Kafka Streams is a powerful library for writing streaming applications and microservices on top of Apache Kafka in Java and Scala.
When writing a Kafka Streams application, developers must not only define their topology, i.e. the sequence of operations to be applied to the consumed messages, but also the code needed to execute it.
Furthermore, to write a production-ready application, you will have to know; how to handle processing failures and bad records, how to monitor and operate instances. And, if you plan to expose some internal states, using the Kafka Streams built-in feature so-called "Interactive Queries", you will also have to write code to get access to your data (for example via REST APIs).
As a result of this, your application can quickly become complex with boilerplate code that has no direct business value but that you will have to maintain and duplicate and other projects.
Azkarra Streams is an open-source lightweight Java framework which makes easy to develop and operate Kafka Streams applications (Azkarra is Basque word for "Fast").
Key Features
Azkarra Streams provides a set of features to quickly debug and build production-ready Kafka Streams applications. This includes, among other things:
- Lifecycle management of Kafka Streams instances (no more KafkaStreams#start()).
- Easy externalization of Topology and KafkaStreams configurations (using Typesafe Config).
- Embedded HTTP server for querying state store (Undertow).
- HTTP endpoint to monitor streams application metrics (e.g : JSON, Prometheus).
- Web UI for topologies visualization.
- Encryption and Authentication with SSL or Basic Auth. Etc.
Getting Started
Since Azkarra v0.5.0, one way to get started with Azkarra is to use the official Docker image (streamthoughts/azkarra-streams-worker) that allows running a standalone Azkarra worker to execute one or many Kafka Streams applications.
Azkarra Worker follows the same mechanism used by the Kafka Connect project, i.e. that Kafka Streams topologies are provided as external components that can be started and stopped either via REST calls or an embedded UI.
Let's start an Azkarra worker instance and a broker-single node cluster using the docker-compose.yml available on the GitHub repository.
1 ) Run the following command to download and run containers :
$ curl -s https://raw.githubusercontent.com/streamthoughts/azkarra-streams/master/docker-compose.yml --output \
docker-compose.yml && docker-compose up -d
2 ) Check that Azkarra worker is up and running :
$ curl -sX GET http://localhost:8080 | jq
{
"azkarraVersion": "0.5.0",
"commitId": "d2bc2fdc24e68eb143f4388960881974604093ca",
"branch": "master"
}
3 ) Finally, you can access the Azkarra Web UI is available on: http://localhost:8080/ui.
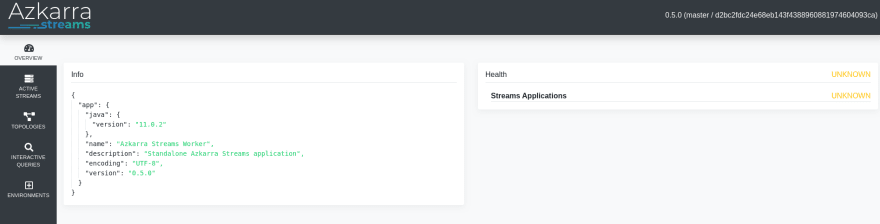
As we can see, for the moment our worker is doing absolutely nothing since we have not yet deployed a topology. So, let's write a simple Kafka Streams application.
Writing A First Kafka Streams Topology
For demonstrating the use of Azkarra API, we will rewrite the standard WordCountTopology example.
First, let's create a simple Java project and add Azkarra Streams to the dependency of your project.
For Maven (pom.xml):
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.4.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.streamthoughts</groupId>
<artifactId>azkarra-streams</artifactId>
<version>0.5.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
Note that when using Azkarra Worker, your project should never contain any libraries that are provided by Azkarra Worker’s runtime (i.e azkarra-*, kafka-streams).
Secondly, let's define our Kafka Streams Topology by creating a new file WordCountTopology.java.
package azkarra;
import io.streamthoughts.azkarra.api.annotations.*;
import io.streamthoughts.azkarra.api.streams.TopologyProvider;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.*;
import java.util.Arrays;
@Component
@TopologyInfo(description = "WordCount topology example")
public class WordCountTopology implements TopologyProvider {
@Override
public Topology get() {
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("streams-plaintext-input");
textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.as("WordCount"))
.toStream()
.to(
"streams-wordcount-output",
Produced.with(Serdes.String(), Serdes.Long())
);
return builder.build();
}
@Override
public String version() {
return "1.0";
}
}
As you can see, we have implemented the TopologyProvider interface to provide the Topology object. Azkarra enforces you to version each provided topology. This is useful, for example, to execute multiple versions of the same topology or to automatically generate meaningful application.id.
The annotation @Component is required to let Azkarra detects this class.
And that's all! Azkarra will be responsible to create and manage the KafkaStreams instance that will run the provided Topology.
Deploying A Streams Topology
Now, we need to make our WordCountTopology available to the worker.
For doing this, we have to package and install our component into one of the directories configured via the property azkarra.component.paths.
If you look at the docker-compose.yml you will see that this property is set to /tmp/azkarra/components using an environment variable.
The azkarra.component.paths property should define the list of locations (separated by a comma) from which the components will be scanned.
Each configured directories may contain:
an uber JAR containing all of the classes and third-party dependencies for the component (e.g., topology).
a directory containing all JARs for the component
Usually, with Maven, you will use the maven-assembly-plugin or maven-shade-plugin to build your project to an uber JAR.
After packaging your application, you can copy the .jar into the local directory /tmp/azkarra/components.
Then, restart the docker containers as follows:
$ docker-compose restart
Now, you should be able to list the available topologies via the REST API :
curl -sX GET http://localhost:8080/api/v1/topologies | jq
[
{
"name": "azkarra.WordCountTopology",
"version": "1.0",
"description": "WordCount topology example",
"aliases": [
"WordCount",
"WordCountTopology"
],
"config": {}
}
]
Finally, let's start a new Kafka Streams instance by submitting the following JSON config :
curl -H "Content-Type:application/json" \
-X POST http://localhost:8080/api/v1/streams \
--data '{"type": "azkarra.WordCountTopology", "version": "1.0", "env": "__default", "config": {} }'
In the command above, we are specifying the type and version of the topology to deploy and the target environment.
Indeed, Azkarra has a concept of StreamsExecutionEnvironment which acts as a container for executing streams instances. By default, an environment named __default is created.
Note that Azkarra will automatically create any source and sink topics defined by the topology (azkarra.context.auto.create.topics.enable=true).
Exploring Azkarra Web UI
Azkarra ships with an embedded Web UI that lets you get information about the running Kafka Streams applications.
For example, you can :
Get details about the threads and tasks of a running streams instance :

Visualize the streams topology DAG:

List the Kafka Streams metrics:
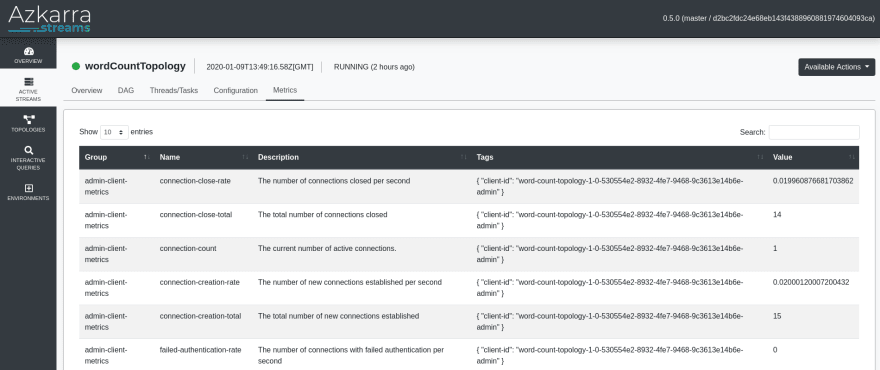
Furthermore, the Azkarra Web UI allows you to stop, restart and delete local streams instances.
Querying states stores
Finally, Kafka Streams has a great mechanism to query the states materialized by streams applications via REST API calls.
Let's produce some messages as follows:
$ docker exec -it broker /usr/bin/kafka-console-producer \
--topic streams-plaintext-input \
--broker-list broker:9092
Azkarra Streams
WordCount
I Heart Logs
Kafka Streams
Making Sense of Stream Processing
The following is an example to query the state WordCount :
curl -sX POST http://localhost:8080/api/v1/applications/word-count-topology-1-0/stores/WordCount \
--data '{"query":{"get":{"key": "streams"}},"type":"key_value", "set_options":{}}' | jq
{
"took": 1,
"timeout": false,
"server": "azkarra:8080",
"status": "SUCCESS",
"result": {
"success": [
{
"server": "azkarra:8080",
"remote": false,
"records": [
{
"key": "streams",
"value": 2
}
]
}
],
"total": 1
}
}
You can also query a state directly through the Azkarra WebUI.
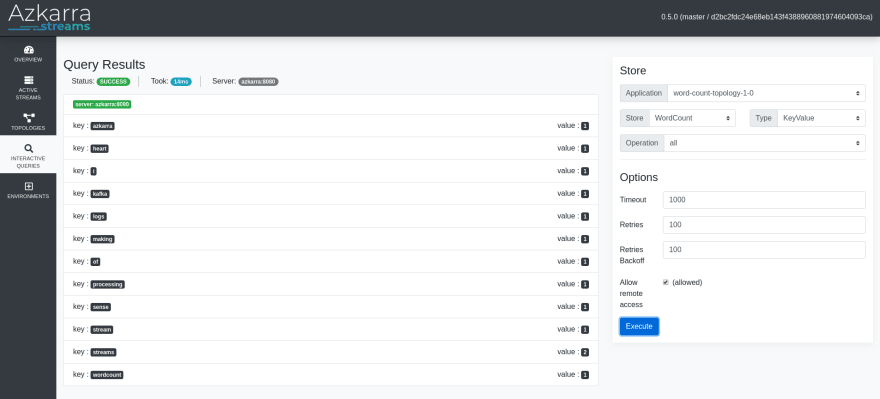
Going further
If you want to read more about using Azkarra Streams, the documentation can be found on GitHub Page.
The documentation contains a step by step getting started to learn basic concepts of Azkarra.
The project also contains some examples.
Conclusion
Azkarra Streams is an initiative to enrich the Kafka Streams ecosystem and facilitate its adoption by developers through a lightweight micro-framework.
We hope this project will be well received by the open-source and Kafka community. Azkarra is still evolving and some features need improvements.
To support Azkarra Streams project, please ⭐ the Github repository or tweet if this project helps you!
Thank you very much!

Top comments (0)