
photo by @karishea
Hashmaps are a type of data structure used in computer science to format, organise, and manage data. In this blog post, we'll take a look at why we use them, how they work, and what the advantages and disadvantages can be. Additionally, we'll also quickly examine the introduction of Map to JavaScript with ES6.
What is a hashmap?
Hashmaps allow us to organise data in a way that later enables us to retrieve values based on their keys. In a hashmap, a key is assigned to a single value. In the table below, we've included some characters from Avatar: The Last Airbender. In this example, the names would be our keys, and the favourite foods would be the values. As we can see, each character has one (and only one!) favourite item. Likewise, in a hashmap, we can only allocate one value per key.

Now that we have some basic data, we can take a look at how this would work with a hashmap.
How do hashmaps work?
Hashmaps work by first utilising a hashing function to determine how to store data. Let's imagine that we're working with our favourite foods table. Our computer won't just store the data as it is - instead, the hashing function will take the keys and turn them into array indexes, and eventually return the data as an array. Hashing functions are also known as compression functions, because the output is smaller than the input.
For example, we could create a very basic function like so:
function simpleFunction(string) {
let numberOfAs = 0
for (let i=0; i < string.length; i++) {
string[i].toLowerCase() === 'a' ? numberOfAs ++ : null
}
return numberOfAs
}
This function takes a string, counts the number of 'a's within the string, and returns that number, which can then be used as an index in an array.
Note that this is not an actual hashing function - the output of a hashing function is the entire array of data, not simply the 'hashed' keys.
Our example function would return the following values:

Using these returned values, we can store Toph's information at index 0, Sokka's at 1, Aang's at 2, and Katara's at 3. This is a very basic example, and real hashing functions are more complex, and therefore more effective in producing indexes. They will generally create a hash code, and then use the modulo operator in order to generate the array index, like so:

Fig. 1. Carnegie Mellon University, Concept of Hashing
The data can then be stored as an array, giving us the ability to easily add, retrieve, and delete data as needed.
Collisions
There are a number of reasons why the process of generating indexes has to be somewhat complex, the main one being that repeats of indexes can be problematic. For instance, were we to include Zuko in our Avatar table while using the simple function above, he would be allocated the same index as Toph, 0. Again, this is a rudimentary example, and real hash functions are much more effective in minimising this type of repetition, however they do still happen. When two values are given the same index, we call this a hash collision. There are a couple of ways to avoid collisions, which we can take a look at below:
Separate Chaining
One way to avoid collisions is to combine your hash map with another data structure, for instance linked lists. Rather than a simple array of values, you can create an array of linked lists. This process is called separate chaining. The hashmap takes the key and turns it into an index in the array. If that index has already been taken by another value, a link will be created between the first value and the second, like so:
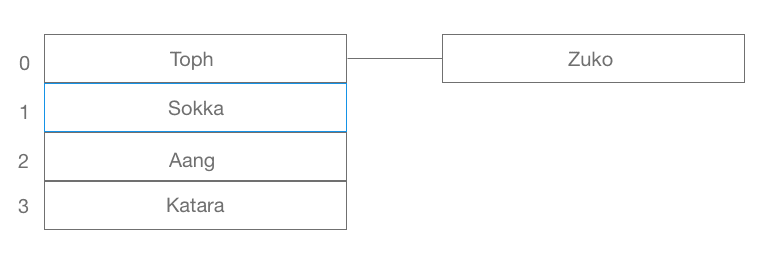
When using linked lists, it's also recommended that the key is saved, so that our computer knows which value belongs to which key. Separate chaining is a great way to get around duplicates of indexes, however it can slow down performance if any of the lists get too long.
Open Addressing
Another solution for collisions could be open addressing. In this situation, when a value is allocated an index that has already been taken, we simply look for another open index. One method of doing this is through linear probing. For instance, if we decided to include Zuko in our hashmap, we would initially try to place him at index 0, which has already been occupied by Toph. Using linear probing, we would then move to the next open index, in this case 4, which would give us the resulting indices:

This solution means that we no longer have to worry about any performance impact linked lists might have on our application. However, it is also open to problems. We might want to include a character who has 4 'a's in their name, for instance Avatar Yangchen. Avatar Yangchen should be placed at index number 4, however in this case that index is already occupied by Zuko. Therefore, we might use a solution called quadratic probing. Rather than simply looking for the next available index, the hash code would become increasingly larger, so Zuko could be placed further down the list, therefore preventing him from taking someone else's spot.
Pros and Cons of Hashmaps
In many ways, hashmaps are a great way to store data, however there are a few downsides. If we don't use an effective hashing function, they can be inefficient as they are prone to collisions. While we do have ways to solve these, for instance linked lists or open addressing, we have to be cognisant of the possible negative effects these solutions bring. It is possible to rehash or resize your table in order to remove these collisions, however this adds another layer to your data structure. As we can see from the table below, these factors can have a significant effect, and can make our runtime linear (O(n)) rather than constant (O(1)).
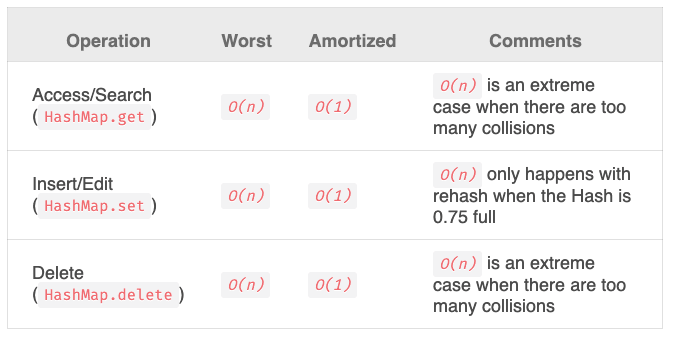
Fig. 2. Adrian Mejia, Data Structures in JavaScript: Arrays, HashMaps, and Lists
However, despite these downsides, there are many positive aspects to hashmaps. If used correctly, they can be an incredibly efficient to create, retrieve, and delete our data, especially when we are dealing with a large amount.
JavaScript and Hashmaps
Hashmaps are now part of JavaScript functionality, thanks to ES6, and come in the form of the Map object. We can create a Map like so:
const avatarMap = new Map()
avatarMap.set('Toph', 'Dumplings')
avatarMap.set('Sokka', 'Meat')
avatarMap.set('Aang', 'Egg Custard Tart')
avatarMap.set('Katara', 'Crab Puffs')
//=> Map {
// 'Toph' => 'Dumplings',
// 'Sokka' => 'Meat',
// 'Aang' => 'Egg Custard Tart',
// 'Katara' => 'Crab Puffs'
// }
For JavaScript users, Map might seem relatively similar to Object, however there are a few key differences. Primarily, keys in an Object must either be strings or symbols, while in a Map we can use both objects and primitive values. Secondly, in an Object, size must be calculated, while Map has an inbuilt size property:
avatarMap.size
//=> 4
Objects are more difficult to iterate over, as they require us to obtain the keys before iterating over them, while Map is an iterable. For instance, we can use the Map.entries method, which returns an object containing an array of key value pairs for each element in the Map object in insertion order:
for (const [key, value] of avatarMap.entries()) {
console.log(key, value);
}
//=>
// Toph Dumplings
// Sokka Meat
// Aang Egg Custard Tart
// Katara Crab Puffs
Finally, Map works better when we have to add or remove key-value pairs on a regular basis. For instance, we can easily remove a pair using the key:
const deleteCharacter = (map, character) => {
map.delete(character)
return map
}
deleteCharacter(avatarMap, 'Toph')
//=> Map {
// 'Sokka' => 'Meat',
// 'Aang' => 'Egg Custard Tart',
// 'Katara' => 'Crab Puffs'
// }
This is a very brief overview of some of the features of Map in JavaScript, and there is far more to be explored. You can learn more about Map and its functionality here.
Sources
- "Concept of Hashing", Carnegie Mellon University, accessed August 12th, 2020
- "Map", MDN web docs, accessed August 12th, 2020
- "Map in JavaScript", Geeks for Geeks, accessed August 12th, 2020
- 'Hashmaps, Codecademy, accessed August 11th, 2020
- "JavaScript: Tracking Key Value Pairs Using Hashmaps", Martin Crabtree, Medium, accessed August 12th, 2020
- "Data Structures in JavaScript: Arrays, HashMaps, and Lists", Adrian Mejia, , accessed August 13th, 2020

Top comments (2)
Very clear explanation overall👍.In your discussion on quadratic probing though, you said that items (Zuko) will be placed further down the list, preventing items (Zuko) to take other items’ place. I think this may not be convincing.
The problem with linear probing is that it creates Primary Clustering effect where items are clustered together if they all hashed to the same index. Quadratic probing just separate the items further away when they are hashed to the same index. It helps but it may again create Secondary Clustering effect as two items that are hashed to the same initial index will have the same probe sequence. Whichever collision resolution technique you use other than Separate chaining, you are placing items to “take some other item’s place”. Quadratic probing is better in a way that it spreads out the items slightly better than linear probing.
Also, the modulo in most hashing functions is used to wrap around the array because hash tables have a finite size.
Thanks for the comments! That's a really clear explanation of primary and secondary clustering, and I definitely agree that probing (linear or quadratic) is not perfect in preventing collision problems. Separate chaining may indeed be the better option.