
When I started using Git, I did what most people do. I memorized commands to get the job done without really understanding what was happening under the hood. In most cases, I was getting the results I wanted. But I was still frustrated that I was occasionally ‘breaking’ the repo—getting it into a state I didn't expect and not knowing how to fix it.
Is your experience similar?
The shortcut approach to using a repository is an attempt to use a tool without doing the essential homework to learn how it works. In my case, everything ‘clicked’ as soon as I read about the internal data model used by Git. You see, Git is a kind of a database, and one would never be able to work with SQL, for example, without knowing what a table, record, etc. is. Let’s cover the knowledge gap and see a bit of the internals of a Git repository.
.git
Git is a distributed version control software, which means you don’t need an external server to use it. All the data that Git needs is stored in the .git folder. As a Git user, you have no business changing those files, but for the purposes of this article, we’ll take a look inside to see how Git stores the data.
Just after creating the repository with git init, you’ll find inside:
$ ls -R .git
HEAD config description hooks info objects refs
.git/hooks:
applypatch-msg.sample pre-applypatch.sample pre-rebase.sample update.sample
commit-msg.sample pre-commit.sample pre-receive.sample
fsmonitor-watchman.sample pre-merge-commit.sample prepare-commit-msg.sample
post-update.sample pre-push.sample push-to-checkout.sample
.git/info:
exclude
.git/objects:
info pack
.git/objects/info:
.git/objects/pack:
.git/refs:
heads tags
.git/refs/heads:
.git/refs/tags:
Right now, it’s almost empty: we have a few folders, mostly example files for hooks. We will ignore these; our focus in this article will be mostly .git/objects content—the primary data storage in Git.
Blobs
Git stores every single version of each file it tracks as a blob. Git identifies blobs by the hash of their content and keeps them in .git/objects. Any change to the file content will generate a completely new blob object.
The easiest way to create an object is to add an object to the stage. What is in the stage will be part of the next commit. Staging is the “pre-commit” state in git. It’s where we keep files that are not already committed but already tracked by Git.
Example
Let’s create a simple file and make a blob to represent it:
$ echo "Test" > test.txt
With this command, we write “Test” to the test.txt file. To make it a blob, we just need to add it to the stage by running:
$ git add .
After adding our new file to the stage, inside .git/objects, we have:
$ ls -R .git/objects
34 info pack
.git/objects/34:
5e6aef713208c8d50cdea23b85e6ad831f0449
.git/objects/info:
.git/objects/pack:
We have a new folder, 34, and inside that folder a file 5e6aef713208c8d50cdea23b85e6ad831f0449. This is because the content hash is 345e….: the two chars from the front are used as a directory. The content of this file is:
$ cat .git/objects/34/5e6aef713208c8d50cdea23b85e6ad831f0449
xKOR0I-.
It’s compressed for storage efficiency. We can see what’s inside by running the following Git command:
$ git cat-file blob 345e6aef713208c8d50cdea23b85e6ad831f0449
Test
We have only the content inside—no metadata for the file.

Modification example
Let’s see what happens if we make some changes to the file and add the updated version:
$ echo "Test 2" >> test.txt
This command adds a new line,“Test 2”, to the existing file test.txt.
Let’s add the current version to the stage:
$ git add .
And see what we have inside the .git/objects folder:
$ ls -R .git/objects
34 d2 info pack
.git/objects/34:
5e6aef713208c8d50cdea23b85e6ad831f0449
.git/objects/d2:
77ba2806ce99d418b0b5d6c28643deca0e36dc
...
Now we have two objects, the second one inside the d2 subfolder. Its content is:
$ git cat-file blob d277ba2806ce99d418b0b5d6c28643deca0e36dc
Test
Test 2
It’s the same as our updated text.txt:
$ cat test.txt
Test
Test 2
As we can see, Git stores the complete file for each version.

Tree
The tree objects are how Git is storing folders. They reference other things as their content:
- files are added by their blob
- subfolders are added by their tree
For each reference, a tree stores:
- file or folder name
- blob or tree hash
- object type
- permissions
Like with blobs, Git identifies each tree by the hash of its content. Because the tree is referencing the hash of each file it contains, any change to the content of files will cause the creation of an entirely new tree object.
Similarly, because different versions of the same file will have multiple blobs, Git will create another tree object for each folder version.
Creating a tree
Usually, you create a tree as part of the commit. We will cover commits later in this article, but in the meantime, let’s use git write-tree—a plumbing command that creates a tree based on what is inside our staging.
Plumbing and porcelain commands come from an analogy used in Git:
- porcelain – user-friendly command meant for end users. Same as the showerhead or tap in your bathroom.
- plumbing – internal commands needed to make the porcelain work. Same as the plumbing in your house.
Unless you are doing advanced stuff, you don’t need to know plumbing commands.
Example
With our staging as before, we run:
$ git write-tree
fd4f9947de2805e460bfeeca3346e3d36d617d37
The returned value is the ID of our new tree object. To look inside, you can run:
$ git cat-file -p fd4f9947de2805e460bfeeca3346e3d36d617d37
100644 blob d277ba2806ce99d418b0b5d6c28643deca0e36dc test.txt
Even though it’s a different data type than blobs, their value is stored in the same place:
$ ls -R .git/objects
34 d2 fd info pack
.git/objects/34:
5e6aef713208c8d50cdea23b85e6ad831f0449
.git/objects/d2:
77ba2806ce99d418b0b5d6c28643deca0e36dc
.git/objects/fd:
4f9947de2805e460bfeeca3346e3d36d617d37
…
All the data is in the same folder structure.

Nested example
Now, we’ll add another folder inside to see how nested trees are stored:
- create a new folder:
$ mkdir nested
- add a file & it’s content
$ echo 'lorem' > nested/ipsum
- adding it to the stage
$ git add .
Creating a tree now will give us a new ID:
$ git write-tree
25517090ae5d0eb08f694de6d38d613615fe99e4
Its content:
$ git ls-tree 25517090ae5d0eb08f694de6d38d613615fe99e4
040000 tree bc9a36d27aa303a3b1cab543b64c6944fea5ce8b nested
100644 blob d277ba2806ce99d418b0b5d6c28643deca0e36dc test.txt
We can see that nested was added as a tree reference. Let’s see what is inside:
$ git ls-tree bc9a36d27aa303a3b1cab543b64c6944fea5ce8b
100644 blob 3e9ffe066cd7b2ce4c6fb5c8f858496194e1c251 ipsum
As you can see, it’s another tree object that describes a folder's content. With many tree objects, you can describe any nested folder structure

Commits
A commit is a complete description of the state of the repository. It contains the following information:
- reference for the tree object that describes the topmost folder
- commit author, committer, and time
- parent commit(s)—commits that we based this commit on
Most commits have only one parent, with the following exceptions:
- first commit in history has no parents
- merge commits have more than one
As before, Git identifies each commit by the hash of its content. Therefore, any change to the files, folder, or commit metadata will create a new commit.
The first commit
We can create our first commit with the standard commit command:
$ git commit -m 'first commit'
[main (root-commit) 26349a2] first commit
2 files changed, 3 insertions(+)
create mode 100644 nested/ipsum
create mode 100644 test.txt
The output shows the truncated commit ID. Let’s find a complete value:
$ git show
commit 26349a25253f9b316db1a5d3c3f23c1ca5ca4e0e (HEAD -> main)
Author: Marcin Wosinek <marcin.wosinek@gmail.com>
Date: Thu Apr 28 18:18:07 2022 +0200
first commit
…
To see the content of commit object, we can use:
$ git cat-file -p 26349a25253f9b316db1a5d3c3f23c1ca5ca4e0e
tree 25517090ae5d0eb08f694de6d38d613615fe99e4
author Marcin Wosinek <marcin.wosinek@gmail.com> 1651162687 +0200
committer Marcin Wosinek <marcin.wosinek@gmail.com> 1651162687 +0200
first commit
The tree reference is the same as what we had in the previous example. We can see that commits stay in the same folder as other objects:
ls -R .git/objects
25 26 34 3e bc d2 fd info pack
…
.git/objects/26:
349a25253f9b316db1a5d3c3f23c1ca5ca4e0e
…

Next commit
Let’s restore the first version of our test.txt file:
$ echo "Test" > test.txt
This command overwrites the existing file with “Test”.
$ git add .
Adds the updated version to the staging.
$ git commit -m 'second commit'
[main 7f54a43] second commit
1 file changed, 1 deletion(-)
Commits changes.
Let’s find the full ID:
$ git show
commit 7f54a437d87cd1f241cfb893c4823bc7e60c19ec (HEAD -> main)
Author: Marcin Wosinek <marcin.wosinek@gmail.com>
Date: Thu Apr 28 18:37:55 2022 +0200
second commit
…
The commit content is thus:
$ git cat-file -p 7f54a437d87cd1f241cfb893c4823bc7e60c19ec
tree 04b0192c1c88ac1c1a96f386e84e5388ef8a509a
parent 26349a25253f9b316db1a5d3c3f23c1ca5ca4e0e
author Marcin Wosinek <marcin.wosinek@gmail.com> 1651163875 +0200
committer Marcin Wosinek <marcin.wosinek@gmail.com> 1651163875 +0200
second commit
Git has added the parent line because we commit on top of another commit.

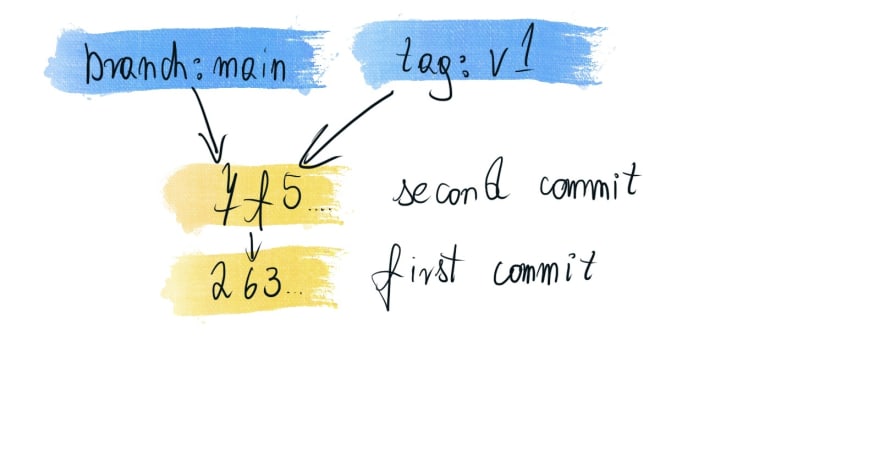
Branches & tags
Other important data kept by Git are just references to a most recent commit. So my main branch is store in .git/refs/heads/main, and its content is
$ cat .git/refs/heads/main
7f54a437d87cd1f241cfb893c4823bc7e60c19ec
or the ID of its topmost commit. We can find all the relevant information from the ever-expanding tree of commits:
- branch history as told by commit messages
- who made a change and when it was made
- the relationship between different branches and tags
When I create a simple tag:
$ git tag v1
A file is created in .git/refs/tags:
$ cat .git/refs/tags/v1
7f54a437d87cd1f241cfb893c4823bc7e60c19ec
As you can see, both tags and branches are explicit references to a commit. The only difference between them is how Git treats them when we create a new commit:
- current branch is moved to the new commit
- tags are left unchanged
Summary
The blob, tree, and commits are how Git stores the complete history of your repository. It does all the references by the object hash: there is no way of manipulating the history or files tracked in the repository without breaking the relations.
Did you find this article helpful? Subscribe to be notified when I publish new articles on programming and JavaScript.

Top comments (0)