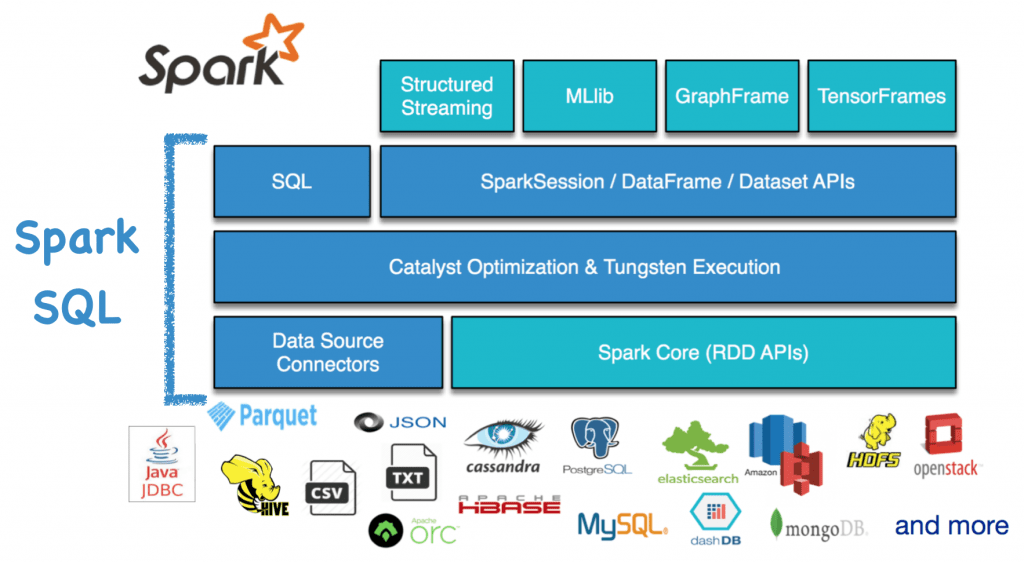
Spark SQL
Spark SQL lets you query structured data inside Spark programs, using either SQL or a familiar DataFrame API.
DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
Spark SQL supports the HiveQL syntax as well as Hive SerDes and UDFs, allowing you to access existing Hive warehouses.
Spark SQL includes a cost-based optimizer, columnar storage and code generation to make queries fast.
DataFrames
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python but with richer optimizations under the hood.
DataFrame is represented by a Dataset of Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row].
DataFrames are untyped and the elements within DataFrames are Rows.
Below is a sample dataframe which is composed of rows & columns -
scala> df.show
+---------------+--------+-----------+--------------------+--------+
| capital|currency|independent| name| region|
+---------------+--------+-----------+--------------------+--------+
| Canberra| AUD| true| Australia| Oceania|
| London| GBP| true| United Kingdom| Europe|
|Washington D.C.| USD| true|United States of ...|Americas|
| Paris| EUR| true| France| Europe|
| Tokyo| JPY| true| Japan| Asia|
| Dublin| EUR| true| Ireland| Europe|
+---------------+--------+-----------+--------------------+--------+
Datasets
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine.
Datasets are typed distributed collections of data and it unifies DataFrame and RDD APIs.
Datasets require structured/semi-structured data. Schemas and Encoders are part of Datasets.
Comparisons
RDD vs DataFrames vs Datasets
| RDD | DataFrames | Datasets |
|---|---|---|
| Functional transformations | Relational | Functional & Relational transformations |
| No type safety | No type safety | Type-safe |
| No built-in optimization | Catalyst query optimization | Catalyst query optimization** |
| In-memory JVM objects resulting in GC & java serialization overheads | Tungsten execution engine - Off-Heap Memory Management using binary in-memory data representation | Tungsten execution engine - Off-Heap Memory Management using binary in-memory data representation |
| JIT code generation | JIT code generation | |
| Sorting/suffling without deserialization | Sorting/suffling without deserialization | |
| No encoders | Encoders - generate byte code and provide on-demand access to attributes without the need for deserialization |
DataFrames vs Datasets
| DataFrames | Datasets |
|---|---|
| DataFrames are untyped - No type check by the compiler | Datasets are typed distributed collections of data - compile-time type safety |
| Transformations on dataFrames are untyped | Datasets include both untyped and typed transformations |
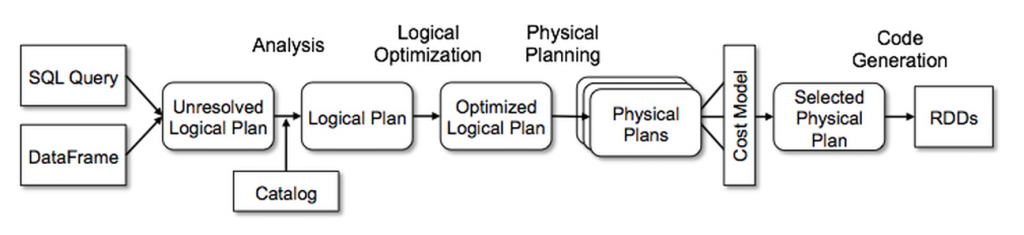
Catalyst Optimizer
At the core of Spark SQL is the Catalyst optimizer, which leverages advanced programming language features (e.g. Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer.
Catalyst supports both rule-based and cost-based optimization.
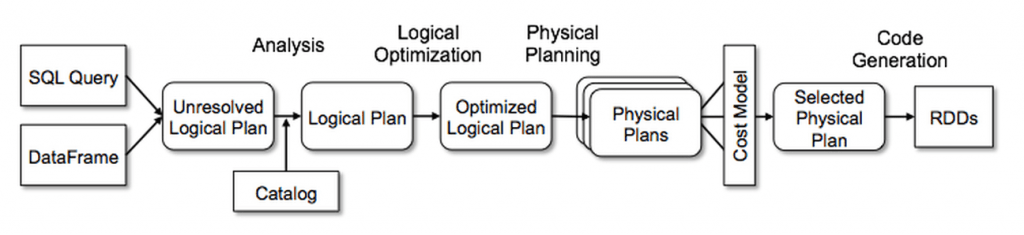
Image from https://databricks.com/wp-content/uploads/2018/05/Catalyst-Optimizer-diagram.png
On our sample dataset of countries and currencies, let’s find the most used currency. We will perform a group by operation on the currency column and then order it in descending order based on the counts.
scala> df.groupBy("currency").count().orderBy(desc("count")).show()
+--------+-----+
|currency|count|
+--------+-----+
| EUR| 2|
| JPY| 1|
| AUD| 1|
| GBP| 1|
| USD| 1|
+--------+-----+
Let’s see the catalyst optimization for the above query.
scala> df.groupBy("currency").count().orderBy(desc("count")).explain(extended=true)
== Parsed Logical Plan ==
'Sort ['count DESC NULLS LAST], true
+- Aggregate [currency#149], [currency#149, count(1) AS count#202L]
+- Relation[capital#148,currency#149,independent#150,name#151,region#152] json
== Analyzed Logical Plan ==
currency: string, count: bigint
Sort [count#202L DESC NULLS LAST], true
+- Aggregate [currency#149], [currency#149, count(1) AS count#202L]
+- Relation[capital#148,currency#149,independent#150,name#151,region#152] json
== Optimized Logical Plan ==
Sort [count#202L DESC NULLS LAST], true
+- Aggregate [currency#149], [currency#149, count(1) AS count#202L]
+- Project [currency#149]
+- Relation[capital#148,currency#149,independent#150,name#151,region#152] json
== Physical Plan ==
*(3) Sort [count#202L DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(count#202L DESC NULLS LAST, 200)
+- *(2) HashAggregate(keys=[currency#149], functions=[count(1)], output=[currency#149, count#202L])
+- Exchange hashpartitioning(currency#149, 200)
+- *(1) HashAggregate(keys=[currency#149], functions=[partial_count(1)], output=[currency#149, count#207L])
+- *(1) FileScan json [currency#149] Batched: false, Format: JSON, Location: InMemoryFileIndex[file:/C:/Users/ranganathanh/Downloads/countries.json], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<currency:string>
Here,
Analyzed Logical Plan - Resolved relations, references, aliases and updated attribute nullability.
Optimized Logical Plan - Introduced a projection of column “currency” as we are interested in only that field for the rest of our operations.
Physical Plan - In the final physical plan, notice the ReadSchema operation as part of FileScan. It only reads in the “currency” field and ignores the rest.
Code references:
Tungsten Execution Engine
Tungsten improves the efficiency of memory and CPU usage.
Spark explicitly manages memory and converts most operations to operate directly against binary data.
Columnar layout for memory data avoids unnecessary I/O and accelerates analytical processing performance on modern CPUs and GPUs.
Vectorization allows the CPU to operate on vectors, which are arrays of column values from multiple records. This takes advantage of modern CPU designs, by keeping all pipelines full to achieve efficiency.
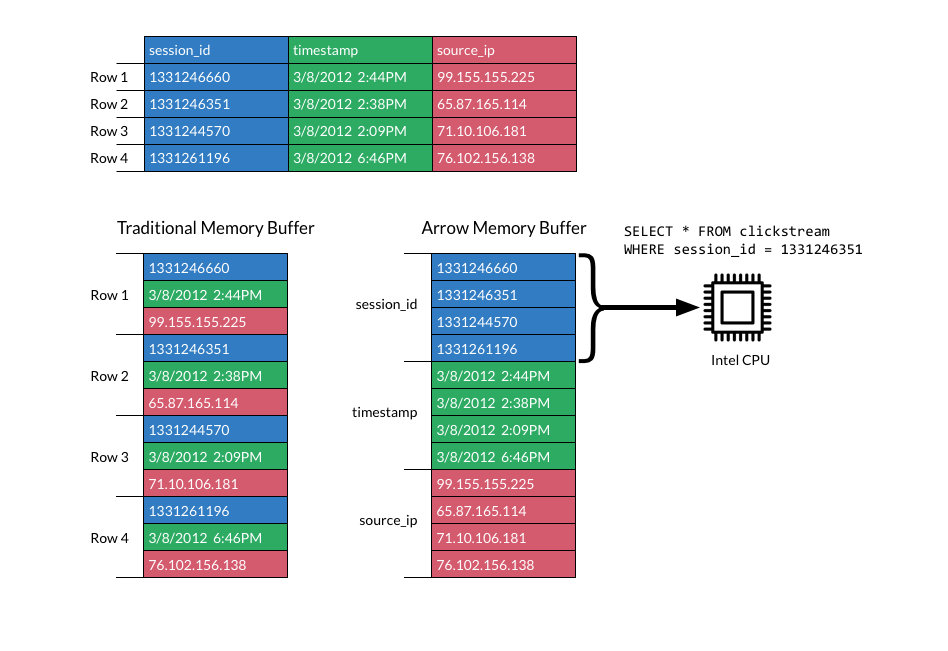
Image from https://arrow.apache.org/img/simd.png
Tungsten also performs -
[1] Whole-Stage Code-Generation - Instead of having each operator as an individual function, combine and compile all of those stages into single function.
[2] Cache Locality - Tungsten uses algorithms and cache-aware data structures that exploit the physical machine caches at different levels - L1, L2, L3.
[3] Loop unrolling and SIMD - Optimize Apache Spark’s execution engine to take advantage of modern compilers and CPUs’ ability to efficiently compile and execute simple for loops.
Structured Streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine.
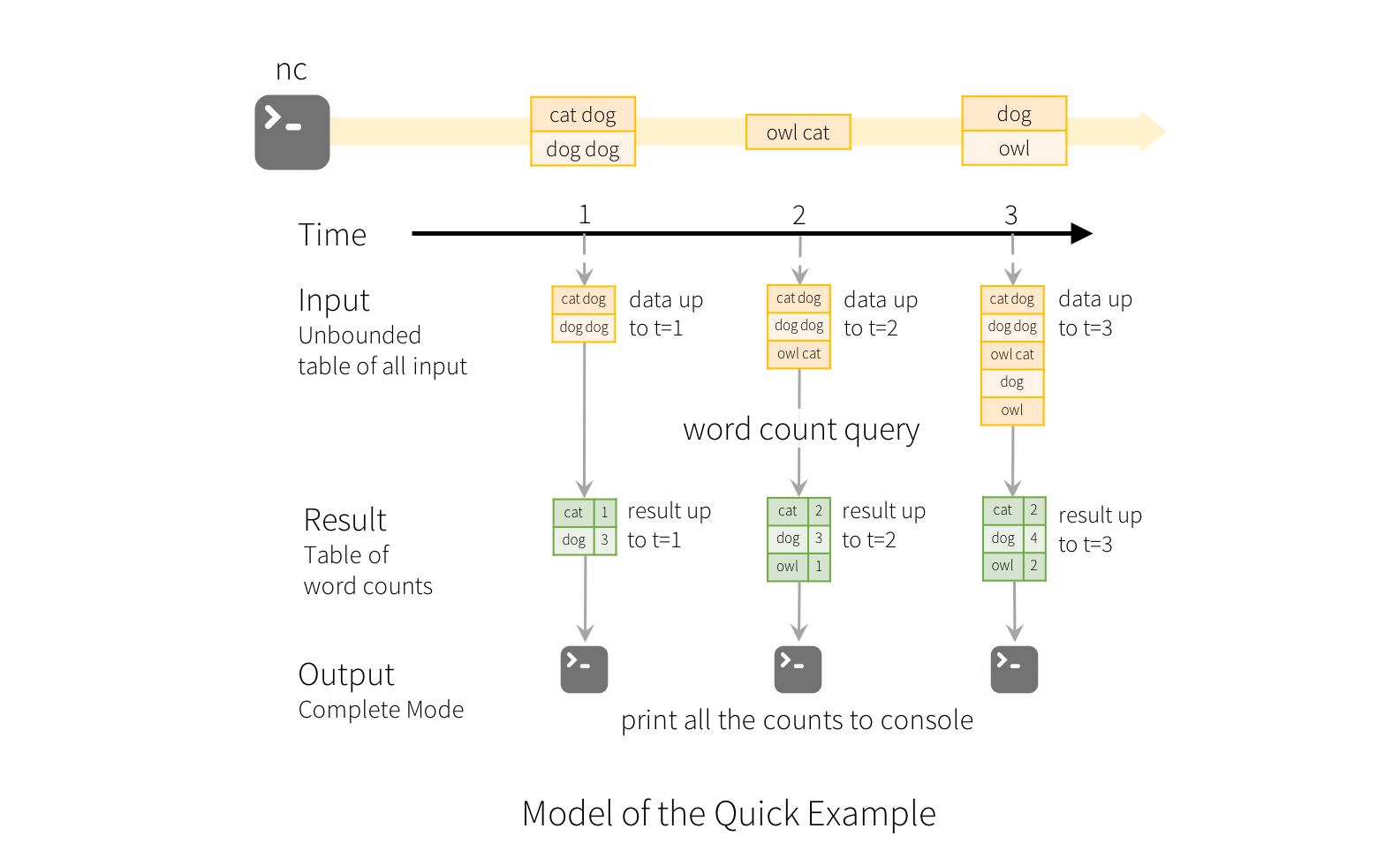
The key idea in Structured Streaming is to treat a live data stream as a table that is being continuously appended. This leads to a new stream processing model that is very similar to a batch processing model.
For a word count example, when the query is started, Spark will continuously check for new data from the socket connection. If there is new data, Spark will run an “incremental” query that combines the previous running counts with the new data to compute updated counts.
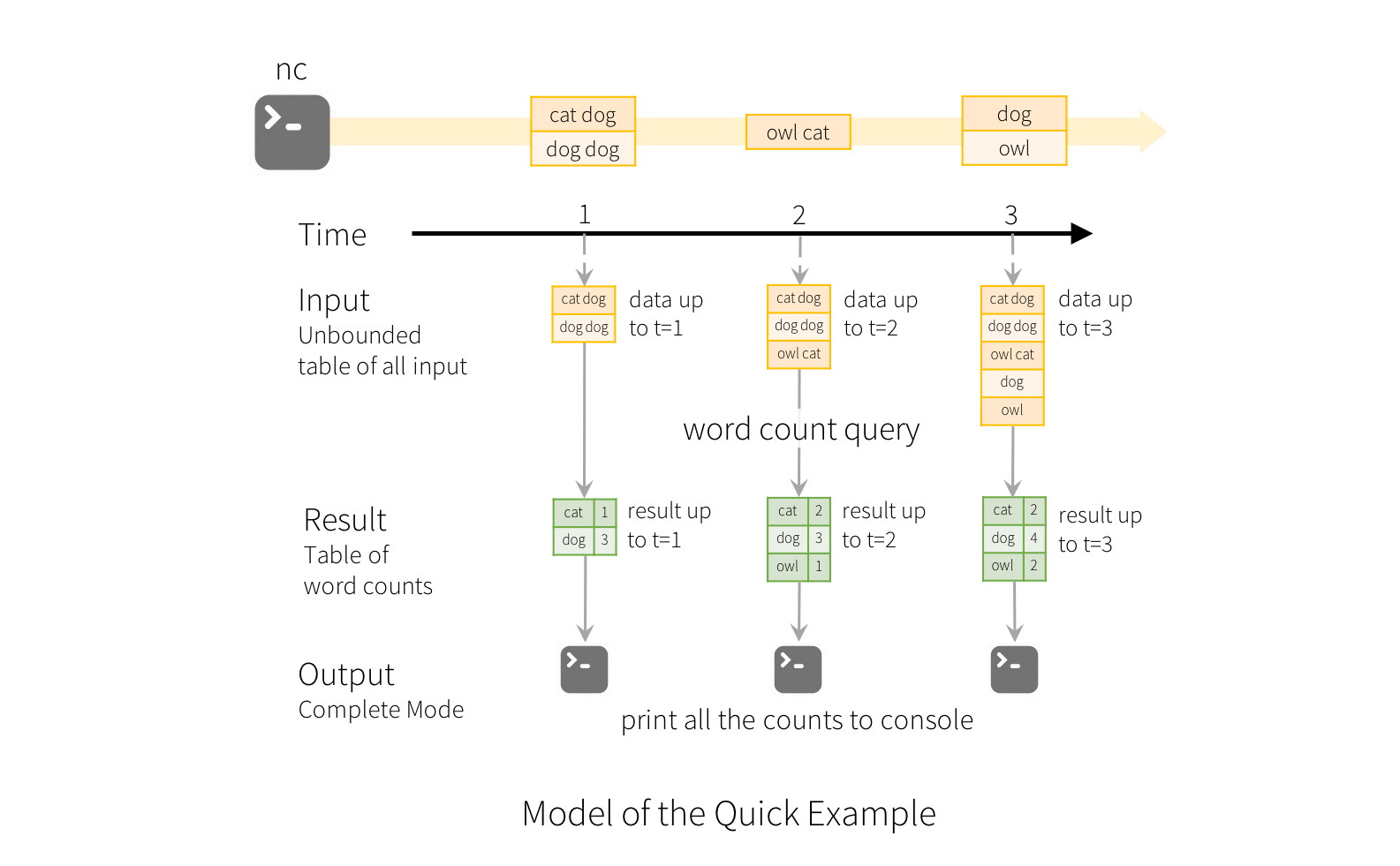
Image from https://spark.apache.org/docs/latest/img/structured-streaming-example-model.png
You can use the common entry point SparkSession to create streaming DataFrames/Datasets from streaming sources, and apply the same operations on them as static DataFrames/Datasets.
There are a few built-in sources, e.g. for files, supported file formats are text, csv, json, orc, parquet.
Encoders
Encoder is the fundamental concept in the serialization and deserialization (SerDe) framework.
Encoders are used to convert a JVM object of type T to and from the internal Spark SQL representation.
Encoders know the schema of the records. This is how they offer significantly faster serialization and deserialization (comparing to the default Java or Kryo serializers).
So every data set has encoders to go along with it. And these encoder things are extremely specialized, optimized code generators that generate custom bytecode for serialization and deserialization of your data.
And this special representation is Sparks internal Tungsten’s binary format which allows these operations to happen on already serialized data greatly improving the memory utilization.
What to use ?
| RDD | You have unstructured data If your unstructured data cannot to be reformulated to adhere to a schema You need to manage low-level details of RDD computations You have complex data types which can’t be serialized with Encoders |
| DataFrames | You have structured/semi-structured data You need best performance |
| Datasets | You have structured/semi-structured data You need type-safety You need functional APIs You need good performance |
Example
RDD, DataFrames & Datasets have their pros & cons. Let’s see with an example where we will utilize all three of them (Interoperability) to achieve the best performance.
Our datasource is a json file where each line contains json data.
{"name":"Australia","independent":true,"currency":"AUD","capital":"Canberra","region":"Oceania"}
{"name":"United Kingdom","independent":true,"currency":"GBP","capital":"London","region":"Europe"}
{"name":"United States of America","independent":true,"currency":"USD","capital":"Washington D.C.","region":"Americas"}
{"name":"France","independent":true,"currency":"EUR","capital":"Paris","region":"Europe"}
{"name":"Japan","independent":true,"currency":"JPY","capital":"Tokyo","region":"Asia"}
{"name":"Ireland","independent":true,"currency":"EUR","capital":"Dublin","region":"Europe"}
We will make use of Scala language for demonstrating Spark SQL here.
Let’s read the json file using DataFrameReader with the session available in our spark shell.
Spark session available as 'spark'.
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
scala> val df = spark.read.json("C:\\Users\\ranganathanh\\Downloads\\countries.json")
df: org.apache.spark.sql.DataFrame = [capital: string, currency: string ... 3 more fields]
scala> df.printSchema()
root
|-- capital: string (nullable = true)
|-- currency: string (nullable = true)
|-- independent: boolean (nullable = true)
|-- name: string (nullable = true)
|-- region: string (nullable = true)
Notice that the schema is automatically inferred here. For better performance, specify the schema instead of using schema inference.
DataFrameReader accepts a StructType object for schema. So, we construct it as below.
scala> import org.apache.spark.sql.types.{BooleanType, StringType, StructField, StructType}
import org.apache.spark.sql.types.{BooleanType, StringType, StructField, StructType}
scala> val schema = StructType(
| Array(
| StructField("name", StringType),
| StructField("independent", BooleanType),
| StructField("currency", StringType),
| StructField("capital", StringType),
| StructField("region", StringType)
| )
| )
schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(independent,BooleanType,true), StructField(currency,StringType,true), StructField(capital,StringType,true), StructField(region,StringType,true))
Now specify the schema while reading the json file.
scala> val df = spark.read.schema(schema).json("C:\\Users\\ranganathanh\\Downloads\\countries.json")
df: org.apache.spark.sql.DataFrame = [name: string, independent: boolean ... 3 more fields]
scala> df.printSchema()
root
|-- name: string (nullable = true)
|-- independent: boolean (nullable = true)
|-- currency: string (nullable = true)
|-- capital: string (nullable = true)
|-- region: string (nullable = true)
Now, we want to get the list of countries which have currency as “EUR”. We’ll explore how this can be achieved using both DataFrame & Dataset API’s.
We already have our dataframe from our previous file reading operation, so, we’ll apply filter and select transformations on it to achieve our result.
scala> df.filter(df("currency").contains("EUR")).select(df("name"), df("currency"), df("capital")).show()
+-------+--------+-------+
| name|currency|capital|
+-------+--------+-------+
| France| EUR| Paris|
|Ireland| EUR| Dublin|
+-------+--------+-------+
You can select and work with columns in three-ways:
[1] Using $ notation e.g. df.filter($"currency".contains("EUR"))
[2] Referring to the dataframe e.g. df.filter(df("currency").contains("EUR"))
[3] Using SQL query string e.g. df.filter("currency == 'EUR'")
Let’s checkout the physical plan of our previous query.
scala> df.filter(df("currency").contains("EUR")).select(df("name"), df("currency"), df("capital")).explain()
== Physical Plan ==
*(1) Project [name#245, currency#247, capital#248]
+- *(1) Filter (isnotnull(currency#247) && Contains(currency#247, EUR))
+- *(1) FileScan json [name#245,currency#247,capital#248] Batched: false, Format: JSON, Location: InMemoryFileIndex[file:/C:/Users/ranganathanh/Downloads/countries.json], PartitionFilters: [], PushedFilters: [IsNotNull(currency), StringContains(currency,EUR)], ReadSchema: struct<name:string,currency:string,capital:string>
We infer two things from our DataFrame approach:
[1] Catalyst query optimization got applied - ReadSchema was reading only the required fields from the file and not all the columns
[2] There is no type checking on the column names we used in the filter and select operations. This will possibly cause runtime errors if the mentioned fields are not present.
Let’s try the same query using Datasets.
To convert the structured data from the file to a Dataset, you need to define case classes in scala.
scala> case class Country(
| name: String,
| independent: Boolean,
| currency: String,
| capital: String,
| region: String
| )
defined class Country
We redefine our file read operation to return a Dataset of type [Country] using the as method.
scala> val ds = spark.read.schema(schema).json("C:\\Users\\ranganathanh\\Downloads\\countries.json").as[Country]
ds: org.apache.spark.sql.Dataset[Country] = [name: string, independent: boolean ... 3 more fields]
Now, we try the same filter and select operations using the Dataset.
scala> ds.filter(country => country.currency.equals("EUR")).select($"name", $"currency", $"capital").show()
+-------+--------+-------+
| name|currency|capital|
+-------+--------+-------+
| France| EUR| Paris|
|Ireland| EUR| Dublin|
+-------+--------+-------+
And the corresponding query plan -
cala> ds.filter(country => country.currency.equals("EUR")).select($"name", $"currency", $"capital").explain()
== Physical Plan ==
*(1) Project [name#297, currency#299, capital#300]
+- *(1) Filter <function1>.apply
+- *(1) FileScan json [name#297,independent#298,currency#299,capital#300,region#301] Batched: false, Format: JSON, Location: InMemoryFileIndex[file:/C:/Users/ranganathanh/Downloads/countries.json], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<name:string,independent:boolean,currency:string,capital:string,region:string>
We can infer below when using a Dataset -
[1] Catalyst query optimization isn’t applied - ReadSchema is reading all the fields from the file. Reason for this is that catalyst cannot infer the operation being performed when you use lamba functions in your filter operations.
[2] You get compile time type safety checks e.g. ds.filter(country => country.currency.equals("EUR")) utilizes the case class.
[3] In your select query you are ending up having to specify column expressions. This is because, Dataset supports both typed and untyped transformations. While filter is a typed transformation, select is an untyped transformation so you lose the type information.
Now we have seen both approaches, I would prefer to stick with the DataFrame API’s for reading files and performing selective transformations to achieve read performance.
I had earlier mentioned about interoperability. Let’s say you have your list of countries which have EUR as their currency.
You want to perform map operations to transform the data so that it can be inserted in a DB. In such a case, it makes sense to convert your DataFrame to a Dataset so that you can reap the benefits of having a case class (Encoders!!!).
Encoders help to perform operations directly on the serialized data and they use internal Spark SQL representation.
All you have to do is to convert your dataframe once you have projected your fields to a dataset using the as method and import the spark implicits object available in your spark session.
import spark.implicits._ automatically creates encoders for your case classes.
df
.filter(df("currency").contains("EUR"))
.select(df("name"), df("currency"), df("capital")).as[Country]
.map(country => {
// your map operation
})
Now, what will you return in your map function ?
Primitive types (Int, S tring, etc) and Product types (case classes) are supported by importing spark.implicits. Support for serializing other types will be added in future releases.
| Returning case class with ciruclar dependency | Will fail as there is no supported encoder for it |
| Returning case class with Option fields | Will fail as there is no supported encoder for it |
Return null value |
You need to wrap it in a Tuple1 object and return it |
You can create custom encoders as well if there is no supported encoder for your return type. You can also create encoders from case class, java beans etc. and specify it in your transformations.
Now, after you have done your transformations you might want to write to a DB and need low level access (or) you don’t have a suitable encoder.
In that case, you can convert your Dataset to a RDD.
df
.filter(df("currency").contains("EUR"))
.select(df("name"), df("currency"), df("capital")).as[Country]
.map(country => {
// your map operation
})
.rdd
You can also convert your RDD to Dataset / DataFrame using toDS() and toDF() methods.
References
https://spark.apache.org/docs/2.2.0/sql-programming-guide.html
https://www.coursera.org/learn/scala-spark-big-data/home/week/4
https://mapr.com/ebook/getting-started-with-apache-spark-v2/assets/Spark2018eBook.pdf
https://mapr.com/blog/tips-and-best-practices-to-take-advantage-of-spark-2-x/
https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
https://spoddutur.github.io/spark-notes/second_generation_tungsten_engine

{kind=link}
{kind=link}
{kind=link}
Oldest comments (0)