
I recently joined a project where we do data processing with Kafka Streams applications and came across an interesting problem: "list joins". There was already a working solution to the problem, but I was not quite satisfied, so I dug a little deeper. Since I didn't find much on the topic online, I wanted to share my findings here.
TL;DR The final topology is discussed here and you can find the code here:
 iptch
/
kafka-list-join-demo
iptch
/
kafka-list-join-demo
A demo showing how to do a list join in a kafka streams application.
Kafka List Join Demo
This project shows two ways to perform a list join in a Kafka streams application. A list join refers to joining a record that contains a list with a KTable, such that each element in the list gets joined with the corresponding element in the KTable.
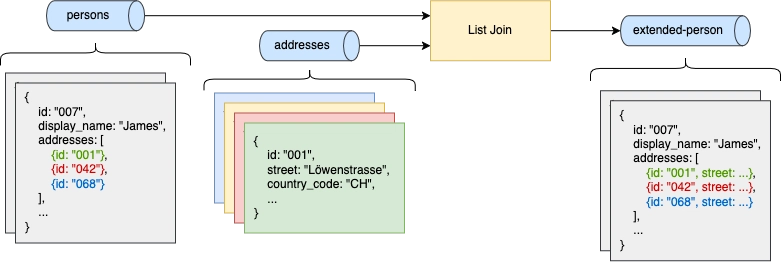
This image shows the high level idea, joining a persons address list, with the corresponding addresses:

Check out this blog post for a discussion of the approaches.
The tests should cover all relevant cases of message ordering and updates.
Building
To build and test the project, run
./gradlew clean build
I assume you have some understanding of Kafka Streams, but I'll try to link to relevant documentation and resources where possible. It's worth checking out the Kafka Streams DSL Developer Guide if you are unfamiliar with Kafka Streams.
The Problem
We have a topic with records (of type Outer, e.g., a person) that contain (among other things) a list. The elements in the list reference records on another topic (of type Inner, e.g., addresses). For every element in the outer topic we want to look up the corresponding record in our inner topic, and merge them to enhance our list.
Additional Considerations
There are a few additional constraints we need to keep in mind:
- Eventual Consistency: The corresponding records on the inner topic may not be available right away, that is, records may come in after our outer record.
- Updates: Our outer record may be updated over time. This may include updates (additions/removals) of inner list elements, but also updates to fields other than the list.
- Duplicates: In our specific use case we don't need duplicate list entries. However, all approaches discussed here can be modified to allow duplicates without too much effort.
The Existing Solution
The existing solution to the problem looks roughly like follows:
- We set a timestamp on every record on our outer stream (needed later).
- We flat map our outer records so we have exactly one inner list element in every flat mapped record, to differentiate the flat records we change the keys to composite keys (of the form
<outer-key>$$<inner-key>). - We interpret the resulting stream as a KTable and perform a foreign key left join with the other KTable. The KTable-KTable left join (as opposed to, e.g., a KStream-KTable join) is needed to fulfill our eventual consistency constrain.
- We group the the resulting records by the first part of the composite key.
- Finally, we reduce the records in each group by appending the lists, but we only consider the newest timestamp we see. Whenever we see a newer timestamp we discard all older records. This ensures that we do not add stale elements to our list that may be deleted in the current list.
The code looks similar to the below, though I left some smaller details out, such as how we forward tombstones. The full code can be found here.
(outerKStream, innerKTable) -> outerKStream
.mapValues(outerMapper)
.flatMap(outerFlatMapper)
.toTable(buildStore(outerSerde, "listJoinFlatStore"))
.leftJoin(
innerKTable,
outer -> outer.getInnerCount() == 0 ? null : outer.getInner(0).getId(),
outerInnerJoiner,
buildStore(outerSerde, "listJoinJoinerStore")
)
.toStream()
.groupBy(
(key, _) -> key.split("\\$\\$")[0],
Grouped.with(Serdes.String(), outerSerde)
)
.reduce(
outerReducer,
buildStore(outerSerde, "listJoinReducerStore")
)
.toStream()
Issues
While this approach works for our use case, I don't like it for two reasons:
It feels hacky: The timestamps feel a bit hacky and force us to change our data model just for this operation. While we can (and in production do) clear the timestamps after the list join is complete, we are using protobufs for our records. So the timestamp is part of the protobuf definition, even if downstream services don't need it.
It is inefficient: Whenever the original protobuf changes (be it, a change to the list, or any other field), all list elements go through the join again, followed by reducing them all (including stale old records) again. That just feels wasteful.
These issues prompted me to spend some time on the problem and see if I can come up with something better.
Improvements
We want to reduce the number of join and reduce operations and remove the need for a dedicated timestamp field.
For this we need a component that keeps track of the changes in the list of a record so that we only process relevant changes.
The List Join Pre-Processor
The only way I found to accomplish this, is to write a custom Processor using the Processor API provided by Kafka Streams.
The list join pre-processor performs the task of the flat-map operation from before, but maintains internal state1 to remember what list elements are currently in each record. When a record gets updated, it compares the previous and new list, and (1) only issues flat mapped records for new list elements and (2) issues tombstones for elements removed from the list.
(1) ensures that we only have to join new list elements, reducing duplicate work. (2) allows us to more efficiently remove old list elements, so we don't need to rely on a hacky timestamp.
The pre-processor also always forwards a copy of the current record with an empty list. We need this later to correctly propagate changes to other fields that are not the list.
The logic of the pre-processor, which can also be found here, looks as follows:
public void process(Record<String, TOuter> record) {
// in case of tombstone or empty list, this map is empty
Map<String, TOuter> flatValuesMap = flatMapper.apply(record.value()).stream()
.collect(Collectors.toMap(
innerIdStringExtractor,
Function.identity(),
(_, newValue) -> newValue
));
Set<String> newIds = flatValuesMap.keySet();
Set<String> oldIds = Optional.ofNullable(listStore.get(record.key()))
.map(Set::copyOf)
.orElse(Set.of());
// if both new and old ids are empty we don't need to do anything and can short circuit
if (newIds.isEmpty() && oldIds.isEmpty()) {
return;
}
// forward flat mapped records for new list elements
Sets.SetView<String> addedIds = Sets.difference(newIds, oldIds);
for (String newId : addedIds) {
forward(record.key(), newId, flatValuesMap.get(newId));
}
// send tombstones for removed list elements
Sets.SetView<String> removedIds = Sets.difference(oldIds, newIds);
for (String removedId : removedIds) {
forward(record.key(), removedId, null);
}
// if the current list is empty delete the list from the store and send a tombstone
// for the empty list record, otherwise save the current list and send an empty list
// record to propagate changes to other fields
if (newIds.isEmpty()) {
forward(record.key(), null, null);
listStore.put(record.key(), null);
} else {
forward(record.key(), null, listCleaner.apply(record.value()));
listStore.put(record.key(), List.copyOf(newIds));
}
}
Better Reduce Operation
Now that the flat-map and the subsequent join are improved, we can further improve the reduce operation.
Previously, the reduce operation was responsible for filtering out outdated records (based on the timestamp) and aggregating the list of inner elements. This was done on all flat-mapped values (including outdated values) and needed to happen every time anything in the original outer record changed.
Now, that we can issue tombstones for removed elements, we can transition from a KStream group-by and reduce to a KTable group-by and reduce.
The KTable reduce works a bit differently than the KStream reduce. Where the KStream reduce has a single reducer that receives the current aggregate and any new record (be it a tombstone or a normal record), the KTable reduce has an adder reducer and a remover reducer.
The adder reducer is called when ever an element is added to the KTable and receives the current aggregate and the newly added record.
The remover reducer is called when ever an element is removed from the KTable (via a tombstone) and is provided with the current aggregate and the removed record. This allows us to remove the inner element from the current aggregate, as we know exactly which one got removed.
Our adder looks as follows. Remember that our pre-processor also sends a copy of the original record with an empty list. This way we can update other fields as well.
public Outer apply(Outer currentValue, Outer newValue) {
if (newValue.getInnerList().isEmpty()) {
// if list is empty update all fields other than the list
return newValue.toBuilder()
.addAllInner(currentValue.getInnerList())
.build();
} else {
// otherwise add inner item to current list
return currentValue.toBuilder()
.addAllInner(newValue.getInnerList())
.build();
}
}
The full code can also be found here.
Our remover only has to worry about removing the list elements. In our case we do it based on the inner ID.
public Outer apply(Outer currentValue, Outer oldValue) {
// if oldValue inner list is empty, there is nothing to do
// the adder handles empty list updates
if (oldValue.getInnerList().isEmpty()) return currentValue;
// remove the single inner value from the current list,
// in this case we do it by id
Inner innerToRemove = oldValue.getInnerList().getFirst();
List<Inner> innerList = currentValue.getInnerList().stream()
.filter(inner -> !inner.getId().equals(innerToRemove.getId()))
.toList();
return currentValue.toBuilder()
.clearInner()
.addAllInner(innerList)
.build();
}
The full code can also be found here.
New Topology
Incorporating the two improvements from above, we end up with a topology which looks surprisingly similar to our initial topology.
(outerKStream, innerKtable) -> outerKStream
.process(preProcessorSupplier)
.toTable(buildStore(outerSerde, "listJoinFlatStore"))
.leftJoin(
innerKTable,
// if the inner list is empty the foreign key extractor should
// return null so the outer is joined with null
outer -> outer.getInnerCount() == 0 ? null : outer.getInner(0).getId(),
outerInnerJoiner,
buildStore(outerSerde, "listJoinJoinerStore")
)
.groupBy(
// group by first part of composite key
(key, value) -> KeyValue.pair(key.split("\\$\\$")[0], value),
Grouped.with(Serdes.String(), outerSerde)
)
.reduce(
listAdder,
listRemover,
buildStore(outerSerde, "listJoinReducerStore")
)
.toStream()
Again, I skipped over some smaller details, like how we forward tombstones. The full topology can be found here.
Since copying this code to different topologies is a bit cumbersome, we decided to wrap this entire sub-topology in a ListJoin utility. This allows easier reusing of the code, as the developer only has to provide a couple key components and make the resulting topologies easier to understand.
// setup
ListJoin<...> listJoin = ListJoin.builder()
// specify joiner, reducers, etc.
.build()
// later in the topology
KStream<...> joinedKStream = listJoin.apply(myLeftKStream, myRightKTable);
Conclusion
This topology is probably still not optimal. For one, it may make sense to deduplicate the empty list records to further reduce downstream work. However, in our case this is not necessary.
In any case, this new approach is a clear improvement over the previous timestamp based approach.
Have you solved a similar, or even the same, problem before? If so, please consider leaving a comment as I'd very much like to hear what you did. Likewise, if you have found issues with the above code or have ideas for improvements, I'm keen to hear from you!
Acknowledgments
Cover image: "Close Up Photo of Blue Background" by Harrison Candlin

-
Maintaining state can be done via a state store, which is automatically backed up to a changelog topic in kafka, ensuring the processor can tolerate application scaling and recover in case of application failures. ↩

Top comments (0)