Earlier this month, my team launched CML, our latest open-source project in the MLOps space. We think it's a step towards establishing powerful
DevOps practices (like continuous integration) as a regular fixture of machine learning and data science projects.



What is CML? Continuous Machine Learning (CML) is an open-source CLI tool for implementing continuous integration & delivery (CI/CD) with a focus on MLOps. Use it to automate development workflows — including machine provisioning, model training and evaluation, comparing ML experiments across project history, and monitoring changing datasets.
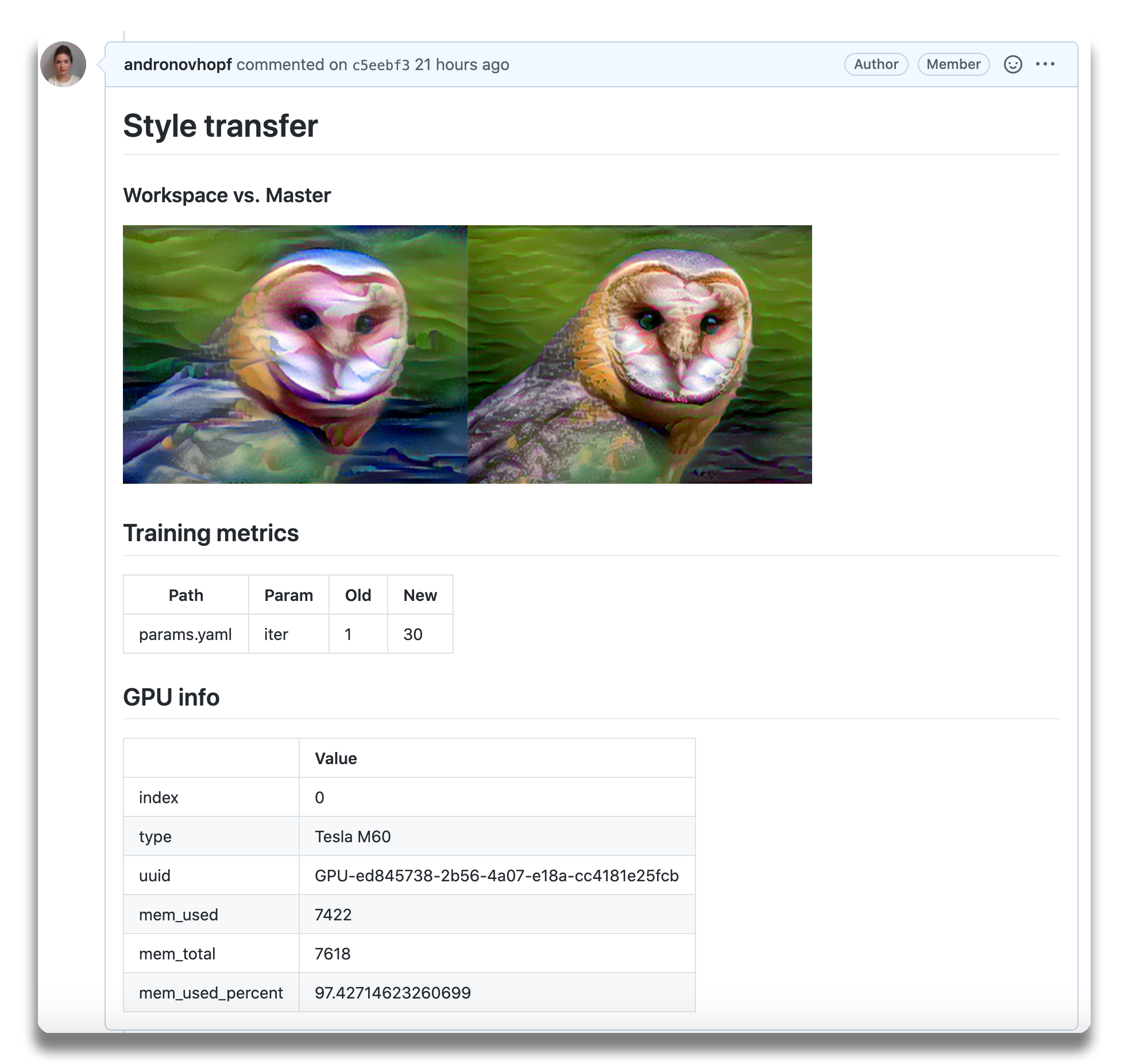
CML can help train and evaluate models — and then generate a visual report with results and metrics — automatically on every pull request.
CML principles:
- GitFlow for data science. Use GitLab or GitHub to manage ML experiments, track who trained ML models or modified data and when. Codify data and models with DVC instead of pushing to a Git repo.
- Auto reports for ML experiments. Auto-generate reports with metrics and plots in each Git pull request. Rigorous engineering practices help your team make informed, data-driven decisions.
- No additional services. Build your…
But there are plenty of challenges ahead, and a big one is literacy.
So many data scientists, like developers, are self-taught. Data science degrees have only recently emerged on the scene, which means if you polled a handful of senior-level data scientists, there'd almost certainly be no universal training
or certificate among them. Moreover, there's still no widespread agreement about what it takes to be a data scientist: is it an engineering role with a little
bit of TensorFlow sprinkled on top? A title for statisticians who can code? We're not expecting an easy resolution to these existential questions anytime soon.
In the meantime, we're starting a video series to help data scientists curious about DevOps (and developers and engineers curious about data science!) get started. Through hands-on coding examples and use cases, we want to give data science practitioners the fundamentals to explore, use, and influence MLOps.
The first video in this series uses a lightweight and fairly popular data science problem- building a model to predict wine quality ratings- as a playground to introduce continuous integration.
The tutorial covers:
- Using Git-flow in a data science project (making a feature branch and pull request)
- Creating your first GitHub Action to train and evaluate a model
- Using CML to generate visual reports in your pull request summarizing model performance
Code for the project is available online so you can follow along!
 elleobrien
/
wine
elleobrien
/
wine
wine prediction dataset
Wine quality prediction
Modelling a Kaggle dataset of red wine properties and quality ratings.
We also recommend checking out the CML docs for more details, tutorials, and use cases.
If you have questions, the best way to get in touch is by leaving a comment on the blog, video, or our Discord channel. And, we're especially interested to hear what use cases you'd like to see covered in future videos- tell us about your data science project and how you could imagine using continuous integration, and we might be able to create a video!

Top comments (0)