How to add dynamic data from different pages on a website efficiently!
It’s a challenge that was requested in a real job interview, the purpose of this article is to show the technologies involved and learned during the challenge. Prior knowledge of the Django framework is required.
Challenge
A page Django is developed that presents the requested information automatically and is always up to date, and that page presents the updated numbers promptly.
- The estimated population of cities Natal/RN and Mossoró/RN.
- Sum of the populations of cities.
- Municipal human development index (MHDI) of the cities of Natal/RN and Mossoró/RN.
- The average for the Natal and Mossoró MHDIs.
All of this according to the data on the page
Scrapping
The language Python stands out a lot in data collection on the web. We will use the **Beautiful Soup **module, which creates a tree from HTML and XML documents analyzed on the page.
Starting project
Since you have already created a Django project and have already activated your virtualenv (I advise you to use it).
Let’s use bs4 from Beautiful Soup, we have to install the library in the project, through pip:
(venv) ❯ pip install bs4
HTML
Given that you have already created a templates folder in the app, your structure will correspond more or less this away:
 Structure of Django files and folders
Structure of Django files and folders
Now created an HTML page, in my case index.html, to show the content.
Web Scrapping
Each website has it’s structure so inspect the area you want to capture and analyze, going thought each li inside of the ul in class “resultados-padrao”:
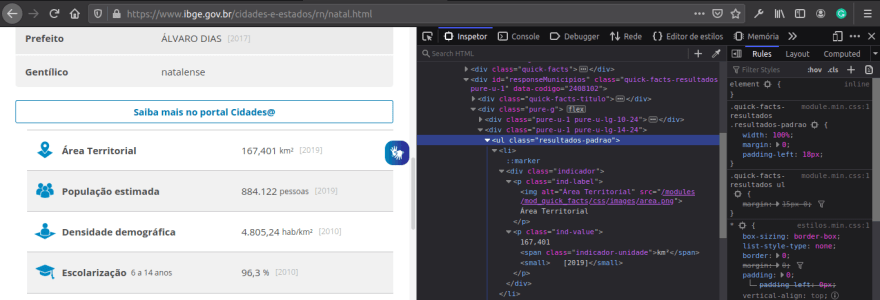
In views, we start by importing the tools to be used and the variables, placing cities and their respective fields:
from django.shortcuts import render
import re
import requests, json, locale
from bs4 import BeautifulSoup
def index(request):
city = [
{'state': 'rn', 'name': 'natal'},
{'state': 'rn', 'name': 'mossoro'}
]
fields = [
'População', 'IDHM'
]
city_values = []
context = {}
return render(request, 'ibge/index.html', context)
In the cityData function, pass the city variable as a parameter, scrolling by name and state, call the pages by the URL parameter through the cities, after capturing the page labels and values.
If the selected fields are the same as the ones requested, save them in the arrays, after returning city_data.
def cityData(city):
city_data = []
for item in city:
# convert and read in json
item = json.dumps(item)
item = json.loads(item)
name = item['name']
state = item['state']
url_request = requests.get("https://www.ibge.gov.br/cidades-e-estados/"+ state +"/"+ name +".html")
div_select = BeautifulSoup(url_request.content, 'html.parser')
ul = div_select.find(class_='resultados-padrao')
city_label = ul.findAll("p", {"class": "ind-label"})
city_value = ul.findAll("p", {"class": "ind-value"})
data = []
for label, value in zip(city_label, city_value):
text_label = label.text
text_value = value.text
if text_label.split()[0] == fields[0] or text_label.split()[0] == fields[1]:
data.append([text_label, text_value])
city_values.append(text_value.split()[0])
data.append([name, state])
city_data.append(data)
return city_data
In conclusion, the expected result from views is this:
Conclusion
After that, we’re done. Use this command to run the web application:
(venv) ❯ python manage.py runserver
 Page rendering IBGE data.
Page rendering IBGE data.
In this tutorial, we used Python, Django, and Beautiful Soup to collect data. You now have great possibilities for development.
I hope you enjoyed the content! If you have suggestions and/or criticisms comment below. Bye! 🖐🏽

Top comments (0)