Introduction
In today's data-driven world, the ability to understand and process text semantically has become increasingly important. Vector embeddings provide a powerful way to represent text as numerical vectors, enabling semantic search, content recommendation, and other advanced natural language processing capabilities. This blog post explores how to leverage Google's Vertex AI to generate vector embeddings directly within Google Apps Script.
Straight to the code at https://github.com/jpoehnelt/apps-script/tree/main/projects/vector-embeddings.
What are Vector Embeddings?
Vector embeddings are numerical representations of text (or other data) in a high-dimensional space. Unlike traditional keyword-based approaches, embeddings capture semantic meaning, allowing us to measure similarity between texts based on their actual meaning rather than just matching keywords.
For example, the phrases "I love programming" and "Coding is my passion" would be recognized as similar in an embedding space, despite having no words in common.
Why Use Vertex AI with Apps Script?
Google Apps Script provides a powerful platform for automating tasks within Google Workspace. By combining it with Vertex AI's embedding capabilities, you can:
- Build semantic search functionality in Google Sheets or Docs
- Create content recommendation systems
- Implement intelligent document classification
- Enhance chatbots and virtual assistants
- Perform sentiment analysis and topic modeling
Implementation Guide
Prerequisites
- A Google Cloud Platform account with Vertex AI API enabled
- A Google Apps Script project
Step 1: Set Up Your Project
First, you'll need to set up your Apps Script project and configure it to use the Vertex AI API. Make sure to store your project ID in the script properties. You can do this by going to the Script Editor, clicking on the "Script properties" icon, and adding your project ID.
Step 2: Generate Embeddings
The core functionality is generating embeddings from text. Here's how to implement it:
/**
* Generate embeddings for the given text.
* @param {string|string[]} text - The text to generate embeddings for.
* @returns {number[][]} - The generated embeddings.
*/
function batchedEmbeddings_(
text,
{ model = "text-embedding-005" } = {}
) {
if (!Array.isArray(text)) {
text = [text];
}
const token = ScriptApp.getOAuthToken();
const PROJECT_ID = PropertiesService.getScriptProperties().getProperty("PROJECT_ID");
const REGION = "us-central1";
const requests = text.map((content) => ({
url: `https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/publishers/google/models/${model}:predict`,
method: "post",
headers: {
Authorization: `Bearer ${token}`,
"Content-Type": "application/json",
},
muteHttpExceptions: true,
contentType: "application/json",
payload: JSON.stringify({
instances: [{ content }],
parameters: {
autoTruncate: true,
},
}),
}));
const responses = UrlFetchApp.fetchAll(requests);
const results = responses.map((response) => {
if (response.getResponseCode() !== 200) {
throw new Error(response.getContentText());
}
return JSON.parse(response.getContentText());
});
return results.map((result) => result.predictions[0].embeddings.values);
}
Step 3: Calculate Similarity Between Embeddings
Once you have embeddings, you'll want to compare them to find similar content. The cosine similarity is a common metric for this purpose. It measures the cosine of the angle between two vectors. The cosine of the angle is calculated as the dot product of the vectors divided by the product of their magnitudes. The cosine similarity takes values between -1 (completely dissimilar) and 1 (completely similar) and is defined as cosine similarity = dot product / (magnitude of x * magnitude of y).
/**
* Calculates the cosine similarity between two vectors.
* @param {number[]} x - The first vector.
* @param {number[]} y - The second vector.
* @returns {number} The cosine similarity value between -1 and 1.
*/
function similarity_(x, y) {
return dotProduct_(x, y) / (magnitude_(x) * magnitude_(y));
}
function dotProduct_(x, y) {
let result = 0;
for (let i = 0, l = Math.min(x.length, y.length); i < l; i += 1) {
result += x[i] * y[i];
}
return result;
}
function magnitude_(x) {
let result = 0;
for (let i = 0, l = x.length; i < l; i += 1) {
result += x[i] ** 2;
}
return Math.sqrt(result);
}
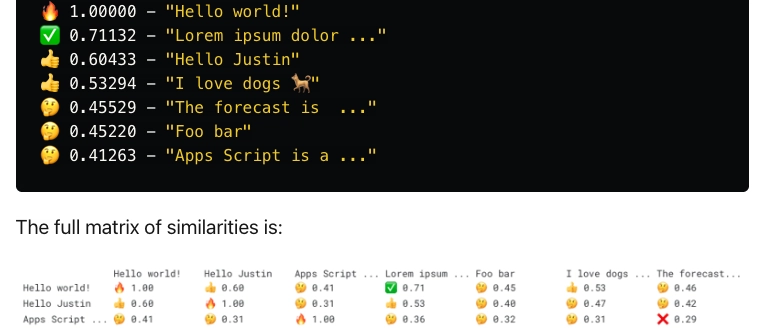
I tested out the code with a small corpus of texts and it worked well.
🔍 Searching for "Hello world!" ...
🔥 1.00000 - "Hello world!"
✅ 0.71132 - "Lorem ipsum dolor ..."
👍 0.60433 - "Hello Justin"
👍 0.53294 - "I love dogs 🐕"
🤔 0.45529 - "The forecast is ..."
🤔 0.45220 - "Foo bar"
🤔 0.41263 - "Apps Script is a ..."
You might be wondering why Hello Justin is ranked lower than Lorem ipsum ... when searching for Hello world!. While Hello Justin contains the word Hello, the meaning of Hello world! is more similar to Lorem ipsum ... as both are common phrases used in the context of software development. This will vary by the model used and how it was trained.
The full matrix of similarities is:

Step 4: Building a Simple Semantic Search
Here's how to create a basic semantic search function:
function semanticSearch(query, corpus) {
// Generate embedding for the query
const queryEmbedding = batchedEmbeddings_([query])[0];
// Create or use existing index
const index = corpus.map((text) => ({
text,
embedding: batchedEmbeddings_([text])[0],
}));
// Calculate similarities
const results = index.map(({ text, embedding }) => ({
text,
similarity: similarity_(embedding, queryEmbedding),
}));
// Sort by similarity (highest first)
return results.sort((a, b) => b.similarity - a.similarity);
}
Real-World Applications
Example 1: Semantic Search in Google Sheets
You can build a custom function that allows users to search through data in a spreadsheet based on meaning rather than exact keyword matches:
/**
* Custom function for Google Sheets to perform semantic search
* @param {string} query The search query
* @param {Range} dataRange The range containing the text to search through
* @param {number} limit Optional limit on number of results
* @return {string[][]} The search results with similarity scores
* @customfunction
*/
function SEMANTIC_SEARCH(query, dataRange, limit = 5) {
const corpus = dataRange.getValues().flat().filter(Boolean);
const results = semanticSearch(query, corpus);
return results
.slice(0, limit)
.map(({ text, similarity }) => [text, similarity]);
}
Example 2: Document Classification
You can use embeddings to automatically categorize documents:
/**
* Document classification using embeddings
* @param {string} document The document to classify
* @param {Array<string>} categories List of possible categories
* @return {string} The most similar category
*/
function classifyDocument(document = "I love dogs", categories = ["Software", "Animal", "Food"]) {
const docEmbedding = batchedEmbeddings_([document])[0];
const categoryEmbeddings = batchedEmbeddings_(categories);
const similarities = categoryEmbeddings.map((catEmbedding, index) => ({
category: categories[index],
similarity: similarity_(docEmbedding, catEmbedding)
}));
// Return the most similar category
const results = similarities.sort((a, b) => b.similarity - a.similarity)[0].category;
console.log(results);
return results;
}
When this is run with the default parameters, it will return Animal.
Performance Considerations
When working with vector embeddings in Apps Script, keep these tips in mind:
- Batch Processing: Generate embeddings in batches to reduce API calls.
- Caching: Store embeddings in properties service or a spreadsheet to avoid regenerating them.
- Dimensionality: Consider using a lower dimensionality for faster processing if accuracy is less critical.
- Quota Limits: Be mindful of Apps Script's quotas for UrlFetchApp calls and execution time.
Note: You will likely want to cache embeddings for performance and cost savings.
Conclusion
Vector embeddings represent a powerful tool for bringing advanced natural language processing capabilities to your Google Workspace environment. By combining Google Apps Script with Vertex AI, you can create intelligent applications that understand the semantic meaning of text, enabling more sophisticated search, recommendation, and classification systems.
The code examples provided in this blog post should help you get started with implementing vector embeddings in your own Apps Script projects. As you explore this technology further, you'll discover even more creative ways to leverage the power of AI within your workflows.

Top comments (1)
Let me know if you have any questions!