
DeepSeek R1 shook the Generative AI world, and everyone even remotely interested in AI rushed to try it out. It is a great model, IMO. As you may know, I love to run models locally, and since this is an open-source model, of course, I had to try it out. It works great on my Mac Studio and 4090 machines.
But can it run on this? A silly little Raspberry Pi?

I received a few emails and private messages asking about this and had to try it out. In this tutorial, we'll walk through how to run DeepSeek R1 models on a Raspberry Pi 5 and evaluate their performance. Whether you want to get into running LLMs locally or build some edge AI stuff, this could be a fun tutorial to try out.
Here it is in video form if you prefer that:
So let's get started. Here's what you need:
Prerequisites
- Hardware:
- Raspberry Pi 5 (8GB or 16GB RAM recommended).
- MicroSD card with Raspberry Pi OS (64-bit) installed.
- Stable power supply and internet connection.
- Software:
- Basic familiarity with Raspberry Pi OS and terminal commands.
- Docker (optional, for containerized applications).
Here's the machine I tried it with:
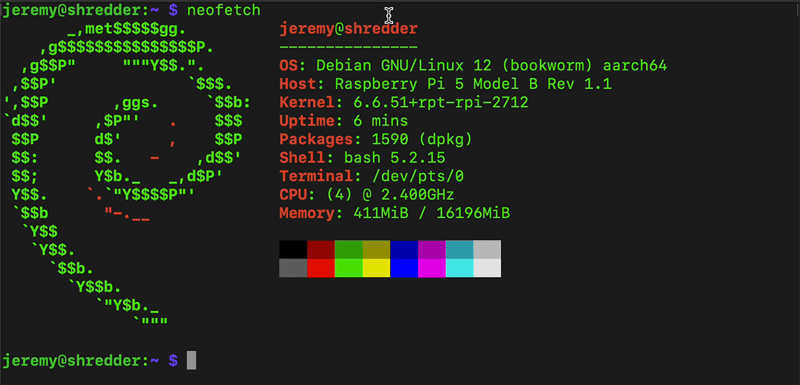
Step 1: Configure Your Raspberry Pi
Enable Remote Desktop (Optional)
To simplify GUI interactions, enable Remote Desktop:
sudo apt-get install xrdp -y
sudo systemctl start xrdp
sudo systemctl enable xrdp
Set the Pi to auto-login to the desktop GUI.
Type in
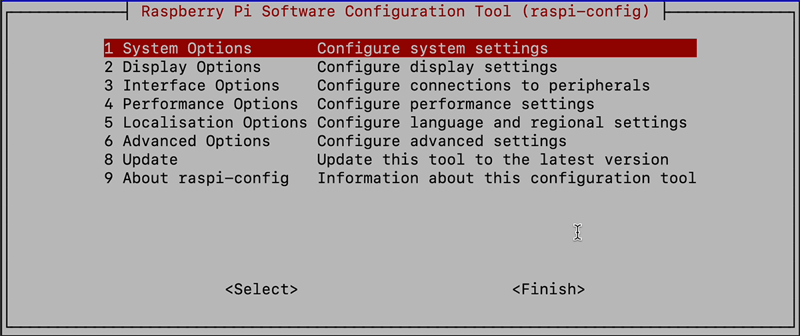
sudo raspi-config
And select 1 System Options
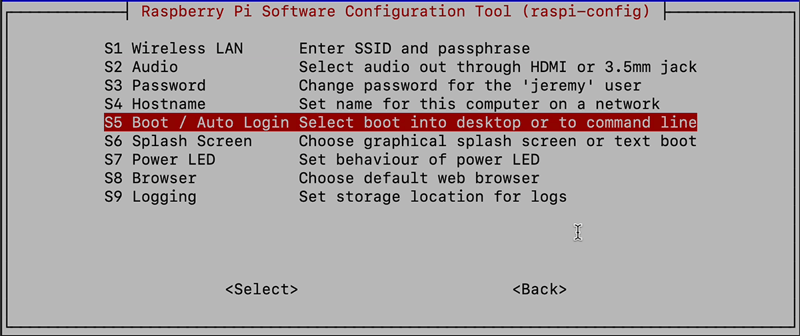
Then select S5 Boot/Auto Login
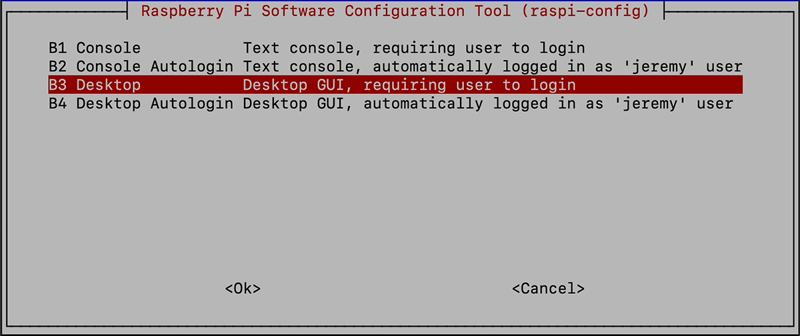
and choose B3 Desktop (Desktop GUI, requiring user to login)
Now, if you want, you can log into the desktop remotely using RDP and access a desktop.
Note: on my Raspberry Pi I could not get any browsers to run properly. They would not display in a readable form, I'll be looking it and trying to fix that at some point.
Your browser may also look like this:
Step 2: Install Ollama
Ollama is a tool for running LLMs locally. Since Raspberry Pi uses ARM64 architecture, download the Ollama Linux ARM64 build:
curl -fsSL https://ollama.com/install.sh | sh
Verify the installation:
ollama --version
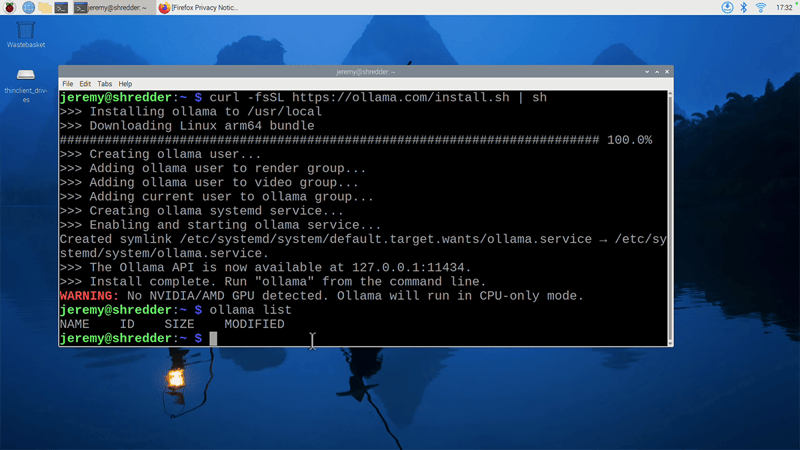
Note that it will say
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
This is because the Raspberry Pi's GPU is not CUDA compatible. However, we can see how it runs on just the CPU.
Step 3: Run DeepSeek R1 Models
Test the 1.5B Parameter Model
Let's start with the smallest model available to try it out. That would be the deepseek-r1 1.5b model model, which has 1.5 billion parameters.
ollama run deepseek-r1:1.5b
Example Prompt:
>>> Tell me a funny joke about Python.
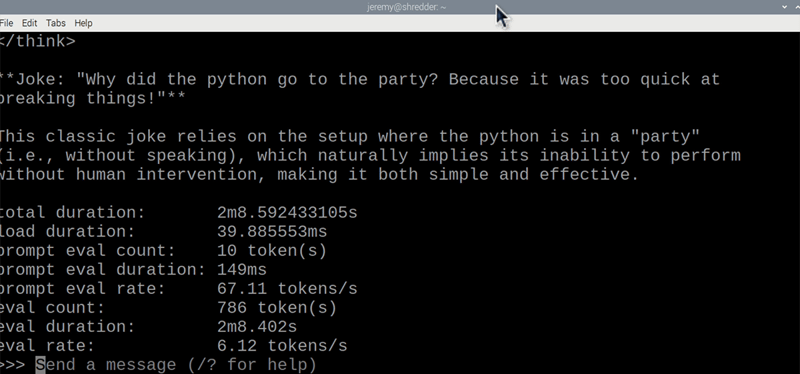
Performance Notes:
- Speed: ~6.12 tokens/second.
- RAM Usage: ~3GB.
- CPU: Consistently maxed at 99%.
So that's not too bad. It's not great, but it might be useful for prototyping and experimenting. You could use this for many tasks as long as it isn't real-time chat or something immediately interactive.
Let's try a bigger model. We know it will be slower, but I want to see if it's possible.
Test the 7B Parameter Model (Optional)
For this test, we'll try the deepseek-r1 7B parameter model. This one is considerably bigger and is a pretty decent model for many projects.
ollama run deepseek-r1:7b
Performance Notes:
- Speed: ~1.43 tokens/second (extremely slow).
- RAM Usage: ~6GB (requires 8GB+ Pi).
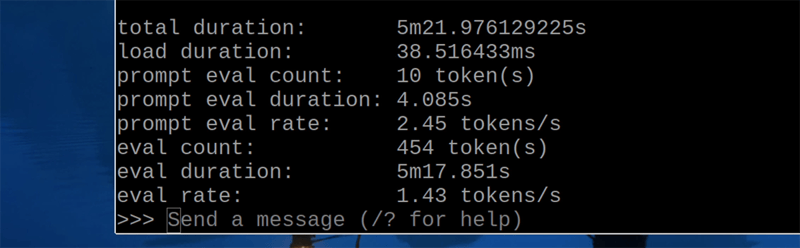
This one is really slow and barely usable. But it's still impressive that you can run a 7B parameter model on a Raspberry Pi, in my opinion. There's not much use for it, but it's possible.
Step 4: Deploy a Dockerized Chat Application
Let's try running a dockerized chat application. This is an application I built for a previous YouTube video. It's a VueJS application that uses the DeepSeek R1 models.
The source code is available here.
Here's how to run it on a Pi:
- Clone the Demo App (replace with your own project):
git clone https://github.com/JeremyMorgan/DeepSeek-Chat-Demo
cd deepseek-chat-demo
- Build and Run with Docker:
docker compose up
- Access the app at
http://localhost:5173and test prompts.
Hey! It runs! Awesome. The responsiveness isn't too bad, it's a little slow but usable.
Step 5: Experiment with a Raspberry Pi Cluster (Extra Bonus Round!)
I decided to drop this on my Raspberry Cluster just to try it out. While this doesn't improve speed (LLMs run on single nodes), it's a fun experiment for distributed workloads.

These Raspberry Pis are all 8GB models instead of the 16GB. Here's how you can set it up:
Set Up Kubernetes using
micorok8sor similar tools.Deploy the App by creating via a YAML manifest (deepseek-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-deployment
labels:
app: deepseek
spec:
replicas: 4
selector:
matchLabels:
app: deepseek
template:
metadata:
labels:
app: deepseek
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: deepseek
topologyKey: "kubernetes.io/hostname"
containers:
- name: deepseek
image: jeremymorgan/deepseek-1-5b-chat-demo:ARM64
ports:
- containerPort: 11435
hostPort: 11435
- Create a service (deepseek-service.yaml):
apiVersion: v1
kind: Service
metadata:
name: deepseek-service
spec:
type: NodePort
selector:
app: deepseek
ports:
- name: http
protocol: TCP
port: 80 # service port (cluster-internal)
targetPort: 80 # container port
nodePort: 30080 # external port on every node
- name: chat
protocol: TCP
port: 11436 # service port (cluster-internal)
targetPort: 11436 # container port
nodePort: 31144 # external port on every node
The responses remain slow, as clustering doesn't parallelize model inference. However, the performance difference between 8GB and 16GB is not noticeable with the 1.5B parameter model.
You can grab the Docker image from here and check it out:
https://hub.docker.com/r/jeremymorgan/deepseek-1-5b-chat-demo/
Key Takeaways
So here's what you'll learn while deploying DeepSeek models to the Raspberry Pi 5.
-
Feasibility:
- The 1.5B model runs acceptably on an 8-16GB Raspberry Pi 5 for lightweight tasks.
- The 7B model will run, but is impractical due to speed (1.43 tokens/sec).
-
Use Cases:
- Educational experiments.
- Prototyping edge AI applications.
-
Optimization Tips:
- Use quantized models (e.g., 4-bit GGUF) for better performance.
- Avoid GUI overhead by running Ollama headless.
Conclusion
While DeepSeek R1 won't replace cloud-based LLMs on a Raspberry Pi, it's a fun way to explore AI on budget hardware. Consider upgrading to a Jetson Nano or used GPU server for better performance.
It's a fun experiment!
Final Results:
| Model Size | Tokens/sec | RAM Usage | Usability |
|---|---|---|---|
| 1.5B | ~6.12 | 3GB | Basic Q&A |
| 7B | ~1.43 | 6GB | Not recommended |
Try it yourself and see how it goes, if you have any comments or questions Yell at me!!

Top comments (4)
Check github.com/b4rtaz/distributed-llama With 4 devices you should get faster inference.
Thank you! Will definitely check this out.
Would running this on an SSD like the 256Gb SSD kit for Raspberry Pi, make this faster? Or is this theoretically limited by RAM?
You're mostly limited by RAM, yes. However an SSD should speed things up. You won't be able to run bigger models, but my assumption is SSD will be faster.