
A sizable chunk of time has passed since Part 2 of this series. In the months since my last post, I’ve started a new open source project (more to come later), travelled, and stood up a small, manageable data lake. I’d like to say that my delay in bringing you the engrossing (or boring? YMMV) content you’ve come to expect from me is the result of me back-loading 2019 with a whirlwind of activity; the reality, I’m afraid, has more to do with indolence than anything else. Sorry.
In this post, I’ll focus on my recent use of Amazon Athena — and, as a matter of necessity, Amazon S3 and AWS Glue — to explore my Apple Health data and decide whether or not to incorporate it into my unreasonably captivating personal website.
A Bit About re:Invent 2019
The aforementioned data lake is the same data lake I reviewed during the demo portion of my DevChat at AWS re:Invent 2019, the slides for which are available on Slideshare. I won’t get into a full-blown re:Invent recap, but I will say that I had a great time at the conference — I’ve been using one word in particular to describe the experience: overwhelming. I’m thankful to AWS for giving me the opportunity to attend and meet some truly impressive people; I’m also thankful to Handshake for giving me the space to stretch myself, talk about the company’s mission, and walk purposefully around Vegas for a few days — which, incidentally, is a great way to close activity rings.

Tracking More Than Steps
If you’ve got an iPhone, you’ve got Apple Health data; if you’ve got an Apple Watch, too, then you’ve got even more data. The Health app consolidates data about your physical activity, heart rate, etc. from your iPhone, Apple Watch, and other third-party apps into a singular data repository.
You can use the Health app to export that data so that you can play around with it yourself. What the export provides is an unwieldy set of XML files whose size is directly related to the duration of your relationship with your iPhone — if, for example, you’ve been an Apple fangirl since iOS8 (when the Health app was introduced), then you might have 5 years worth of data on your hands.
Health app data isn’t easy to parse without employing some ETL wizardry. Before authoring while statements, I looked around to see if anyone had already decided to hazard an attempt at processing the files, and I quickly came across Mark Koester’s post entitled How to Export, Parse and Explore Your Apple Health Data With Python. I read through all of the rigor involved in making sense of the data, and realized that a subset of AWS services could be employed to reduce my level of effort if I introduced a data lake into the equation.
Data Lakes Seem Complicated
While the idea of deploying a data lake may seem daunting to the uninitiated, it can actually be a fairly straightforward affair, especially in use cases like this one.
Before we dive into my setup, let’s first take a look at a definition. As AWS puts it:
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics — from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
The key takeaway from that definition is that a data lake is just a centralized repository — you don’t, for example, need Redshift or QuickSight to build a data lake, but those tools can help you tease insights out of the data that is stored in your repository.
Data Storage & Ingestion
I decided to keep my Apple Health data in S3, a service that is at the heart of data lakes — and a host of other services, really — that live in AWS. It’s a cost effective, scalable, durable solution that allows you to store all kinds of data and define lifecycle policies to optimize storage costs. The data in my buckets is encrypted with the AWS Key Management Service (AWS-KMS). Pro tip: always encrypt your data in a data lake both while its sitting around doing nothing (at rest) and while its moving through your system (in transit).
A concept common among data lakes is the idea of zones. You’ll see different names for zones used in data lakes across industries and use cases, but the main idea is that each zone represents data as it exists in varying states of refinement. Zones are generally represented by S3 buckets. For example, raw data — data in its original format — is kept in a raw zone.
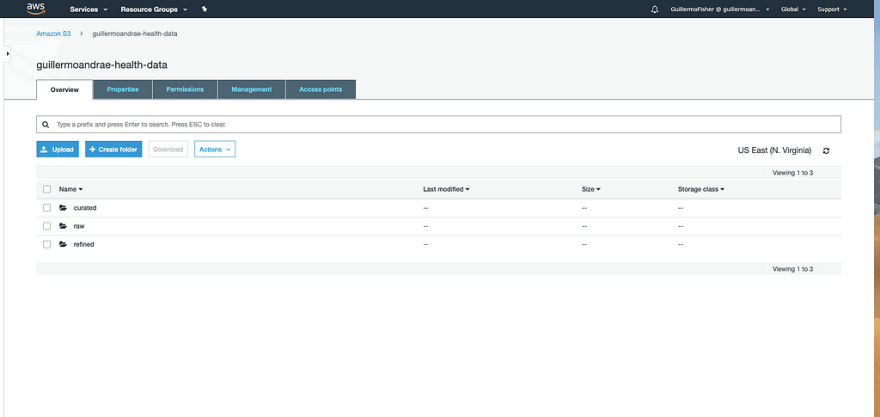
My solution has 3 zones: raw, refined, and curated. I stored my raw health data in a bucket at this path: S3://guillermoandrae-health-data/raw/2019–10–10(it’s worth mentioning here that the folder structure you use when storing your data can affect the performance of your Athena queries; if you’re interested in solutions more complex than the current one, you should do some reading on partitioning).
On the ingestion front: I don’t know of a way to automatically download my health data (I’m open to suggestions), so I manually downloaded it and pushed it to S3 through the AWS administrative console. You’d usually want to automate the upload process.
Move & Transform
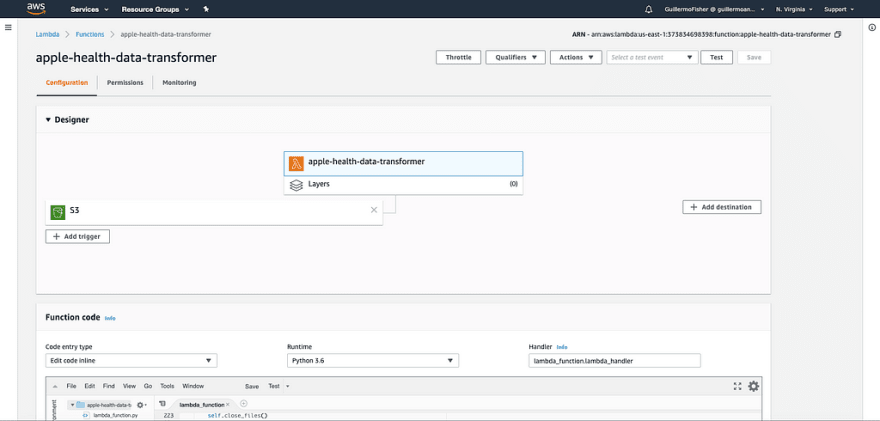
The Apple Health Extractor outputs a number of CSV files, which I stored in the refined zone. On the first go-round, I pushed the CSVs to that zone manually. In order to automate the execution of the script, I uploaded a modified version of the code to a Lambda function that watches the raw bucket and dumps the CSVs out into the refined bucket.
Crawling & Cataloging
In my headier programming days, I spent a ton of time writing ETL (Extract, Transform, Load) code. I also had experiences with tools that claimed to magically transform data sets from one format to another, only to have to write code to clean up the shoddy job done by those tools. When I heard about Glue, I was definitely pessimistic; seeing it in action, though, was surprising.
AWS Glue is a serverless, pay-as-you-go ETL service. You can set Glue up to crawl and catalog the data in your S3 buckets. Tell it the data location and data format, and Glue will populate your data catalog, which is stored in a Presto database that you don’t have to manage. Incredibly efficient, incredibly useful.

You’ll need to follow the prompts, define an IAM role that can be used by Glue to access data in your buckets, and name the database where your data catalog will exist.
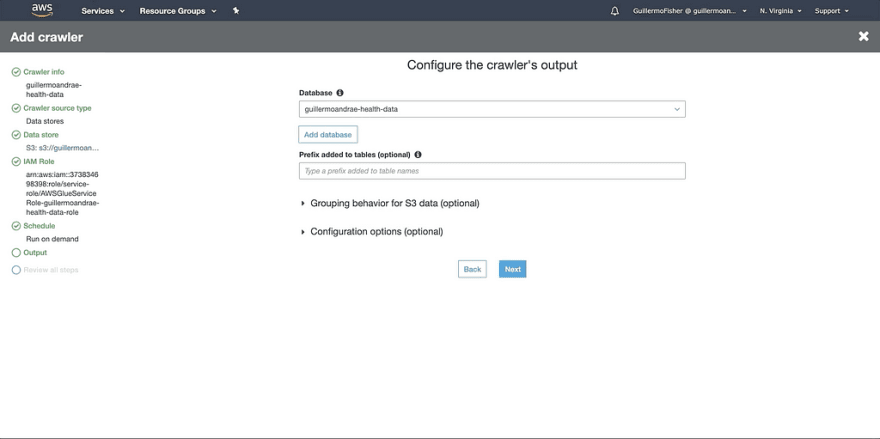
Simple CSVs are easy for Glue to parse — there are a few built-in classifiers for various data formats (including CSV) that allow you to get started ETL-ing stuff right away. I was able to crawl my data without issue.
Data Exploration
With my data cataloged, I was ready to begin digging into it with Athena. Amazon Athena is a serverless interactive query service that can be used to analyze data stored in S3. Once a Glue data catalog is populated, you can use Athena to write SQL queries and perform ad-hoc data analysis. Recent updates to Athena make it possible to execute SQL queries across databases, object storage, and custom data sources using the federated query feature.

I ran some queries to figure out which of the columns would be most useful. In the GIF above, I paid close attention to the type field and was able to figure out what kinds of metrics could be found in the health data. Further investigation led me to the unit, value, and date-related fields creationdate, startdate, and enddate. I was ultimately able to figure out how to get some aggregates together that might be useful (check out Mark Koester’s post for more on that).
So… Is This Data Helpful?
Nah. It’s not. It’s kind of interesting, but it doesn’t tell as compelling a story as I thought it would. I couldn’t find any strong correlations between my physical activity and my social media activity. I’d intended to convert the refined data into Parquet — a columnar storage format — and store the files in my curated zone, then import those files into Redshift for data warehousing purposes. I got as far as the Parquet conversion, but decided it wasn’t worth it to incur the costs associated with spinning up Redshift servers.
And that’s fine, I think. I was able to test out a hypothesis, and it cost me just about nothing. It’s OK that the process led me to the conclusion that I am, in fact, quantifiably boring.
A Final Word on Data Lakes
I don’t want to be irresponsible, so I won’t end this post without pointing you to at least one good data lake resource and mentioning AWS Lake Formation, which will handle a lot of the dirty work of setting up a data lake for you. I should also point out that my data lake lacked the level of automation and data governance that are necessary to maintain the integrity and usefulness of a data lake, so don’t mimic my setup for anything even mildly important.
Next Steps
It’s time to start writing some code. In the next post, I’ll talk about the AWS SDK for PHP and my mysterious open source project.
Stay tuned for Part 4 in the series, friends!

Top comments (0)