What kind of code is considered low?
The term "Low-Code" has become popular in the past years, springing into existence a number of corresponding entrepreneurial teams. We only knew there were long codes and short codes before, only now do we know there are still high and low codes.
Intuitively, the so-called low code is to make the code easier to write, in other words, the amount of code (which can be understood as workload) is less when doing the same task; In addition, another important indicator of low code is that the requirements for developers should be low enough. If all codes were written by masters with many years of experience, it would be difficult to achieve the purpose of reducing costs and improving efficiency, even if the code are written short.
Obviously, when discussing the low code, first we should have a kind of code and see if this code is a little lower than other codes.
However, many so-called development platforms boasting of low code do not have their own code actually, but just make some frameworks and templates. The developers can build an application system by just filling in the templates. Yes, it is no problem to use these templates to deal with simple requirements and is fairly easy to use, but when the requirement becomes so complicated that you need to use code to address, you still have to use codes like Java/C#.
The Low-Code is to make the code low, not the framework. Templates without code can indeed solve some problems, but there are still too many businesses that need code to get them done. Thus, the high and low degree of code is indeed closely related to development efficiency.
So, what kind of code is regarded as low code?
The low code is mainly oriented to the development of information system (commonly known as MIS in a broad sense), because only these applications are in a variety of requirements, and every requirement of different scenarios is different, and is always changing without an end. In this case, the development means with high efficiency and low threshold are particularly meaningful.
The main task of information system is actually to do three things around data: Input, Process and Output. The initials of the three words combined together is an IPO, where I and O can now be solved by mature reporting tools and interface controls, and hence the only trouble is P. Most of the business logic to be coded in the development process is exactly to solve P.
Therefore, when we judge whether a code is low enough, we need to know whether this code is convenient to process data.
Then, what kind of data to process?
It mainly refers to the structured data, i.e., the data that exists in the relational database, which is the most common data type in information system. Other unstructured data are only suitable for some special and fixed processing requirements. Otherwise, only converting such data to structured data or extracting the structured data from them can meet the needs of flexible processing.
In this case, it's just a matter of determining which code is good at handling structured data.
Under this criterion, Java code is certainly not low, because Java does not have an acceptable structured data object. Although the new version of Java is provided with the set-oriented class library such as Stream and begins to support Lambda syntax, it still aims at and can only aim at very generic data objects (this is determined by the goal of Java itself), and it is still relatively troublesome to code when dealing with structured data. Moreover, Java is a compiled language and is inherently difficult to be dynamic. Furthermore, Java is a strong object-oriented language, and it is not easy to deeply understand the object-oriented concept. When developing Java applications, there is also a need to establish a complex project environment, which is not a low threshold for developers.
The situation of C# language is similar.
The SQL code is relatively low to a certain extent. Many non-professionals can code queries in SQL. When coding in SQL, developers don't need to care much about the application architecture, but only need to understand the data and the business itself, which are the knowledge that developers must have.
However, SQL has two serious flaws in two aspects: ordered computation and procedural logic. Such flaws will cause the slightly more complicated processing to become very troublesome, often resulting in a written syntax with hundreds of lines and nested with multiply levels, which cannot be understood even by the developer himself after a few months. Moreover, it is particularly difficult to debug SQL code, and hence the development cost is further increased.
If using the stored procedure instead, the procedural operation can be implemented, but it's like turning back to Java. Although the stored procedure is written in SQL, it also has no easy-to-use structured data objects (developer can only rely on the temporary table) and set operation. Therefore, it is usually better to use Java to command SQL to work (in fact, many applications are programmed in Java + SQL). Also, when using stored procedures, the developer also faces some application architecture troubles.
The "low" of SQL code is only suitable for relatively simple scenarios. When the business requirements become complex, the complexity of code will increase exponentially.
As for Python, the situation is slightly better. Pandas has a dataframe that can be counted as a structured data object. Unfortunately, Python is relatively poor in integration unless the whole application was written in Python, which is rare, however. Moreover, the dataframe can only be regarded as a dabbler since it is essentially a matrix, not a data table in our conventional sense, and many operations are very confusing to think about. Moreover, we have to say it again, pandas is a third-party class package, its application environment is not very simple, and the debugging is still troublesome.
Scala is another option, likewise, it also has a dataframe that can do some structured data processing, but it is not very professional as well. Although Scala code itself is relatively low, but the threshold for understanding the stuff like object-oriented concept is not low at all, and it will also face a complex project environment.
SPL is the low code
Is there not a kind of low enough code?
Yes, there is! the SPL of open-source esProc is the low code, and probably the only one currently.
This is actually why SPL was invented: since Raqsoft is a reporting tools provider, it naturally involves a lot of complex operations. However, Raqsoft found it difficult to code these operations in both SQL and Java, and such difficulties cannot be solved by perfecting the existing system. To solve these problems, Raqsoft invented a new language after years of hard working, which is SPL.
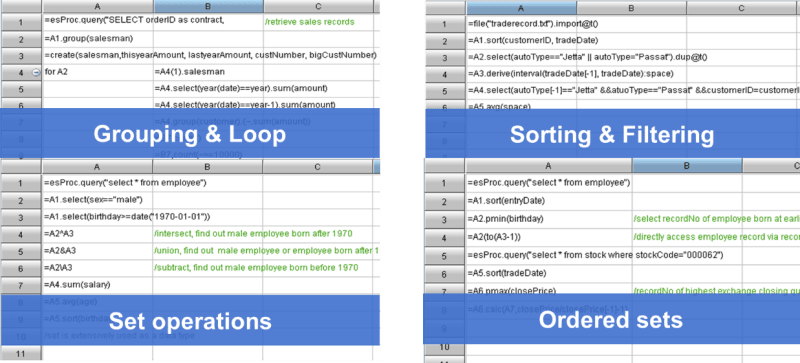
In SPL, there are well-established structured data objects, and it can handle both big data and small data. Although it adopts a small amount of object-oriented syntax, it does not use esoteric object-oriented concepts, but focusing on data processing and operations. Just a bit like the early BASIC language in terms of program logic, SPL has the basic branches, loops and subprograms, which make it very easy to understand. Moreover, SPL provides structured-data-based set types and rich library functions, in particular, it is good at supporting complex set and ordered operations, thereby making code writing much simpler.
Talk is cheap, Let’s show code.
SPL code is written in a grid, and it can directly use cells as the variable name (Excel users will find it familiar). Moreover, SPL has the following characteristics: it naturally supports stepwise operation; the levels of code can be clearly reflected by the indentation of grid; and it is provided with perfect debugging functions.
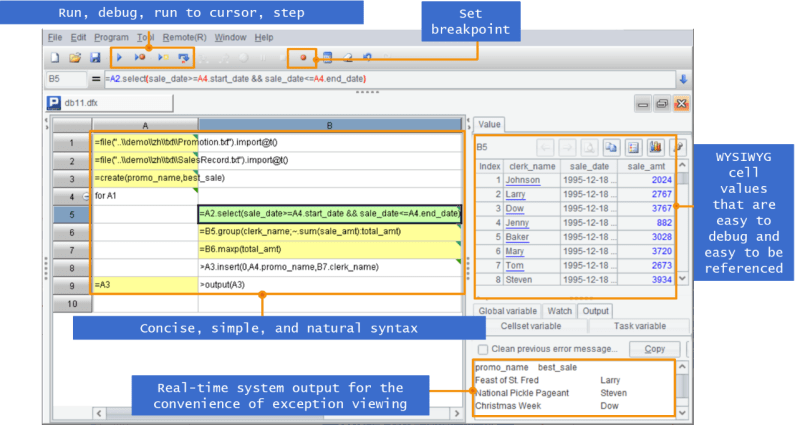
Rich library functions; common basic operations can be done in just one line.
In SPL, you can even use SQL directly (independent of database):
$select * from d:/Orders.csv where (OrderDate<date('2020-01-01') and Amount<=100)or
(OrderDate>=date('2020-12-31') and Amount>100)
$select year(OrderDate),Client ,sum(Amount),count(1) from d:/Orders.csv
group by year(OrderDate),Client
having sum(Amount)<=100
$select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o
join d:/Employees.csv e on o.SellerId=e.Eid
$with t as (select Client ,sum(amount) s from d:/Orders.csv group by Client)
select t.Client, t.s, ct.Name, ct.address from t
left join ClientTable ct on t.Client=ct.Client
SPL itself has the process control capability similar to Java, therefore, SPL can achieve the effect of Java + SQL whether there is database or not.
Let’s compare it with other codes. For example, we want to calculate the maximum consecutive days that a stock keeps rising.
Write it in SQL is like this:
select max(consecutive_days)
from (select count(*) consecutive_days
from (select sum(updown_flag) over(order by sdate) no_up_days
from (select sDate,
case when price>LAG(price) over(order by sDate)
then 0 else 1 end updown_flag
from share))
group by no_up_days)
This code is a bit difficult to understand, right? You can take it as an exercise and think about how it works.
Coding in Python is as follows:
import pandas as pd
aapl = pd.read_excel(‘d:/AAPL.xlsx’)
continue_inc_days=0;
max_continue_inc_days=0
for i in aapl['price'].shift(0)>aapl[‘price’].shift(1):
continue_inc_days =0 if i==False else continue_inc_days+1
max_continue_inc_days = continue_inc_days if max_continue_inc_days < continue_inc_days else max_continue_inc_days
print(max_continue_inc_days)
Although this logic is not complicated, it is not very simple to code.
As for Java, we won't try. You can imagine its complexity yourself.
For the same operation, coding in SPL is as follows:
A
1 =T("d:/AAPL.xlsx")
2 =a=0,A1.max(a=if(price>price[-1],a+1,0))
There is no loop statement in this code, because SPL has a large number of strong lambda syntax-style set functions. Many tasks that can only be achieved with loops in other languages can be done with a single statement in SPL.
SPL solves the serious flaws of SQL, and combines the common advantages of Java and SQL. In addition, SPL can easily support the big data operation and multi-thread parallel computing, but for Python, it will find it at a loss when it encounters such situation. If you are interested in learning more SPL code examples, go to Raqforum.
More than a kind of low code
SPL provides perfect data source support; it can support almost all data sources that you may or may not have heard of:

Thus, it reduces a lot of work load of preparing the data interface and conversion.
Since SPL is implemented in Java, it is provided with JDBC driver, and can be seamlessly embedded into Java applications:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call xxxx(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
In this way, SPL can be easily integrated into some application framework. Most developers only need to care about business logic and data structure, and don't even need to understand complex application architecture.
In particular, for those “low code platforms” without code, they will have real low code after integrating the open-source SPL. Letting template and code to complement each other is a complete low-code platform.
SPL is also the interpreted-execution dynamic language, and the scripts written can be placed outside the main application. In this way, not only does it reduce the coupling between the script and the main application, but it also brings the benefits of hot swap. After all, the business logic (especially query and report)is often changing. When the requirement changed, it can take effect immediately as long as the script is rewritten, and there is no need to restart the application. If Java code is used in this case, then... (it also shows that Java code is not low at all).
SPL Source code: https://github.com/SPLWare/esProc
Origin: https://blog.scudata.com/interpreting-low-code-from-the-perspective-of-open-source-spl/

Top comments (0)