, false)
}
Next, we write our event class (to handle incoming events):
package com.magic.events
import java.io.Serializable
import play.api.libs.json. {
Json,
Writes
}
object Events {
case class CarEvent(ID: Int,
COL1: String,
COL2: Double,
IsSentByHttp: Boolean)
implicit val CarEventWrites = new Writes[CarEvent] {
def writes(carEvent: CarEvent) = Json.obj(
"ID" - > carEvent.ID,
"COL1" - > carEvent.COL1,
"COL2" - > carEvent.COL2,
"IsSentByHttp" - > carEvent.IsSentByHttp
)
}
}
Code
Now that we have our Model and Event-Model we can write the code we want to deploy to Spark (which will actually read from Kafka to Spark and persist to the grid):
package com.magic.insightedge
import com.magic.events.Events
import com.magic.events.Events.CarEvent
import kafka.serializer.StringDecoder
import org.apache.log4j. {
Level,
Logger
}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming. {
Seconds,
StreamingContext
}
import org.apache.spark.SparkConf
import org.insightedge.spark.context.InsightEdgeConfig
import org.insightedge.spark.implicits.all._
import org.rogach.scallop.ScallopConf
import play.api.libs.json.Json
object EventsStreamApp {
implicit val carEventReads = Json.reads[CarEvent]
def main(args: Array[String]): Unit = {
println("Starting Car Events Stream")
println(s "with params: ${args.toList}")
val conf = new Conf(args)
println(s "conf=${conf}")
println(s "checkpointDir=${conf.checkpointDir()}")
val ssc = StreamingContext.getOrCreate(conf.checkpointDir(), () => createContext(conf))
ssc.start()
ssc.awaitTermination()
println("done")
}
class Conf(args: Array[String]) extends ScallopConf(args) {
val masterUrl = opt[String]("master-url", required = true)
val spaceName = opt[String]("space-name", required = true)
val lookupGroups = opt[String]("lookup-groups", required = true)
val lookupLocators = opt[String]("lookup-locators", required = true)
val zookeeper = opt[String]("zookeeper", required = true)
val groupId = opt[String]("group-id", required = true)
val batchDuration = opt[String]("batch-duration", required = true)
val checkpointDir = opt[String]("checkpoint-dir", required = true)
verify()
}
def createContext(conf: Conf): StreamingContext = {
val ieConfig = InsightEdgeConfig(conf.spaceName(), Some(conf.lookupGroups()), Some(conf.lookupLocators()))
val scConfig = new SparkConf().setAppName("EventsStream").setMaster(conf.masterUrl()).setInsightEdgeConfig(ieConfig)
val kafkaParams = Map("zookeeper.connect" - > conf.zookeeper(), "group.id" - > conf.groupId())
val ssc = new StreamingContext(scConfig, Seconds(conf.batchDuration().toInt))
ssc.checkpoint(conf.checkpointDir())
val sc = ssc.sparkContext
val rootLogger = Logger.getRootLogger
rootLogger.setLevel(Level.ERROR)
// open Kafka streams
val carStream = createCarStream(ssc, kafkaParams)
carStream
.mapPartitions {
partitions =>
partitions.map {
e =>
print("_______________________________- " + e)
model.CarEvent(
e.ID,
e.COL1,
e.COL2,
e.IsSentByHttp)
}
}
.saveToGrid()
ssc
}
def createCarStream(ssc: StreamingContext, kafkaParams: Map[String, String]): DStream[CarEvent] = {
KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams,
Map("car_events" - > 1), StorageLevel.MEMORY_ONLY)
.map(_._2)
.map(message => Json.parse(message).as[CarEvent])
}
}
Now, we have three options of running logic:
- Spark job
- Grid job (event-driven)
- External job against the Grid (which temporarily “holds” the data for Spark)
We chose to go with the third option as we have scalability and growth considerations. We need to take into account dozen of external processes running rather than one very long event on the grid. It’s a simple push/pull decision and we’ve decided to pull (If you wish to implement a Processing Unit (PU), see appendix 1).

Executing an external job against the Grid is an interesting choice altogether because it is something that can be initiated from any integration end-point, starting with a simple JAR file and implementing it in any custom made code or integration platform:
package com.magic;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.mime.MultipartEntityBuilder;
import org.apache.http.impl.client.DefaultHttpClient;
import org.openspaces.core.GigaSpace;
import org.openspaces.core.GigaSpaceConfigurer;
import org.openspaces.core.space.UrlSpaceConfigurer;
import com.j_spaces.core.client.SQLQuery;
import com.magic.insightedge.model.CarEvent;
public class CarEventDispatcher {
private static String postUrl;
public static void main(String[] args) throws InterruptedException {
if (args.length < 2) {
System.out.println("\tNot enough arguments. Usage: java -jar events-dispatcher.jar " +
"<post-url> <remove-dispatched-from-space true|false>");
System.exit(1);
}
postUrl = args[0];
System.out.println("\tPOST URL: " + postUrl);
// remove dispatched from the space or update field 'isSentByHttp' to 'true'
boolean removeDispatchedFromSpace = Boolean.parseBoolean(args[1]);
System.out.println("\tRemove dispatched events from space: " + removeDispatchedFromSpace);
UrlSpaceConfigurer spaceConfigurer = new UrlSpaceConfigurer("jini://localhost/*/insightedge-space");
GigaSpace gigaSpace = new GigaSpaceConfigurer(spaceConfigurer).gigaSpace();
SQLQuery<CarEvent> query = new SQLQuery<>(CarEvent.class, "isSentByHttp = false AND WIP = 0");
CarEvent[] events;
if (removeDispatchedFromSpace) {
events = gigaSpace.takeMultiple(query);
} else {
events = gigaSpace.readMultiple(query);
}
if (events.length > 0) {
System.out.println("Dispatching " + events.length + " car events from space ");
for (CarEvent e: events) {
System.out.println("Posting " + e);
try {
httpPost(postUrl, e.toString());
Thread.sleep(1000);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
if (!removeDispatchedFromSpace) {
e.setIsSentByHttp(true);
gigaSpace.write(e);
}
}
}
} else {
System.out.println("Nothing to dispatch, 0 events in space ");
}
}
public static void httpPost(String postUrl, String payload) throws IOException {
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost(postUrl);
HttpEntity entity = MultipartEntityBuilder
.create()
.addTextBody("appname", "IFSIoTDemo")
.addTextBody("prgname", "HTTP")
.addTextBody("arguments", "-AHTTP_IoTDemo#RobotTransmission,TransmissionXML")
.addTextBody("TransmissionXML", payload)
.build();
httppost.setEntity(entity);
HttpResponse response = httpclient.execute(httppost);
System.out.println("HTTP response code = " + response.getStatusLine().getStatusCode());
BufferedReader respReader = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String line;
while ((line = respReader.readLine()) != null) {
System.out.println(line);
}
}
}
To run the above code, we’ll use a simple script that will call the generated JAR file:
#!/usr/bin/env bash
# Run dispatcher every 5 seconds
SLEEP_TIME=5
POST_URL=http://cloud.magicsoftware.de/Magicxpi4.5/MgWebRequester.dll
# whether to delete dispatched events from the space OR update 'isSentByHttp' field. Possible values: 'true' - remove, 'false' - update
REMOVE_DISPATCHED_FROM_SPACE=false
echo " DISPATCHER will run every $SLEEP_TIME seconds:"
while true
do
sleep $SLEEP_TIME
echo "*** Running dispatcher: "
java -jar ../events-dispatcher/target/events-dispatcher.jar $POST_URL $REMOVE_DISPATCHED_FROM_SPACE
done
As a bonus, here’s a code to remove all the car events from the space (the Grid that is):
package com.magic;
import com.j_spaces.core.client.SQLQuery;
import com.magic.insightedge.model.CarEvent;
import org.openspaces.core.GigaSpace;
import org.openspaces.core.GigaSpaceConfigurer;
import org.openspaces.core.space.UrlSpaceConfigurer;
public class DeleteCarEventsUtil {
public static void main(String[] args) {
System.out.println("DELETING all CarEvent's from the space");
UrlSpaceConfigurer spaceConfigurer = new UrlSpaceConfigurer("jini://localhost/*/insightedge-space");
GigaSpace gigaSpace = new GigaSpaceConfigurer(spaceConfigurer).gigaSpace();
SQLQuery<CarEvent> query = new SQLQuery<CarEvent>(CarEvent.class, "");
gigaSpace.takeMultiple(query);
}
}
Now that we can dispatch the events from the Grid, let’s work backward on deploying the spark job so it can listen on the Kafka topic and ingest the data:
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
streamJar="../events-streaming/target/events-streaming.jar"
ieHost=localhost
zookeeper=localhost:2181
nohup $INSIGHTEDGE_HOME/bin/insightedge-submit \
--class com.magic.insightedge.EventsStreamApp \
--master spark://$ieHost:7077 \
--executor-cores 2 \
$streamJar \
--master-url spark://$ieHost:7077 \
--zookeeper $zookeeper \
--group-id events-processing \
--space-name insightedge-space \
--lookup-groups insightedge \
--lookup-locators $ieHost \
--batch-duration 1 \
--checkpoint-dir "C1" &
Now we have everything running except two things: The code on collecting the data from the CSV file and how to run it. Here’s the code:
package com.magic.producer
import java.util.Properties
object ProducerApp extends App {
println("-- Running kafka producer")
println("-- Arguments: " + args.mkString("[", ",", "]"))
val delim = "="
args.find(!_.contains(delim)).foreach(a =>
throw new IllegalArgumentException("Incorrect argument " + a))
val mapArgs = args.map(a => a.trim.split(delim)).map(a => a(0) - > a(1)).toMap
val kafkaConfig = {
val props = new Properties()
props.put(BOOTSTRAP_SERVERS, mapArgs.getOrElse(BOOTSTRAP_SERVERS, "localhost:9092"))
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put(CSV_LOCATION, mapArgs.getOrElse(CSV_LOCATION, "/home/opt/magic/gigaspaces-insightedge-1.0.0-premium/temp2.csv"))
props.put(TOPIC_CAR, mapArgs.getOrElse(TOPIC_CAR, "car_events"))
props
}
println(s "-- kafkaConfig=$kafkaConfig")
CSVProducer.run(kafkaConfig)
}
So you might be asking yourselves what is the CSVProducer? Well, here it is:
package com.magic.producer
import scala.io
import scala.util.Random
import java.util. {
Properties,
UUID
}
import com.magic.events.Events._
import org.apache.kafka.clients.producer. {
KafkaProducer,
ProducerRecord
}
import play.api.libs.json.Json
object CSVProducer {
def run(kafkaConfig: Properties): Unit = {
println("-- Running CSV producer")
println("------- first arg:" + kafkaConfig.getProperty(CSV_LOCATION))
val bufferedSource = io.Source.fromFile(kafkaConfig.getProperty(CSV_LOCATION))
val producer = new KafkaProducer[String, String](kafkaConfig)
val topic = kafkaConfig.getProperty(TOPIC_CAR)
Thread.sleep(1000)
//drop the headers first line
for (line < -bufferedSource.getLines.drop(1)) {
val cols = line.split(",").map(_.trim)
// do whatever you want with the columns here
val eventJson = Json.toJson(CarEvent(
cols(0).toInt,
cols(1),
cols(2).toDouble,
false)).toString()
println(s "sending event to $topic $eventJson")
producer.send(new ProducerRecord[String, String](topic, eventJson))
producer.flush()
println(s "JSON is: $eventJson")
}
bufferedSource.close
Thread.sleep(1000) //add two more zeros to wait a whole second
}
}
Run it by using the following script:
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
producerJar="../events-producer/target/magic-events-producer.jar"
java -jar $producerJar csv.location="../KafkaInput.csv"
Final Thoughts
It is estimated that by 2017, 60% of global manufacturers will use analytics to sense and analyze data from connected products and manufacturing and optimize increasingly complex portfolios of products. By 2018, the proliferation of advanced, purpose-built, analytic applications aligned with the IoT will result in 15% productivity improvements for manufacturers regarding innovation delivery and supply chain performance.
The flexibility of combining transactional and analytics functionality provided by InsightEdge and XAP is what separates GigaSpaces from the rest. With Magic’s use case, we are enabling IoT applications at scale through open source components at the center, edge, and cloud.
Gigaspaces newest data product, InsightEdge offers an Apache Spark-empowered analytics platform to help facilitate full-spectrum analytics (streaming, machine learning, and graph processing) in IoT use cases. We are happy to integrate into Magic’s solution stack, which required full compliance with fast data and scalable scenarios.

Top comments (0)