

If you have been paying attention to GitHub recently — the past six months — you have seen the pattern.
A new bio-AI repository appears. It promises to automate genomic analysis, drug discovery, medical imaging, or clinical data interpretation. The README is polished. The architecture diagram looks serious. Within weeks it has hundreds of stars, a few forks, and a preprint on bioRxiv.
Then nothing.
No CI. No CHANGELOG. No response to issues. No clear statement of limitations. No clinical disclaimer anywhere in the repository. And a tool that may now be touching patient-adjacent workflows has exactly one quality gate: the author thought it was ready.
We are developers. We have built things in that atmosphere too. At some point, we had to ask a harder question than benchmark accuracy:
When a bio-AI repository gets close to real diagnostic, genomic, imaging, or therapeutic workflows — what does "trustworthy enough for serious review" actually mean?
The field has benchmarks for models. It has almost no shared standards for repository accountability.
So we built one.
What Makes This Moment Different

Bio-AI is now filling up with skill libraries, agent wrappers, orchestration pipelines, and plugin-style marketplaces that look far more deployable than they actually are. Surface maturity is easy to fake. A clean README, a marketplace entry, or a rising GitHub star count can make a repository look trustworthy long before it has earned that trust.
And this category cannot be judged like ordinary software.
If a note-taking app breaks, users get frustrated.
If an internal dashboard fails, a team loses time.
But when a biomedical or medical-AI repository fails quietly, the consequences do not stop at software quality.
A flawed genomics pipeline can distort interpretation.
A weak clinical model can normalize unsafe confidence.
A drug-discovery system can push the wrong candidates forward, bury better ones, and send time, capital, and downstream validation effort in the wrong direction.
In this category, failure is not just a debugging problem.
It is a patient-safety problem and a resource-allocation problem.
That is why these systems require more than code inspection. They require scrutiny of documentation, limits, provenance, maintenance behavior, and public claims — because the cost of being wrong is fundamentally different here.
What STEM-AI Is

STEM-AI (Sovereign Trust Evaluator for Medical AI) is a governance audit framework for public bio/medical AI repositories.
It does not ask whether a project sounds impressive.
It asks whether the repository shows observable signs of responsible engineering:
- honest documentation
- consistent public claims
- maintenance discipline
- biological data responsibility
- explicit acknowledgement of limits
That distinction matters. A repository can look technically sophisticated and still fail the most basic governance test for patient-adjacent use. A polished README is not a safety surface by itself.
STEM-AI is not a regulatory verdict, clinical certification, or legal assessment. It is a structured review framework designed to give researchers, reviewers, procurement teams, and engineers a more reproducible starting point for discussion. The canonical spec requires a non-waivable disclaimer in every output stating exactly that.
STEM-AI is meant to support serious review, not replace it.
Why We Made It LLM-Native
STEM-AI runs as a structured specification executed by a major LLM.
The spec is the program. The LLM is the runtime.
That sounds strange until you look at the design constraint. We did not want a system that "vibes" its way to a trust score. We wanted a system that forces checklist-based scoring, explicit evidence chains, N/A handling for missing data, and hard floors for catastrophic claims. The goal is to reduce evaluator drift by replacing narrative judgment with traceable rubric logic.
The model is not supposed to "feel" trust.
It is supposed to count evidence.
How It Works

STEM-AI evaluates a repository across three stages. Each stage has a defined checklist. Each score must map back to observable evidence.
These three stages ask three different questions:
- what the repository says
- what public communication says
- what the codebase actually proves
Stage 1 — README Intent
If a repository is patient-adjacent, the README is not marketing. It is the first governance surface.
WHAT WE LOOK FOR (positive signals):
[R1] Does a Limitations or Known Issues section exist
and cover a substantial portion of the README
with specific, actionable content?
[R2] Is any regulatory framework cited?
(FDA SaMD guidelines, CE marking, IRB requirements,
or equivalent)
[R3] Is there a clinical disclaimer?
("This tool is NOT a substitute for clinical judgment"
or equivalent)
[R4] Are demographic bias limits or applicable population
boundaries disclosed?
[R5] Are reproducibility provisions present?
(environment pinning, data version, seed values)
WHAT WE PENALIZE (negative signals):
[H1] Performance superlatives without benchmark comparison
"SOTA", "State-of-the-Art", "Best-in-class"
[H2] Unsubstantiated innovation claims
"Revolutionary", "Groundbreaking", "Game-changing"
[H3] Fully autonomous framing in a clinical context
"Fully Automated", "Zero Human Oversight"
without any stated supervision requirement
[H4] AGI or human-level capability claims
"AGI", "Human-level", "Surpasses clinicians"
[H5] Social proof substituted for technical credibility
GitHub stars or download counts cited as a trust signal
[H6] External optics substituted for technical evidence
VC funding or press coverage without validation
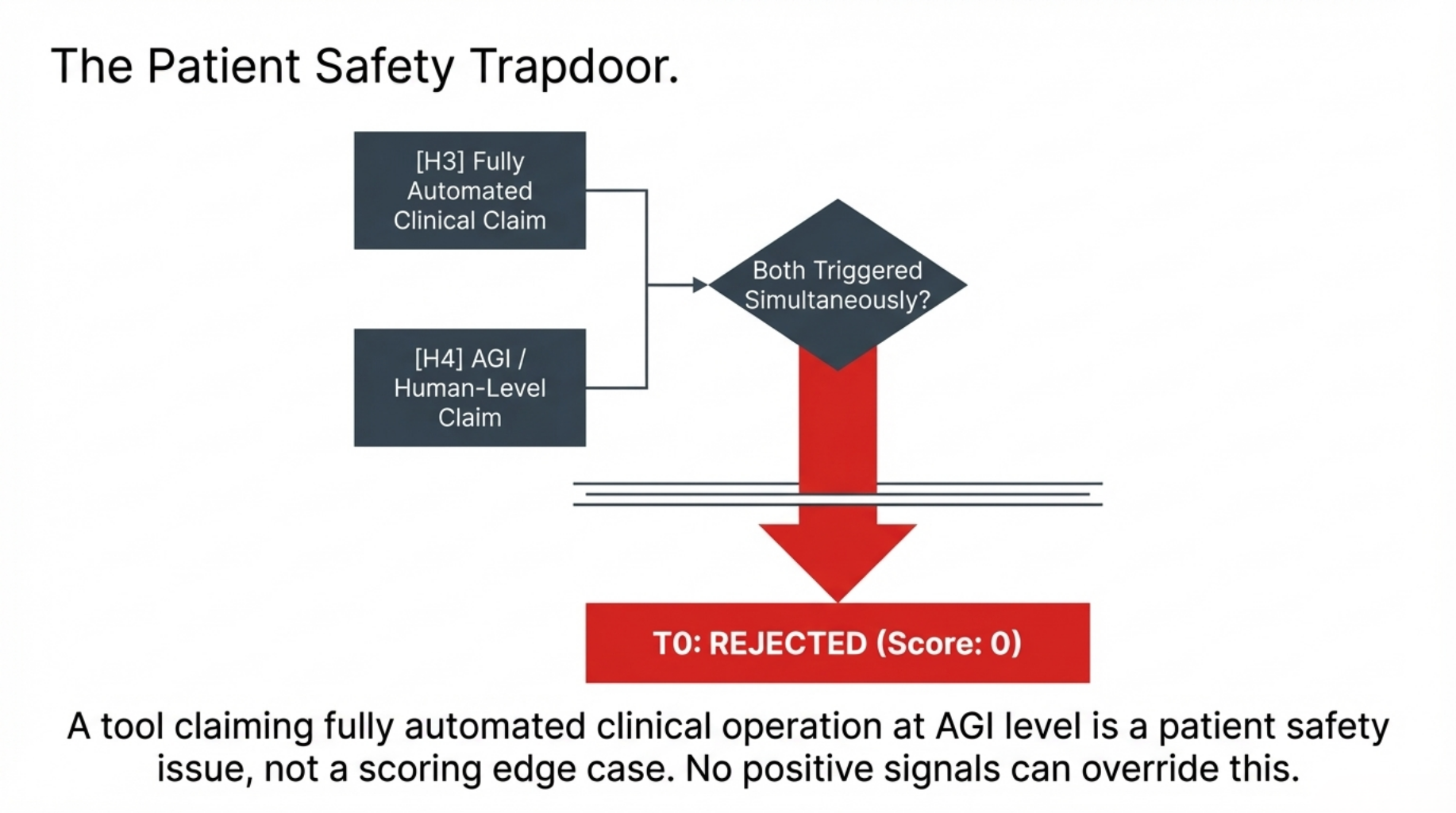
CRITICAL RULE:
IF H3 AND H4 are both triggered simultaneously:
→ Hard floor activated.
→ Final Score = 0. Tier = T0. No further scoring.
→ A tool claiming fully automated clinical operation
at AGI level is a patient safety issue,
not a scoring edge case.
No positive signals elsewhere can override this.
On clinical adjacency: STEM-AI does not assume all biomedical repositories carry the same deployment risk. The disclosure bar rises as a tool moves closer to patient-facing or decision-shaping use. If the repository contains medical imaging frameworks, drug docking engines, diagnostic genomics pipelines, or clinical language models, the absence of R2 and R3 is not a missed bonus — it becomes an active penalty.
Stage 2 — Cross-Platform Consistency
This stage is less about marketing tone and more about contradiction. If a README warns carefully but public posts erase those warnings, the repository's governance surface is inconsistent.
WHAT WE PENALIZE:
[F1] Stars or downloads used as the primary message
on external platforms, without technical substance
[F2] Public dismissal or hostile response to
critical feedback from the community
[F3] Vanity metrics presented as clinical trust proxies
[F4] External posts that directly contradict or omit
warnings stated in the README
→ Most serious flag in Stage 2.
A README that says "not for clinical use" while
the author's LinkedIn announces clinical deployment
is a consistency failure.
WHAT WE REWARD:
[A1] Model errors or hallucination cases
openly shared in public forums
[A2] Reproducibility failures or known failure modes
transparently acknowledged outside the repository
[A3] Critical external feedback accepted and incorporated
[A4] Regulatory or ethics body collaboration referenced
This stage is only as strong as the public evidence available. When live cross-platform data is unavailable, Stage 2 goes N/A and its weight moves to Stages 1 and 3. In medical-adjacent evaluation, pretending to know is worse than stating you do not.
Stage 3 — Code Infrastructure and Biological Integrity

This is where the framework becomes more than a documentation audit.
TECHNICAL RESPONSIBILITY:
[T1] CI/CD pipeline
Does automated testing run on push or PR?
Is coverage stated or just implied?
[T2] Domain-specific regression tests
Not just unit tests — tests that verify biological
or clinical correctness invariants.
[T3] CHANGELOG transparency
Does one exist?
Does it document bugs and failures honestly,
or only feature additions?
Silent updates on a clinical-adjacent tool are
a different risk profile than an honest bug log.
[T4] Issue and PR response pattern
When did the last maintainer response happen?
What proportion of issues receive a response?
BIOLOGICAL INTEGRITY:
[B1] Data provenance and consent
Where did the training or reference data come from?
Is there an IRB approval or data consent declaration?
[B2] Algorithmic bias disclosure
Are performance limits across demographic subgroups
disclosed? Are actual measurements provided,
or only a general acknowledgment?
[B3] Conflict of interest transparency
Is the funding source disclosed?
If there is commercial interest, is it stated?
TRAJECTORY SIGNAL:
v1.0.4 adds a trajectory modifier comparing issue close
rates and release frequency across two consecutive
90-day windows.
This signal is deliberately bounded: it changes Stage 3
by at most ±5 points, which translates to roughly ±2
points on the final weighted score.
Large enough to matter near tier boundaries.
Small enough not to distort the audit.
What the Output Looks Like
Every STEM-AI audit produces a structured report. Here is an illustrative example — repository name withheld, structure unchanged:
# 🩺 STEM-AI Audit Report v1.0.4
──────────────────────────────────────────────
Target: [Repository Name]
Audit Date: 2026-03-20
Report Expiry: 2026-09-16
Flags: CLINICAL_ADJACENT: true
NASCENT_REPO: false
T0_HARD_FLOOR: false
──────────────────────────────────────────────
Stage 1 — README Intent 47 / 100 VC Pitch
Stage 2 — Cross-Platform N/A (MANUAL mode)
Stage 3 — Code Infrastructure 10 / 100 Hit-and-Run
──────────────────────────────────────────────
Final Score: 28 / 100
Tier: T0 REJECTED
USE_SCOPE: None — clinical use prohibited
──────────────────────────────────────────────
Priority Remediation:
1. Add clinical disclaimer (active penalty applied —
clinical-adjacent tooling without R3)
2. Implement CI/CD pipeline (T1: 0 pts)
3. Disclose data provenance and IRB status (B1: 0 pts)
──────────────────────────────────────────────
⚠ This report is LLM-generated. It is not a regulatory
determination. Report expires: 2026-09-16.
The expiry date is not cosmetic. A report based on a repository that went inactive months ago should not circulate in procurement pipelines as if it still describes current reality. Version 1.0.4 computes that date from recent project activity automatically.
What the Tiers Mean — and What They Do Not

T0 Rejected: Trust not established
Clinical use prohibited
T1 Quarantine: High risk
Independent verification required
T2 Caution: Research reference only
Clinical automation forbidden
T3 Review: Supervised pilot eligible
Human oversight mandatory
T4 (highest tier): Strongest observed governance signals
Still requires independent expert review
and formal regulatory clearance
Even at the highest tier, STEM-AI does not substitute for clinical validation, expert review, or regulatory clearance. That is not a disclaimer added to soften the framework. It is how the framework was designed.
One Design Decision That Matters

Author background does not affect the score.
Whether the author comes from biology, medicine, ML research, or pure software engineering is recorded as contextual information for human reviewers. It is explicitly non-scoring and carries a mandatory bias warning in every report.
Domain credentials are not the same thing as engineering integrity. And lack of domain pedigree does not imply carelessness. STEM-AI is built to evaluate observable repository governance — not to sort developers by prestige.
What STEM-AI Refuses To Be
A trust framework for medical AI can become dangerous if it turns into a personal attack engine.
STEM-AI is constrained on purpose. It is limited to public professional repositories and public professional material. It forbids PII inference, private-account speculation, and individual profiling as a use case. Without that boundary, a trust evaluator becomes a harassment tool.
Three Questions This Framework Is Built Around
If you remember nothing else from this framework, remember these:
- Did the repository describe its limits honestly?
- Did public communication remain consistent with the repository's stated limits?
- Did the codebase show evidence of maintenance and biological responsibility?
Those are not performance questions. They are accountability questions. For tools that sit upstream of clinical decisions, accountability is not optional.
What Comes Tomorrow

Tomorrow we publish the first audit set from STEM-AI v1.0.4 across 10 open-source bio-AI repositories — including projects from research institutions, an actively used SaaS platform, and agent-style bioinformatics tooling running inside containerized environments.
What we can say now:
The strongest-looking repositories are not always the most accountable. In at least one case, a repository with solid engineering signals still falls short because a critical disclosure is missing from the surface a reviewer would actually read first.
In another, the safety control exists in the code but fails as governance because it does not activate under default deployment.
In another, the generation mechanism itself is not the problem. The problem is that users were never clearly told what it was. That is a disclosure failure, not a technical failure. The distinction matters.
The full breakdown publishes tomorrow.
Which bio-AI repositories would you want audited next? Drop them in the comments.
STEM-AI v1.0.4 — full audit results tomorrow.
"Code works. But does the author care about the patient?"

Top comments (0)