Introduction
Data analytics is a crucial aspect of business decision-making in today's fast-paced world. Organizations rely heavily on data analysis to make informed decisions and stay ahead of the competition. In this article, we will explore how data analytics can be performed using Pandas and Intersystems Embedded Python. We will discuss the basics of Pandas, the benefits of using Intersystems Embedded Python, and how they can be used together to perform efficient data analytics.

What's Pandas for?
Pandas is a versatile tool that can be used for a wide range of tasks, to the point where it may be easier to list what it cannot do rather than what it can do.
Essentially, pandas serves as a home for your data. It allows you to clean, transform, and analyze your data to gain familiarity with it. For instance, if you have a dataset saved in a CSV file on your computer, pandas can extract the data into a table-like structure called a DataFrame. With this DataFrame, you can perform various tasks such as:
- Calculating statistics and answering questions about the data such as finding the average, median, maximum, or minimum of each column, determining if there is correlation between columns, or exploring the distribution of data in a specific column.
- Cleaning the data by removing missing values or filtering rows and columns based on certain criteria.
- Visualizing the data with the help of Matplotlib, which enables you to plot bars, lines, histograms, bubbles, and more.
- Storing the cleaned and transformed data back into a CSV, database, or another type of file.
Before delving into modeling or complex visualizations, it's essential to have a solid understanding of your dataset's nature, and pandas provides the best way to achieve this understanding.
Benefits of using Intersystems Embedded Python
Intersystems Embedded Python is a Python runtime environment that is embedded within the Intersystems data platform. It provides a secure and efficient way to execute Python code within the data platform, without having to leave the platform environment. This means that data analysts can perform data analytics tasks without having to switch between different environments, resulting in increased efficiency and productivity.
Combining Pandas and Intersystems Embedded Python
By combining Pandas and Intersystems Embedded Python, data analysts can perform data analytics tasks with ease. Intersystems Embedded Python provides a secure and efficient runtime environment for executing Python code, while Pandas provides a powerful set of data manipulation tools. Together, they offer a comprehensive data analytics solution for organizations.
Installing Pandas.
Install a Python Package
To use Pandas with InterSystems Embedded Python, you'll need to install it as a Python package. Here are the steps to install Pandas:
- Open a command prompt as Administrator mode (on Windows).
- Navigate to the
<installdir>/bindirectory in the command prompt. - Run the following command to install Pandas:
irispip install --target <installdir>\mgr\python pandasThis command installs Pandas into the<installdir>/mgr/pythondirectory, which is recommended by InterSystems. Note that the exact command may differ depending on the package you're installing. Simply replacepandaswith the name of the package you want to install.
That's it! Now you can use Pandas with InterSystems Embedded Python.
irispip install --target C:\InterSystems\IRIS\mgr\python pandas

Now that we have Pandas installed, we can start working with the employees dataset. Here are the steps to read the CSV file into a Pandas DataFrame and perform some data cleaning and analysis:
First Lets create a new instance of python
Set python = ##class(%SYS.Python).%New()
Import Python Libraries, in this case i will be importing pandas and builtins
Set pd = python.Import("pandas")
#;To import the built-in functions that are part of the standard Python library
Set builtins = python.Import("builtins")
Importing data into the pandas library
There are several ways to read data into a Pandas DataFrame using InterSystems Embedded Python. Here are three common methods.
I am using the following sample file as a example.
Read data from a CSV.
Use read_csv() with the path to the CSV file to read a comma-separated values
Set df = pd."read_csv"("C:\InterSystems\employees.csv")
Importing text files {#importing-text-files}
Reading text files is similar to CSV files. The only nuance is that you need to specify a separator with the sep argument, as shown below. The separator argument refers to the symbol used to separate rows in a DataFrame. Comma (sep = ","), whitespace(sep = "\s"), tab (sep = "\t"), and colon(sep = ":") are the commonly used separators. Here \s represents a single white space character.
Set df = pd."read_csv"("employees.txt",{"sep":"\s"})
Importing Excel files
To import Excel files with a single sheet, the "read_excel()" function can be used with the file path as input. For example, the code df = pd.read_excel('employees.xlsx') reads an Excel file named "diabetes.xlsx" and stores its contents in a DataFrame called "df".
Other arguments can also be specified, such as the header argument to determine which row becomes the header of the DataFrame. By default, header is set to 0, which means the first row becomes the header or column names. If you want to specify column names, you can pass a list of names to the names argument. If the file contains a row index, you can use the index_col argument to specify it.
It's important to note that in a pandas DataFrame or Series, the index is an identifier that points to the location of a row or column. It labels the row or column of a DataFrame and allows you to access a specific row or column using its index. The row index can be a range of values, a time series, a unique identifier (e.g., employee ID), or other types of data. For columns, the index is usually a string denoting the column name.
Set df = pd."read_excel"("employees.xlsx")
Importing Excel files (multiple sheets) {#importing-excel-files-(multiple-sheets)}
Reading Excel files with multiple sheets is not that different. You just need to specify one additional argument, sheet_name, where you can either pass a string for the sheet name or an integer for the sheet position (note that Python uses 0-indexing, where the first sheet can be accessed with sheet_name = 0)
#; Extracting the second sheet since Python uses 0-indexing
Set df = pd."read_excel"("employee.xlsx", {"sheet_name":"1"})
Read data from a JSON.
Set df = pd."read_json"("employees.json")
Lets look at the data in the dataframe.
How to view data using .head() and .tail()
For this we can use the builtins library which we imported (ZW works too![]() )
)
do builtins.print(df.head())

Let's list all the columns on the dataset
Do builtins.print(df.columns)

Lets Cleanup the data
Convert the "Start Date" column to a datetime object.
Set df."Start Date" = pd."to_datetime"(df."Start Date")
the updated dataset looks as follows.

Convert the 'Last Login Time' column to a datetime object
Set df."Last Login Time" = pd."to_datetime"(df."Last Login Time")

Fill in missing values in the 'Salary' column with the mean salary
Set meanSal = df."Salary".mean()
Set df."Salary" = df."Salary".fillna(meanSal)
Perform Some Analysis.
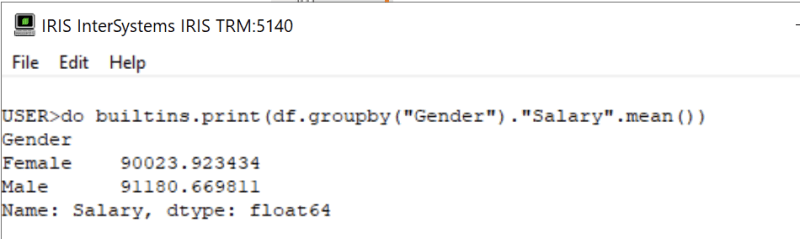
Calculate the average salary by gender.
Do builtins.print(df.groupby("Gender")."Salary".mean())
Calculate the average bonus percentage by team.
Do builtins.print(df.groupby("Team")."Bonus %".mean())

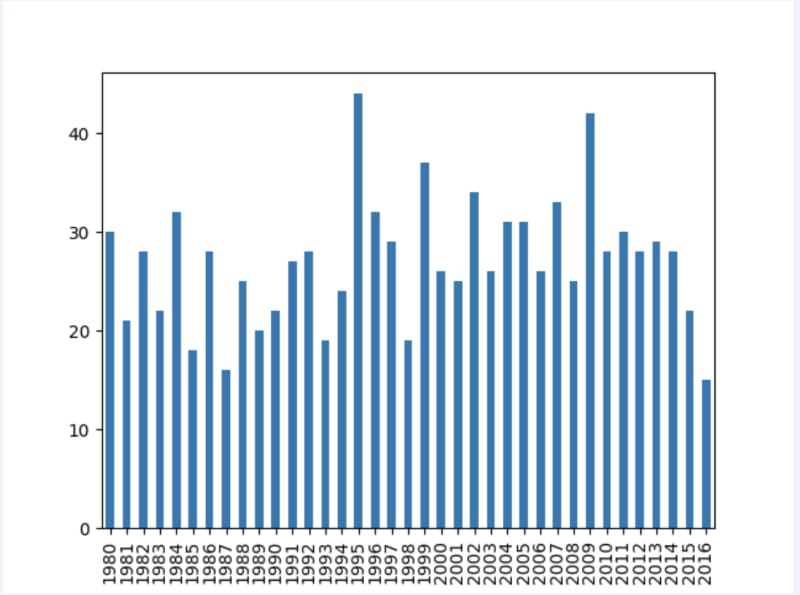
Calculate the number of employees hired each year.
Do builtins.print(df."Start Date".dt.year."value_counts"()."sort_index"())

Calculate the number of employees by seniority status.
Do builtins.print(df."Senior Management"."value_counts"())

Outputting data in pandas {#outputting-data-in-pandas}
Just as pandas can import data from various file types, it also allows you to export data into various formats. This happens especially when data is transformed using pandas and needs to be saved locally on your machine. Below is how to output pandas DataFrames into various formats.
Outputting a DataFrame into a CSV file {#outputting-a-dataframe-into-a-csv-file}
A pandas DataFrame (here we are using df) is saved as a CSV file using the ."to_csv"() method.
do df."to_csv"("C:\Intersystems\employees_out.csv")
Outputting a DataFrame into a JSON file {#outputting-a-dataframe-into-a-json-file}
Export DataFrame object into a JSON file by calling the ."to_json"() method.
do df."to_json"("C:\Intersystems\employees_out.json")
Outputting a DataFrame into an Excel file {#outputting-a-dataframe-into-an-excel-file}
Call ."to_excel"() from the DataFrame object to save it as a “.xls” or “.xlsx” file.
do df."to_excel"("C:\Intersystems\employees_out.xlsx")
Let's create a basic bar chart that shows the number of employees hired each year.
for this i am using matplotlib.pyplot
//import matplotlib
Set plt = python.Import("matplotlib.pyplot")
//create a new dataframe to reprecent the bar chart
set df2 = df."Start Date".dt.year."value_counts"()."sort_index"().plot.bar()
//export the output to a png
do plt.savefig("C:\Intersystems\barchart.png")
//cleanup
do plt.close()
That's it! With these simple steps, you should be able to read in a CSV file, clean the data, and perform some basic analysis using Pandas in InterSystems Embedded Python.
Video
You are now able to access the video by utilizing the link provided below. The video itself serves as a comprehensive overview and elaboration of the above tutorial.
https://youtu.be/hbRQszxDTWU
Conclusion
The tutorial provided only covers the basics of what pandas can do. With pandas, you can perform a wide range of data analysis, visualization, filtering, and aggregation tasks, making it an invaluable tool in any data workflow. Additionally, when combined with other data science packages, you can build interactive dashboards, develop machine learning models to make predictions, automate data workflows, and more. To further your understanding of pandas, explore the resources listed below and accelerate your learning journey.
Disclaimer
It is important to note that there are various ways of utilizing Pandas with InterSystems. The article provided is intended for educational purposes only, and it does not guarantee the most optimal approach. As the author, I am continuously learning and exploring the capabilities of Pandas, and therefore, there may be alternative methods or techniques that could produce better results. Therefore, readers should use their discretion and exercise caution when applying the information presented in the article to their respective projects.

Top comments (0)