
Word embeddings enable knowledge representation where a vector represents a word. This improves the ability for neural networks to learn from a textual dataset.
Before word embeddings were de facto standard for natural language processing, a common approach to deal with words was to use a one-hot vectorisation. Each word represents a column in the vector space, and each sentence is a vector of ones and zeros. Ones denote the presence of the word in the sentence.
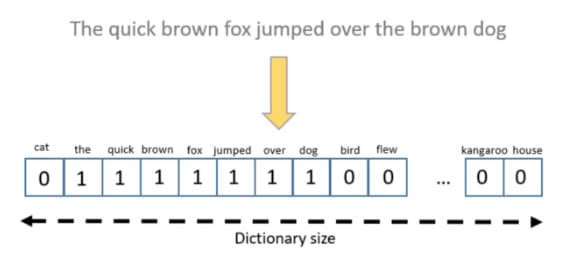
One-hot vectorisation [taken from Text Encoding: A Review]
As a result, this leads to a huge and sparse representation, because there are much more zeros than ones. When there are many words in the vocabulary, this creates a large word vector. This might become a problem for machine learning algorithms.
One-hot vectorisation also fails to capture the meaning of words. For example, “drink” and “beverage”, even though these are two different words, they have a similar definition.
With word embeddings, semantically similar words have similar vectors representation. As a result, “I would like to order a drink” or “a beverage”, an ordering system can interpret that request the same way.
In the past
Back in 2003, Yoshua Bengio et al. introduced a language model concept. The focus of the paper is to learn representations for words, which allow the model to predict the next word.
This paper is crucial and led to the development to discover word embeddings. Yoshua received the Turing Award alongside with Geoffrey Hinton, and Yann LeCun.
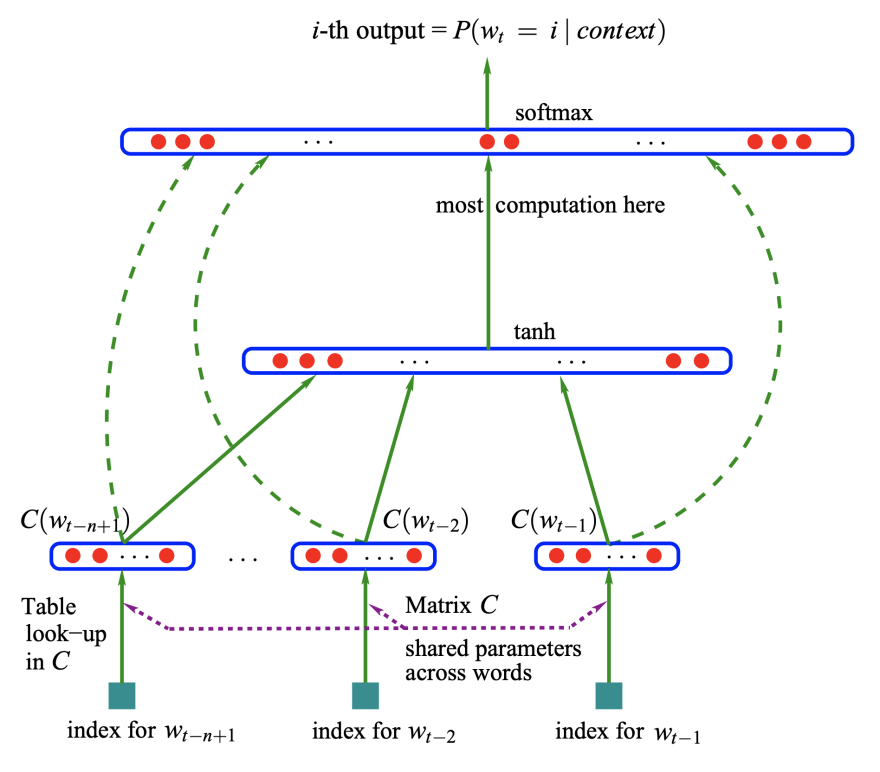
Input sequence of feature vectors for words, to a conditional probability distribution over words, to predict next word [image taken from paper]
In 2008, Ronan and Jason worked on a neural network that could learn to identify similar words. Their discovery has opened up many possibilities for natural language processing. The table below shows a list of words and the respective ten most similar words.


Left figure: Neural network architecture for given input sentence, outputs class probabilities. Right table: 5 chosen words and 10 most similar words. [sources taken from paper]
In 2013, Tomas Mikolov et al. introduced learning high-quality word vectors from datasets with billions of words. They named it Word2Vec, and it contains millions of words in the vocabulary.
Word2Vec has become popular since then. Nowadays, the word embeddings layer is in all popular deep learning framework.
Examples
On Google’s pretrained Word2Vec model, they trained on roughly 100 billion words from Google News dataset. The word “cat” shares the closest meanings to “cats”, “dog”, “mouse”, “pet”.
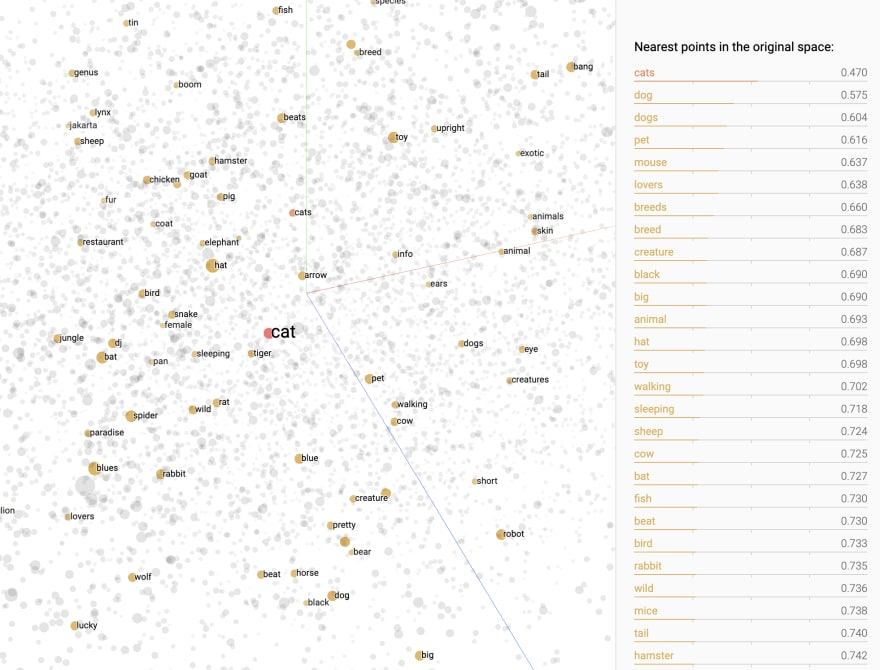
The word “cat” is geometrically closer to to “cats”, “dog”, “mouse”, “pet”. [taken from Embedding Projector]
Word embedding also manages to recognise relationships between words. A classic example is the gender-role relationships between words. For example, “man” is to “woman” is like “king” is to “queen”.
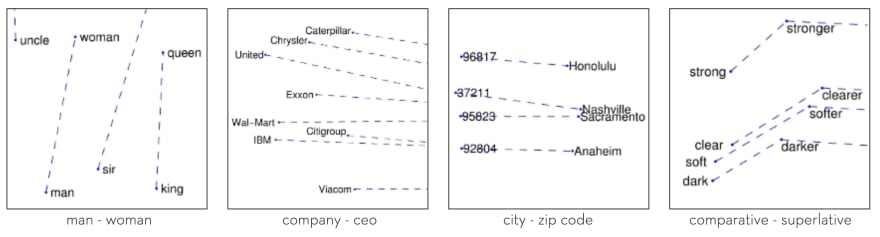
Interesting relationships between words learnt from GloVe unsupervised learning algorithm [image source]
Do it yourself
TensorFlow has provided a tutorial on word embeddings and codes in this Colab notebook. You can get your hands dirty with the codes and use it to train your word embeddings on your dataset. This can definitely help you get started.
For who enjoys animation, there is a cool embeddings visualisation on Embedding Projector. Every dot represents a word, and you can visualise semantically similar words in a 3D space.

Top comments (0)