页面内容结构

部分页面还有广告、推荐视频等模块
ctrl+u查看源码,如图:

格式化后:

提取主要搜索结果
将搜索腾讯的内容源码保存在本地,命名为tencen.html,使用bs4包进行解析。
with open('tencent.html', 'r', encoding='utf-8') as f:
res = f.read()
soup = BeautifulSoup(res, 'html.parser')
print(soup.title.text)
返回title的结果:

我们首先提取主要的搜索结果,通过对代码的分析,google的主要搜索结果包裹在div.g中,如图。

标题对应是h3元素,点击的链接对应的是a.href,描述内容在span.aC0pRe内容中,就可以写出一个对主要搜索结果的解析函数:
def search_result(soup:BeautifulSoup) -> list:
"""解析主要搜索结果
Args:
soup (BeautifulSoup): bs4对网页页面的解析结果
Returns:
list: 解析后的结果列表
"""
# 获取所有的主要搜索结果
result_containers = soup.findAll('div', class_='g')
# 返回结果
results = []
for container in result_containers:
# title提取
try:
title = container.find('h3').text
# 对应链接提取
url = container.find('a')['href']
# 对应描述提取
des = container.find('span', class_='aCOpRe').text
results.append({
'title': title,
'url': url,
'des': des,
'type': 'result'
})
except Exception:
continue
return results
输出如下:

提取Wiki区域内容
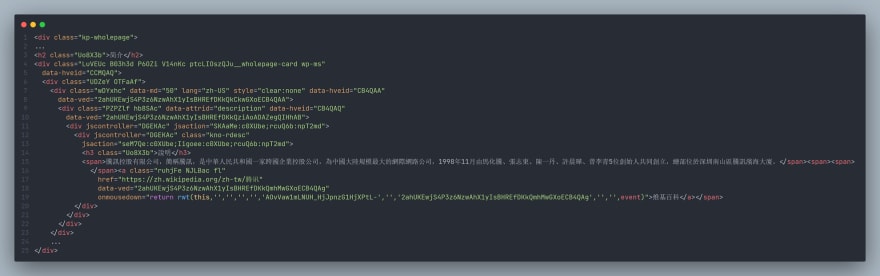
wiki区域被包裹在"div.kp-wholepage"中,其中h2, {data-attrid: title}元素指向wiki区域的标题,div, {data-attrid:subtitle}指向wiki的副标题。
div.kno-rdesc中含有指向维基百科的链接和相关描述,分别存放在a.href和span元素中。大致结构如下图。
wiki区域中还有可能含有table元素,例如搜索"咖啡",会显示其相关的成分,如图:

这个区域放在(div.wp-ms)[2]中的tr.kno-nf-nr元素中。于是,就可以写出解析wiki的对应函数。
def search_wiki(soup:BeautifulSoup) -> list:
"""解析wiki内容
Args:
soup (BeautifulSoup): bs4对网页页面的解析结果
Returns:
list: 解析后的结果列表
"""
container = soup.find('div', class_='kp-wholepage')
# 如果container为None,则返回空列表
if container is None:
return []
# Title
title = container.find('h2', attrs={'data-attrid': 'title'}).find('span').text
# Subtitle
try:
subtitle = container.find(
'div', attrs={'data-attrid': 'subtitle'}).text
except AttributeError:
subtitle = None
# Description
des = container.find('div', class_='kno-rdesc').find('span').text
# 获取Wiki链接
url = container.find('div', class_='kno-rdesc').find('a')['href']
# Details内容
try:
# div.wp-ms对应不同的四个card
table = container.findAll(
'div', class_='wp-ms')[2].findAll('tr', class_='kno-nf-nr')[1:]
except IndexError:
table = []
details = []
for row in table:
name = row.find('span').text.strip(': ')
detail_ = row.findAll('span')[1:]
detail = ''
for _ in detail_:
detail += _.text + ' ' # 以 key value的形式输出结果
details.append({
'name': name,
'detail': detail.strip()
})
result = {
'title': title,
'subtitle': subtitle,
'des': des,
'url': url,
'details': details,
'type': 'wiki'
}
return [result]
输出如下:

解析相关视频、搜索、页面数
对视频推荐的解析与上述类型,都是先定位好元素位置,再提取出相应的内容。视频提取google。 代码如下:
def search_videos(soup: BeautifulSoup):
try:
cards = soup.find('div', id='search').findAll('div', class_='VibNM')
except AttributeError:
return []
results = []
for card in cards:
title = card.find('div', role='heading').text
href = card.find('a')['href']
result = {
'title': title,
'href':href,
'type': 'video'
}
results.append(result)
return results
def get_total_page(soup: BeautifulSoup) -> int:
"""获取搜索页面数
Args:
response (requests.Response): the response requested to Google using requests
Returns:
int: the total page number (might be changing when increasing / decreasing the current page number)
"""
pages_ = soup.find('span', id='xjs').findAll('td')
maxn = 0
for p in pages_:
try:
if int(p.text) > maxn:
maxn = int(p.text)
except:
pass
return maxn
最后,将结果进行聚合。
results = []
results.extend(search_result(soup))
results.extend(search_wiki(soup))
results.extend(search_news(soup))
results.extend(search_videos(soup))
pages = get_total_page(soup)
print({
'results': results,
'pages': pages
})
总结
对google serp的解析流程大概是这样,但是这样的代码,并无法达到我们的要求。在下一节中,我们对代码进行一次重构,将会引出我们代码编写的第一个原则:面向对象编程。

Top comments (0)