How to use System.IO.Pipelines and System.Threading.Channels APIs to speed up processing
This post is kind of the continuation of my previous post series: Evaluating “ReadLine using System.IO.Pipelines” Performance in C#.
When I wrote those posts, I was in the need of processing a huge text file (hundreds of thousands of lines), read, parse and transform line by line, and then finally save each of them as a text file. Yes, it will end up a ton of files being created!
I was able to speed up the reading time using System.IO.Pipelines APIs as described in the previous post. The result? 10 minutes faster processing time! 🚀
I could have stopped there. But I didn’t. I recalled the new kids on the block: System.Threading.Channels. See Stephen Toub’s excellent post “An Introduction to System.Threading.Channels” for more information.
An Introduction to System.Threading.Channels | .NET Blog
Think of the reading line by line as the Producer and the line processing part as Consumer. The idea is, to produce as fast as possible using System.IO.Pipelines and consume it— spread the workload concurrently, asynchronously, without blocking like BlockingCollection does.
BlockingCollection involves blocking; there are no task-based APIs to perform work asynchronously. Channels is all about asynchrony; there are no synchronously-blocking APIs — Stephen Toub.
Okay, enough talking. Show me the code!
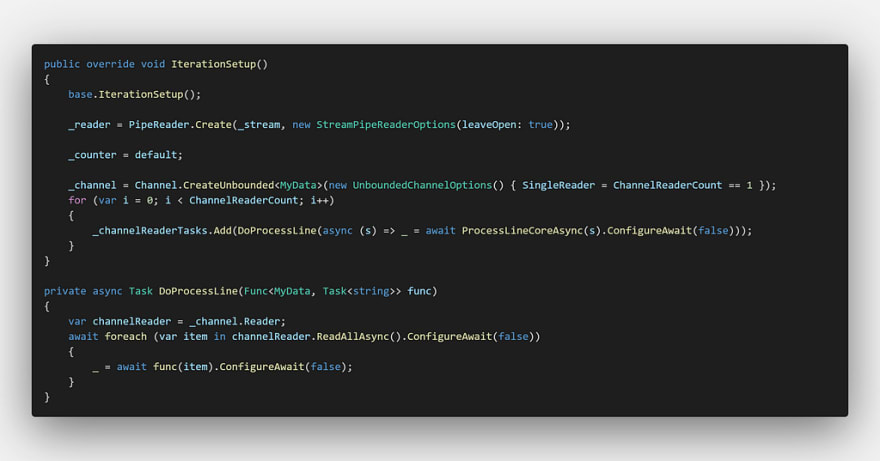
Base Implementation
Let’s start from the base implementation (i.e., before using System.Threading.Channels APIs); the code is simply adding each line processing method to the Task list and await on all of them.
Note that code on this post is slightly adjusted for benchmarks purpose; eliminating unrelated parts as much as possible.
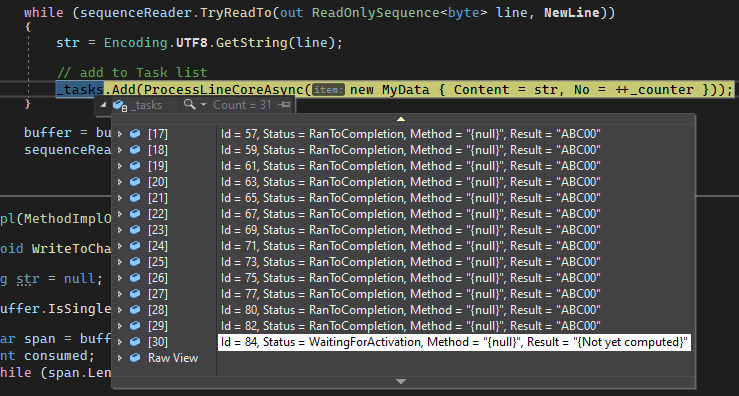
We can see the task list growing as we process the line.
Channel Writer (Producer)
Here is the producer part.
To help spot the changes quickly, here is the diff:
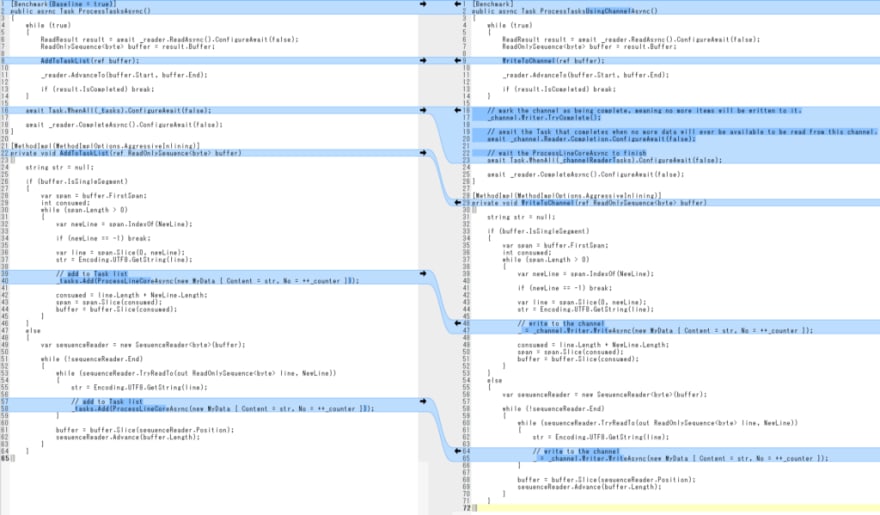
Should be pretty easy to spot the differences.
Channel Reader (Consumer)
Finally, the consumer part.
Here I defined 3 channel readers and set SingleReader to false (by evaluating ChannelReaderCount == 1). This way, we will have 3 consumers that will process the line concurrently.
This can be observed from the Visual Studio Parallel Stacks window.
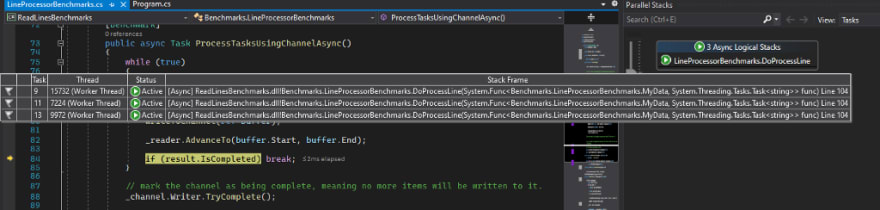
Tune this value and measure until you get the best performance. Start small, increment the value until you reach to the point where it will give you slower results; it’s the point where you have too many active Task resources, possibly too many context switches.
Benchmarks Result
Okay, let’s see the benchmarks result.
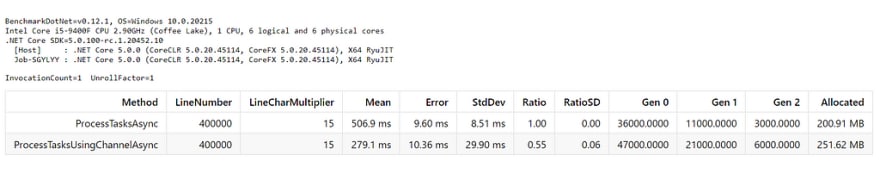
*Wow. Almost 2x faster! * 🚀🚀🚀
Here is the gist version:
That’s the benchmarks result. What about my case? Well, I saved another 10 minutes, so about 20 minutes faster in total!
Source Code
You can find the source code in my GitHub repository, branch: pipelines-and-channels.
Conclusion
If you have huge text files in size containing hundreds of thousands of lines to be processed, consider to use System.IO.Pipelines for reading and parsing the lines, and combine it with System.Threading.Channels APIs to spread the workload concurrently, asynchronously.

Top comments (1)
Great, thank you