Evaluating “ReadLine using System.IO.Pipelines” Performance in C# — Part 2
Read string line by line using System.IO.Pipelines API in C
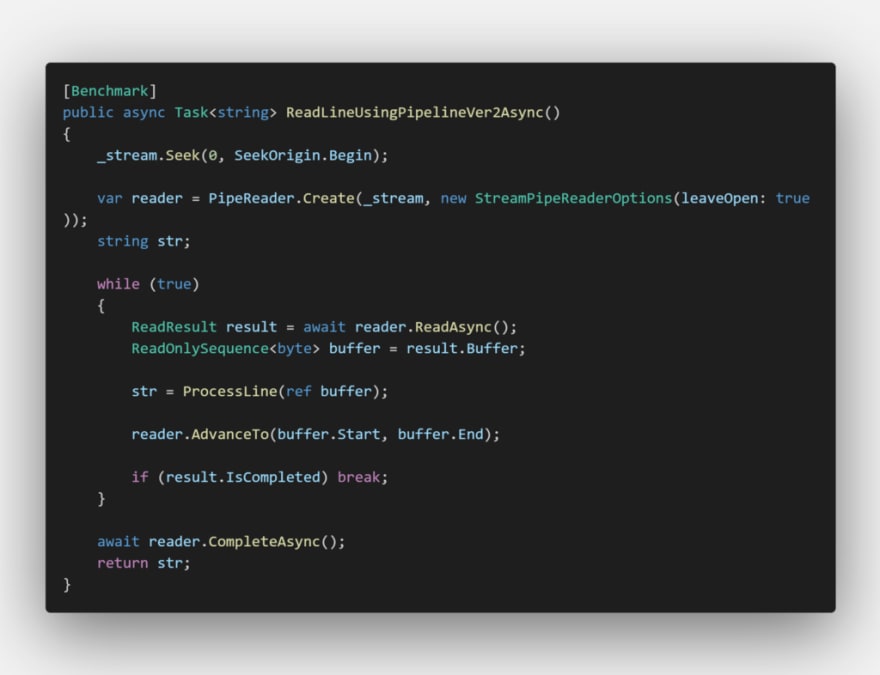
On part 1 of this series, I concluded:
In terms of speed, it is surprisingly slower than the ordinary ReadLine version given the string length ≤ 80 (perhaps I am doing it wrong? Let me know! I am still learning!). It is starting to shine, getting faster and faster if the string length ≥ 90. (270% 🚀 faster for string length = 1000).
I decided to take a further look and added more patterns to the benchmarks. The new code, instead of blindly using SequenceReader, is a mix of fast ReadOnlySpan and slow SequenceReader; by inspecting ReadOnlySequence.IsSingleSegment property.
The idea is, get a Span once and then pull as many lines as possible out of it before moving to the next segment of the sequence, as also pointed out by a generous Reddit user u/scalablecory, thanks! (apparently a member of the .NET Team?!)
Here is the result:
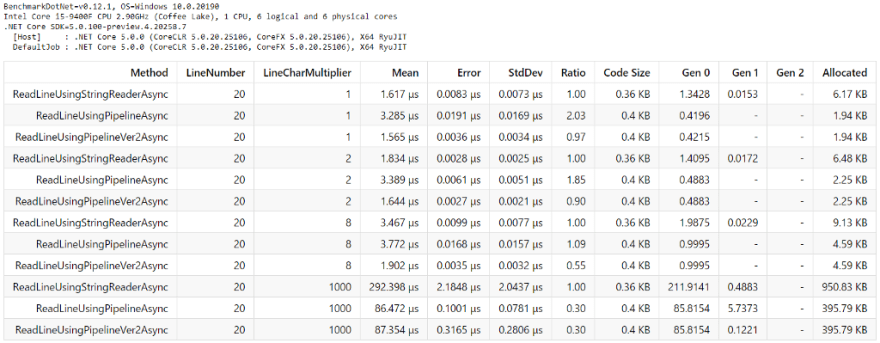
As you can see, it performs well under every test case, rendering my previous conclusion obsolete!!!
And here is the gist version:
Noticed that this time it has fewer test cases; I reduced some LineCharMultiplier variations, as I don’t think we need it.
You can find the source code in my GitHub repository.
Conclusion
- Pipelines versions are better in terms of memory usage (using less memory).
- In terms of speed, it is 103% ~ 333% 🚀🚀🚀 faster, depends on the string length.
- Less GC pressure (a good thing) for Pipelines versions (Gen 0, Gen 1).
- The amount of code to write for the Pipelines version is super longer!
DISCLAIMER: Your mileage may vary. As with all performance work, each of the scenarios chosen for your application should be measured, measured and measured. There is no silver bullet.

Top comments (0)