For the past couple of months, I have been studying High-Frequency Trading (HFT) systems, how they work and how they are architected. For complete disclosure, I do not have any Quant/HFT experience [even though I'd love to!], I am merely studying its principles on how to scale with ultra-low latency and how these principles can be applied to the Cloud. I'm also using this as a learning opportunity to develop my own simplified version of a HFT Engine. You can click the link to follow my developments, or if you want fork and clone and make your own adjustments.
The Microsecond Mindset: Why Latency Matters Beyond HFT
Latency matters because of one core reason. User's do not want to wait around for an indefinite amount of time for an application or service to run. In fact research has shown
For every second delay in mobile page load, conversions can fall by up to 20%.
Source
Now that's for your regular mobile/SaaS application that delivers on scale, that doesn't even compare on what HFT Engineer's have to deal with! But that doesn't mean it's not important, mastering the principles of latency is a craft that affects business performance overall. When it comes to HFT, trading firms are looking to capitalise on market inefficiencies in the most competitive way as possible, so they have adopted certain techniques to squeeze as much performance from their tech stack, as much as possible. In microseconds, their complex algorithms should spare no CPU waste on capitalising on a news reports, such as the US Federal Reserve or the Bank of England raising or decreasing interest rates as soon as the event is announced.
While a SaaS application might aim for 100ms response times, HFT systems operate in the microsecond range—that's 1000× faster!
Now, as regular Software Engineer's we may not need to go to the extreme end like our genius counterparts in high finance, but the principles is what can be transferred into our work-life to become more productive.
Understanding CPU Cache Hierarchies
In the context of HFT, I mentioned before that it is a very compute heavy task as you're dealing with microseconds worth of transactions/operations that are ultimately responsible of moving billions worth of dollars that move markets. So, as a result, you'd naturally think the computers these professionals operate on are much more powerful than your average tech bro that works in Shoreditch and is too busy debugging a React app hosted on Vercel.
Modern CPU's are fast, if they weren't fast then a lot of companies would go bankrupt. However, there is a bottleneck, memory access. A CPU can execute an instruction in 1 nanosecond, but accessing memory from the RAM can take almost 100 nanoseconds. In the world of HFT, quite literally, not just one second, but every nanosecond counts!
Here's where an understanding of cache heirarchy is crucial to combat this.
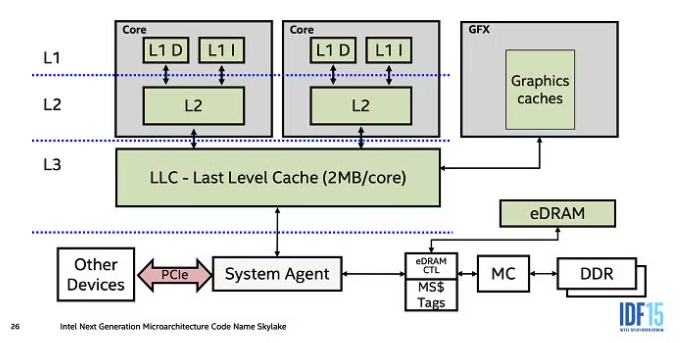
There are 3 levels of cache memory
L1 : smallest + fastest - stores data the processor is working on
L2: data that the processor may need to access soon
L3: data that is less likely to be needed by the processor
The time it takes for a CPU to access L1 is 1 to 2 nanoseconds, for L2 its 5 to 10 nanoseconds and for L3 its 10-20 nanoseconds. Quite literally, every nanosecond counts in the world of HFT!
Why am I telling you this? Because with this knowledge, HFT devs can optimise their code to ensure data is stored in L1/L2 caches to gain a competitive edge.
Memory Ordering and Atomics
Understanding memory ordering and atomics fundamental to low-latency principles.
Atomic Operations the main building blocks for anything that involves multiple threads. In Rust, atomic operations are available on the standard atomic types that live in the std::sync::atomic module.
When multiple threads need to modify a variable, atomics make sure modifications happen in a defined order without data races. These atomics are implemented using CPU-specific instructions that ensure thread safety, memory access with various memory ordering guarantees.
There are many Atomics, and each of them have unique use cases in the world of HFT
-
AtomicBool- use cases are circuit breakers, emergency stop -
AtomicU64/AtomicI64- use cases are position tracking, price update -
AtomicUSize- use cases are message counters, queue indices, resource tracking
All of these atomics have similar methods attached to them, such as load() which atomically reads the value, or store() which atomically writes a value.
Memory Ordering determines how atomic operations are synchronised between threads. In Rust, these can be used from the Ordering Enum from the std::sync::atomic module
pub enum Ordering {
Relaxed,
Release,
Acquire,
AcqRel,
SeqCst,
}
Each of these memory orderings have different guarantees. What do I mean by guarantees?
Memory ordering guarantees control how operations on atomic variables become visible to other threads. Let's break down each ordering option:
Relaxed: The weakest ordering - only guarantees that the operation itself is atomic. There are no synchronization guarantees between threads. This is the fastest option but provides minimal safety.
Acquire: Used for loads (reading). Ensures that subsequent operations in the same thread cannot be reordered before this load. Essentially saying "any operations after this read must happen after the read."
Release: Used for stores (writing). Ensures that preceding operations in the same thread cannot be reordered after this store. Tells other threads "any operations before this write must be visible before the write becomes visible."
AcqRel: Combines Acquire and Release semantics. Used for operations that both read and modify, like compare-and-swap. Provides bidirectional ordering guarantees.
SeqCst: The strongest guarantee - Sequential Consistency. Ensures a total ordering of operations across all threads. It's the most intuitive but also the most expensive.
To summarise, atomics are the building blocks, memory ordering determines the atomics "behaviour"
Lock-Free Programming: The Art of Coordination Without Waiting
Lock-Free Programming is a paradigm that allows multiple threads to operate on shared data without traditional "locking mechanisms" like mutexes. Lock-Free Programming utilises Atomics as building blocks and also careful synchronisation techniques.
If you want to figure out if your program is "Lock-Free", then look at this code below
const isLockFree = null;
if ("Are you programming with multiple threads?") {
if("Do the threads access shared memory"){
if("Can the threads operate WITHOUT blocking each other?"){
isLockFree = true
}
}
}
These are the characteristics of a lock-free program
1) Non-blocking - at least one thread makes progress even if the others fail
2) Atomicity - operations appear indivisible and are executed without interference from other threads
3) Progress guarantees - ensures the system as a whole makes progress
Here is an example of a lock-free implementation of a Queue data-structure
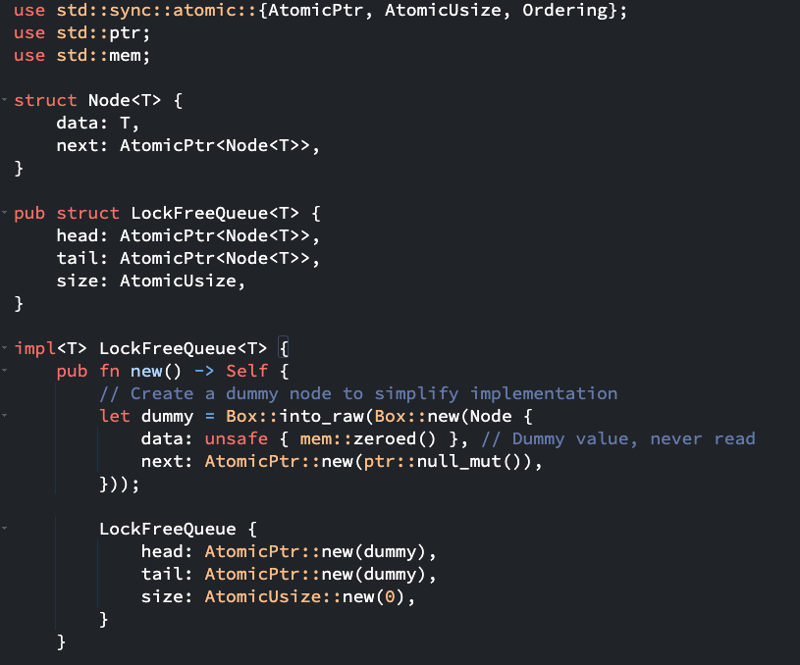
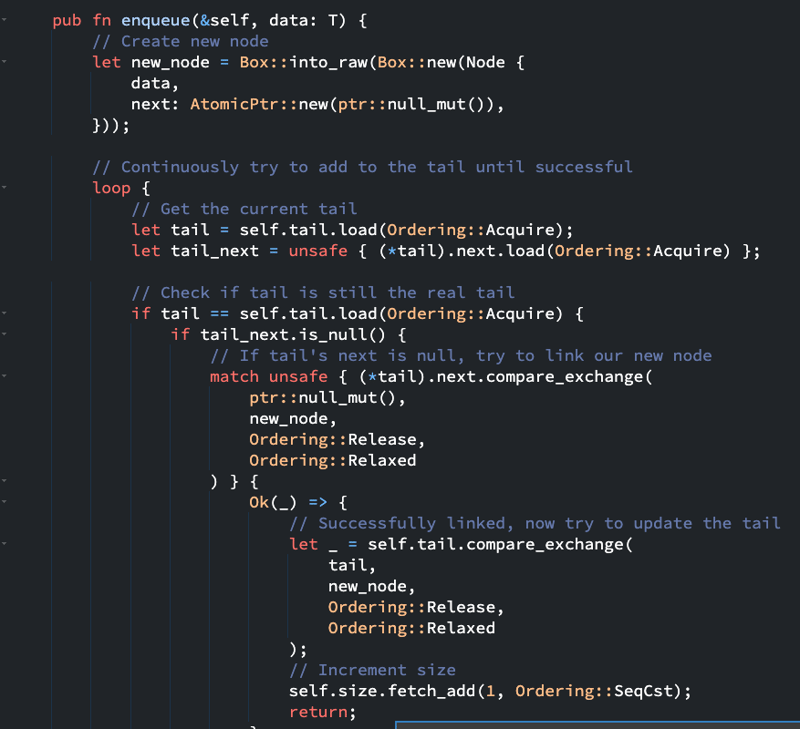
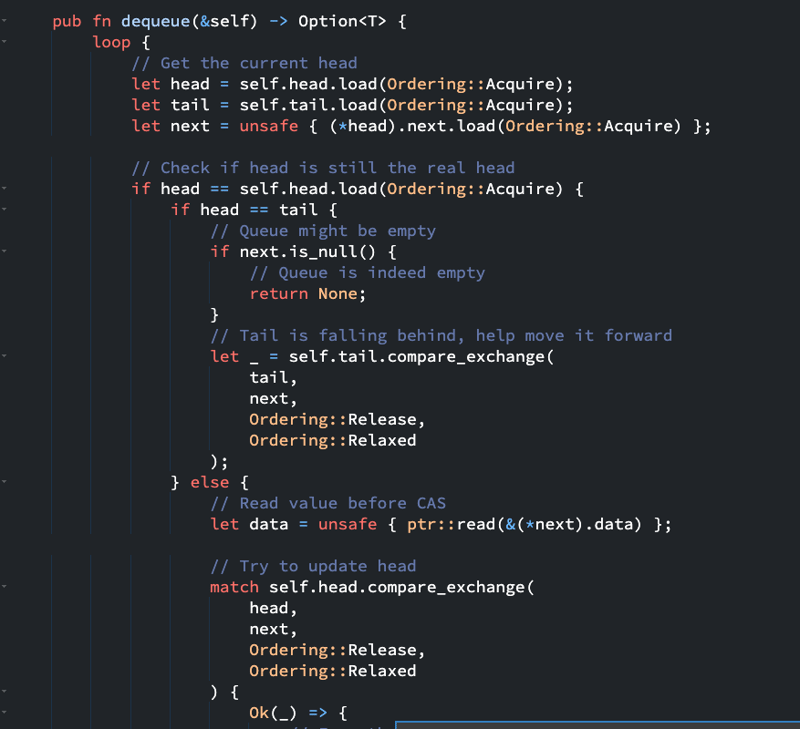
Why use them? Well for the same reason we're discussing this topic in depth, for low latency computations. If you want to be specific, here are the reasons
1) Elimination of Context Switching - When threads are blocked on locks, the operating system has to perform a context switch to another thread.
2) Resilience against thread failures - if one thread stalls or fails, other threads continue
3) Cache efficiency - Lock-free data structures and algorithms can be designed to minimise cache-line sharing
Multithreading Patterns for Performance
When low-latency is a concern, it isn't just about spinning up multiple threads/processes and hoping for the best, we also have to take in considerations how these threads will need to interact with each other. The right pattern makes a big difference between a system that breaks down when theres traffic in coming and a maintains consistent low latency.
Lets go over some multithreading patterns to go over what exactly this entails
Readers-Writer Pattern
This pattern optimises for scenarios where reads are much more frequent than writes - in the context of HFT systems, it's perfect for order book data where many strategies need to read the current state, but updates happen less frequently.
Imagine a popular blog post that thousands of people are reading, but occasionally an editor needs to update it. You wouldn't want to lock out all readers while the editor works!
This pattern is like having a special system where:
- Multiple readers can view the content simultaneously (like users browsing your website). When an editor needs to make changes, they get exclusive access briefly. Once editing is done, all readers immediately see the new version
Producer-Consumer Pattern
This is a fundamental pattern for building pipeline-style architectures that minimise latency while maintaining clean separation of concerns.
Using channels (mpsc::channel) provides:
- Lock-free communication between components
- Automatic back-pressure handling
- Clean decoupling between data producers and consumer
Think of this like the relationship between your API backend and frontend. Your backend produces data that your frontend consumes, but they work at different speeds.
This pattern creates a buffer between components:
- Producers (like your backend) can generate data at their own pace
- Consumers (like your frontend) process it when they're ready
- A channel between them handles timing differences
Shared Ownership Pattern
Using atomic reference counting (Arc<T>) is crucial for safe concurrent access to shared resources without the overhead of locks.
This pattern:
- Allows safe sharing of read-only or thread-safe data across components
- Eliminates expensive deep copies of data
- Ensures resources are properly cleaned up when no longer needed
If you've used React's context API or Redux, you're familiar with the concept of shared state. This pattern is similar but for memory management.
Instead of copying data between components:
- Multiple threads share references to the same data
- The system tracks how many threads are using the data
- When no one needs it anymore, it's automatically cleaned up
This dramatically reduces memory overhead and improves performance by eliminating expensive copies while maintaining safety.
NUMA-Aware Application Design
NUMA (Non-Uniform Memory Access) architecture is a fundamental concept when designing systems that need to scale across multiple processors. Let me explain this in a way that builds on our previous discussions.
What is NUMA Architecture?
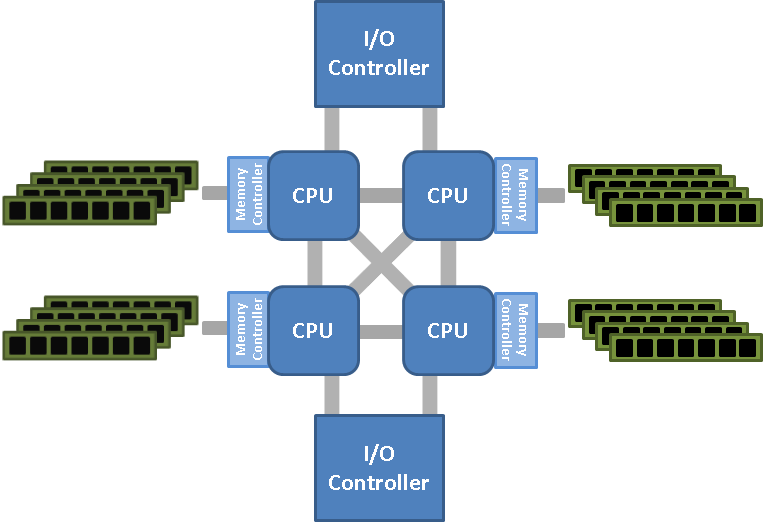
As we discussed earlier, in a NUMA system:
- The computer has multiple CPUs (physical processors)
- Each CPU has its own memory controller and directly attached memory
- Each CPU also has its own L1/L2/L3 cache hierarchy
- Memory access speeds vary depending on whether a CPU is accessing its local memory or remote memory (belonging to another CPU)
This creates a critical performance consideration: accessing local memory might be 1.5-3x faster than accessing remote memory, depending on the system.
Why NUMA Awareness Matters
In a high-frequency trading system, these access differences can dramatically impact performance:
- A thread accessing remote memory might experience 30-100ns additional latency per access. For applications making millions of memory accesses, this adds up quickly
- Memory-intensive operations might run twice as slow if data is placed inappropriately
- Cache coherency traffic across NUMA nodes creates additional overhead
Key NUMA-Aware Design Principles
Thread and Memory Locality
- Keep threads and their data on the same NUMA node
- Minimise cross-node communication and data sharing
- Use thread affinity to bind threads to specific CPUs
Memory Allocation Strategies
- Allocate memory on the same node where the processing thread runs
- Use NUMA-specific allocation functions when available
- Consider first-touch policies (memory is allocated on the node of the thread that first writes to it)
Data Partitioning
- Divide work and data along NUMA boundaries
- Each node handles a specific subset of the workload
- Minimize shared data structures that cross NUMA boundaries
NUMA-Aware Data Structures
- Design data structures that respect NUMA topology
- Consider node-local queues feeding into global coordination
- Avoid false sharing across NUMA boundaries
Translating Low-Latency Principles to AWS
Understanding hardware-level performance concepts doesn't just matter for HFT systems - they can significantly improve latency-sensitive applications in the cloud. Even though HFT developers work on their critical infrastructure on premises instead of the cloud, the principles that they operate on can be translated to the workflow of Backend and Cloud Engineers.
Here's how to apply these principles when developing on AWS:
CPU Cache Optimisation in the Cloud
Instance Selection: Choose compute-optimised instances (c7g, c6g) with higher CPU-to-memory ratios for cache-sensitive workloads
Data Locality: Structure your applications to maintain data locality even in virtualised environments
Workload Placement: Run related services on the same instance to benefit from shared L3 cache
Bare Metal Options: For critical paths, consider AWS bare metal instances to eliminate hypervisor overhead and gain direct access to physical CPU caches
Memory Ordering and Atomics in Distributed Systems
Single-Instance Performance: Optimise your critical paths using the atomics and memory ordering techniques on high-CPU instances
Service Boundaries: Design service interfaces to minimise cross-process synchronisation needs
Local Processing: Process data where it's stored whenever possible to avoid network round-trips
Consistent Instance Types: Use the same instance family for services that need predictable memory behaviour
Lock-Free Programming in AWS
Serverless Coordination: Use DynamoDB with optimistic concurrency control instead of traditional locks
SQS FIFO Queues: Leverage SQS FIFO queues for producer-consumer patterns with guaranteed ordering
Lambda Concurrency: Design Lambda functions to be truly independent, avoiding shared state that requires locking
ElastiCache Redis: Use Redis atomic operations for distributed coordination instead of application-level locks
Multithreading Patterns for AWS Services
Readers-Writer Pattern: Implement with DynamoDB's strongly consistent vs. eventually consistent reads
Producer-Consumer: Use SQS and SNS for decoupled, high-throughput communication
Shared Ownership: Leverage ElastiCache for shared state across distributed components
NUMA-Aware Design in AWS
Placement Groups: Use cluster placement groups to ensure instances run on the same underlying hardware with low-latency networking
Enhanced Networking: Enable ENA (Elastic Network Adapter) for improved latency between instances
Topology Awareness: Create availability zone-aware designs that keep related components physically close
Instance Size Selection: Choose appropriately sized instances - splitting a workload across multiple smaller instances might hit NUMA-like boundaries
AWS-Specific Optimisations
Direct VPC Endpoints: Reduce latency by connecting directly to AWS services without traversing the public internet
Enhanced Networking: Use Elastic Network Adapter (ENA) and Elastic Fabric Adapter (EFA) for high-throughput, low-latency networking
Nitro System: Leverage AWS Nitro-based instances for hardware acceleration and reduced virtualisation overhead
Graviton Processors: Consider ARM-based Graviton instances which can offer better performance characteristics for certain workloads
By applying these low-level performance principles to your AWS architecture, you can build systems that achieve consistent low latency even in virtualised cloud environments. The key is understanding that while the physical hardware may be abstracted, the principles of CPU caching, memory access patterns, and concurrent programming still directly impact your application's performance.

Top comments (0)