
To start deeply investigating the AI app development process, it’s important to first understand how these projects differ from regular app development projects. When it comes to AI, every problem requires a unique solution, even if the company developed similar projects earlier. On the one hand, there are a variety of pre-trained models and verified approaches for building AI. Also, AI is always unique as it is based on different data and business cases. Because of this, AI engineers often start the journey by diving deep into the business case and available data, exploring existing approaches and models.
Due to these aspects, AI project creation is much closer to scientific research than it is to classic software development. Let’s explore why this is and how understanding this reality can help you prepare to execute these processes and budget for your project.
AI Project Classification by the Level of Complexity
AI projects can be classified into four groups:
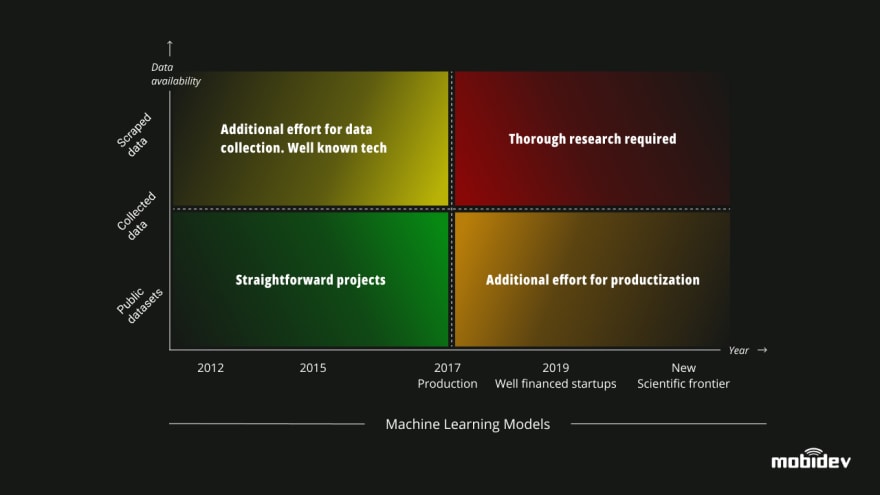
Straightforward projects
The typical examples include production-ready models that can be implemented with the application of public datasets and well-known technology. For example, ImageNet is suitable for projects aiming to classify images.Well-known technology projects
In these cases, we know the appropriate technology needed for the project, but we still need to put in the effort to collect and prepare data.Thorough research requiring projects
In principle, we can figure out how the model works and how to apply existing data, or what steps should be taken to train the model for specific tasks. Experience alone won’t allow us to make any predictions because we don’t know how the model behaves. The process of launch requires additional testing and handling of cases.Extra effort required for production projects
Cases from this group envisage difficulties both with data and models that haven’t been sufficiently tried in practice.
Why Are AI Projects So Unpredictable?
AI project development environments can be visualized as a three-layer pyramid consisting of technologies and ready-to-use solutions.
The upper level contains ready-made products suitable for AI usage – like third-party libraries or proven company solutions. For instance, Google’s solutions for detecting cheque fraud, facial recognition and object detection serve as good examples.
The second level consists of new niches describing business challenges. We may have the appropriate model to solve the challenge, yet the technology requires a slight modification or adaptation to prove its effectiveness during the implementation. The model is supposed to be specialized for its particular use case, and this leads to the emergence of a new niche in AI usage.
Scientific research constitutes the low-level layer. Here we may find papers and new models – let us mention GPT-3 as an example. Scientific research isn’t production-ready since we don’t know which results such models will demonstrate. It’s a deep level in the AI system, though we can work in this direction.
How Does AI App Development Differ from Usual Apps?
Application development with AI isn’t fundamentally different from the non-AI application, but incorporates PoC (Proof of Concept) and a demo. Turns out the stage of BA and the UI/UX stage starts when the demo and the AI component are ready.
The first thing an app development company does when it has been tasked by a product owner to create an AI-powered application is ask about clients’ needs and data. Is AI the core of the product or an additional component? The answer to this question impacts how sophisticated the solution will be.
The clients may not need the most accurate and contemporary solution. Therefore, it’s important to find out whether the lack of the AI component is blocking the full-fledged product development and if there is any point to create the product without the AI component. After this is worked out, we can move on.
At the beginning, we can classify AI projects into two subcategories – whether an app is built from scratch or an AI component is integrated into an existing app.
Building an AI App from Scratch
So, you’ve decided to develop a new AI-feature application from scratch. Because of this, you don’t have any infrastructure to integrate the AI-app with. Here we come to the most important question: can AI feature development be handled the same way usual app features are handled, such as login/logout or send/receive messages and photos?
At first glance, AI is just a feature users can interact with. For example, AI can be used to detect if a message should be considered as spam, to recognize a smile on a face in the photo, to implement AI-based login with the help of face and voice recognition.
However, development of AI solutions is quite young and research-based. It leads to the realization that AI features of an application are the riskiest part of the whole project. Especially if the business goal requires coming up with an innovative and complex AI solution.
Let’s consider a small example. You want to build a chat app with a login/logout screen, message system, and video calls. Video calls should support Snapchat-like filters. Here is a table of risks and an overview of the complexity of different features of the app:

Looking at the table it is clear that from the point of risk minimization strategy it’s not reasonable to start the development process with the tasks that have the lowest complexity and risks.
You may ask, how come Snapchat-like filters have the most risk? Here is a simple answer: to create a snapchat-like filter you have to involve a lot of cutting edge technologies like AR and deep learning, mix them properly together and put them on mobile phones that operate with low computational resources. To do so, you have to solve a lot of extraordinary engineering tasks.
That’s why AI application development from scratch has a very specific PoC structure which will be discussed further in this article in the “PoC Development Stage” section.
Integrating AI Component into an Existing App
Integration of an AI feature into an existing project has some differences from building AI apps from scratch.
First of all, it is a common case from our experience that existing projects we have to enhance with AI were developed without any architectural consideration of AI features. Taking into account that an AI feature is a part of some of the data pipeline, we conclude that development of an AI-feature will definitely require at least some changes in the application architecture.
From the perspective of AI, existing applications may be classified as follows:
DB-based projects:
Text processing
Recommendation systems
Chatbots
Time series forecasting
Non-DB based projects:
Image / video processing
Voice / sound processing
Below, we will overview the PoC development for a new AI feature development project and integration for both DB and non-DB based projects.
Main Stages of AI App Development Process
Let’s overview how a typical AI app development process grows in five stages.
1. BUSINESS ANALYSIS STAGE
At the first stage, we obtain the client’s input or vision that could be the document with the general idea overview. Here we start the business analysis process.
To prepare input, we need to consider the business problem. Businesses address app development companies with the business problem, and it’s the job of the latter to find the intersection point of the business and the capability of AI.
For example, in the case of a restaurant or grocery chain, business owners are interested in reducing food waste and achieving a balance through the analysis of purchases and sales. For AI engineers, this task turns into time series prediction or a relational analysis task whose solution enables us to predict specific numbers. We have worked on similar projects for our clients, and this case study can be looked at as an example of machine learning-based demand forecasting module development.
2. MACHINE LEARNING PROBLEM DETERMINATION STAGE
The next stage is determination of the ML (Machine Learning) problem that should be discussed and solved. This must take into account the technological capabilities of Artificial Intelligence subfields, such as Computer Vision, Natural Language Processing, Speech recognition, Forecasting, Generative AI, and others.
3. DATA COLLECTION STAGE
Data is the fuel of machine learning. There are two main data types — specific and general. General data can be obtained from open-source data websites, so all we must do comes down to narrowing the scope of the target audience, putting emphasis on the particular region, gender, age, or other crucial factors. Plenty of general data can simplify the process.
Therefore, if the client has an app based on the fitness tracker activity, we can apply data and transfer learning to start implementation as fast as possible. The same applies for image classification where plenty of collections are available to start with.
Another option would be the lack of available data, its irreconcilability with the target audience, or the need for data generated by the particular business. For example, the sales statistics of a particular business or defect detection list of an assembly line. What can be done if the client has no data, yet intends to implement the AI component?
There are six sources to draw data from.
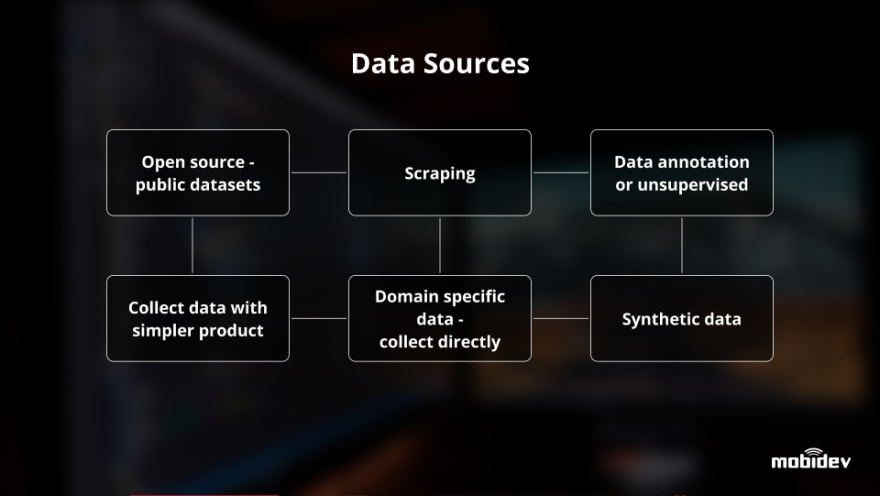
The first is a treasure trove of open-source data that enables lots of projects to start with public datasets.
The second source is scraping which helps to implement AI projects with text data. Web pages like Wikipedia contain textual information or specific data. For instance, a database of vacancies, without regard for AI, may be useful for recruiting departments. Such kind of data is half open-source.
The third source implies data annotation carried out manually or automatically. In the case of manual data annotation, a third-party company can be involved to collect and label pictures or other data.
The fourth source is data acquisition by means of a collection with a simpler product. A typical case point is chatbot development. If we do not have data for implementation, we ask the client a set of questions. Answers to these questions serve as the input for further development. Further examples of character recognition may also be cited: users correct errors in the text obtained as the output of the raw model, and this information allows us to improve the model.
However, specific data is the fifth source of information, and plenty of work should be done to collect it.
The last source, synthetic data, appears when we generate something like graphs, charts, or diagrams on our own. AI engineers generate graphs or diagrams with Python and use them as a dataset for starters. Subsequently, more realistic production data is being added here. Another example of a synthetic approach for data collection is the use of 3D game engines like Unity or Unreal Engine for different types of computer vision tasks and even for tasks of training self-driven cars.
The role of data in AI projects shouldn’t be diminished. How effectively an algorithm is working depends on data, so the vastness of input makes it more accurate.
There are special techniques capable of improving data quality.
4. POC DEVELOPMENT STAGE
The next step is to outline business and technical metrics that can differ significantly. A business owner may wonder whether the accuracy of the project would be sufficient. An AI engineer isn’t always ready to answer this question since it could be a new niche. PoC comes to the rescue, showing the minimal accuracy that can be obtained. Most remarkably, binary decisions are 50% accurate, just like a coin toss.
Let’s take a look at the first example in which the client needs to reduce food waste. By transforming a business problem into a technical solution, we have reached the conclusion that we need to predict purchases, so metric MAPE (Mean Absolute Percentage Error) would be optimal.
The second example is secure login for which the equal error rate (EER) is a business metric. EER corresponds to the equality of false acceptance rate and false rejection rate.
The third example is a classification problem for which the accuracy of correctly recognized entities serves as a business metric. By classifying entities we can consider text with spam, images with cats, whether the employee wears a mask, etc. Engineers are free to use the same metric or make the task a bit more complicated and apply an F1 score for illustration purposes.
The next point to be defined before starting with PoC is limitations. This is a non-functional requirement that could become clear later, during implementation. PoC must be based on one hypothesis and solve the particular task. The illustration of a security limitation is the necessity to blur everything behind the person in the background.
Once the input has been prepared, the AI team works on PoC, metrics, measurement of the results, and the demo. A report can be made in parallel with a demo, describing investigations, pitfalls, and confirming or denying the hypothesis.
Every research included in PoC is accompanied by a report: what has been found out, what could be done in the future, and what information has become clear and should be taken into account in the next iterations.
Although similar to a product, PoC isn’t actually ready for usage. It can be converted into a product if the demo suits the client. It is important to realize that for full-fledged product development in addition to AI engineers, we need other specialists — front-end, back-end, and mobile developers, to name but a few.
DEVELOPING AI POC FOR NEW PROJECTS
The PoC stage of a fresh new AI project should be AI-centric. What does this mean? To meet the risk minimization strategy, we should start with the riskiest part of the project, the AI feature, and not touch any other features of the project, if possible.
According to CRISP-DM, the PoC stage may be repeated several times to achieve suitable results.
After satisfactory results are achieved we are free to proceed to the MVP/industrialization stage with the development of all remaining features of the application.

DEVELOPING AI POC FOR EXISTING PROJECTS
To make an AI feature available for end-users we first have to develop the feature and then integrate it with the existing application. Namely, with the application codebase, architecture, and infrastructure.
The most fascinating thing about AI-features is that they can be researched, developed, and tested without touching the main application. This leads us to the idea that we can start AI-isolated PoC without risks for the main application. This is in fact the essence of risk minimization strategy.
Here are three steps to follow:
1. Collect data from the existing application by:
Making DB dump
Collecting image/video/audio samples
Labeling collected data or getting relevant data sets from open source libraries
2. Build an isolated AI environment with the use of the data collected earlier for:
Training
Testing
Profiling
3. Deploy the successfully trained AI component:
Changes in preparation for the current application architecture
Codebase adaptation for the new AI feature
Depending on the project type, adaptation of the codebase may lead to:
Changes to the database architecture for simplification and speeding up the AI module’s access to it
Changes to the microservice topology for video/audio processing
Changes to mobile application minimum system requirements

ROUGH ESTIMATION OF THE POC STAGE
Business owners often ask software vendors about the budget, timeline, and effort the PoC stage might take.
As we’ve shown above, AI-projects are characterized by a high level of unpredictability compared to the regular development process. This is due to high variability of tasks types, data sets, approaches, and technologies.
All these conditions explain why giving estimates for a hypothetical project is quite a difficult task. Still, we have shown one of the possible classifications of the AI projects above based on the project’s level of complexity.
The next table shows rough estimates for projects of different complexity levels. Please keep in mind that the estimates in the table may vary significantly depending on the project type, and data set properties. The numbers are given for a single CRISP-DM iteration.

5. NEW ITERATION AND/OR PRODUCTION STAGE
The next step after the first PoC can be a new iteration of PoC with further improvements or deployment. Creating a new PoC implies data addition, processing of cases, error analysis, etc. The number of iterations is conditional and depends on the project.
Starting Up
Any AI project is directly linked to risks. We can face risks derived from data suitability, as well as algorithmic or implementation risks. To mitigate the risks, it’s wise to start product development only when the AI-component’s accuracy meets the business’s goals and expectations.

Top comments (3)
Extremely comprehensive take on the subject. You're a great writer!
Thank you!
Thank you for writing such an informative article on the topic. Your writing style is amazing and I really enjoyed reading the blog.
We also write articles on similar topics - Unlocking the Power of Data And AI for Businesses
Some comments have been hidden by the post's author - find out more