Read string line by line using System.IO.Pipelines API in C

A typical approach for reading a string line by line from a file would probably be using ReadLine APIs. I have heard all good things about System.IO.Pipelines, which was born from the work of the .NET Core team to make Kestrel one of the fastest web servers.

 Ben Adams #BlackLivesMatter@ben_a_adams
Ben Adams #BlackLivesMatter@ben_a_adams Round 19 of @TFBenchmarks is out and ASP.NET Core on Linux racing to the top!
Round 19 of @TFBenchmarks is out and ASP.NET Core on Linux racing to the top!
Who would have thought .NET would have been fully OSS and top performer *on Linux* a several years ago? #aspnetcore #dotnet
techempower.com/benchmarks/#se…23:04 PM - 28 May 2020
168
379
Although it is probably better suited for network socket IO, I was wondering how easy and how does it perform compared to the traditional ReadLine APIs? So I decided to give it a spin by creating simple benchmarks using BenchmarkDotNet as part of my learning journey.
But, for this post, instead of using a file as the source of the stream, I decided to use in-memory, presumably more-stable-for-benchmark MemoryStream. Feel free to modify it to use a file as the stream source and try it yourself.
The code for ReadLine is so dead simple; nothing fancy here.
(My apologies for the possibly misleading method name ReadLineUsingStringReaderAsync; it doesn’t use StringReader class at all).
You will probably spot that unfamiliar C# 9.0 Pattern Combinators is not null; Yes, I’m using the latest (at the time of writing) .NET 5 Preview 7 (5.0.0-preview.7) and the preview version of Visual Studio (Version 16.8.0 Preview 1.0). Don’t blame me, I love bleeding edge stuff!😎
See how is not null is transformed here.
To simplify the processing of a ReadOnlySequence, here I used SequenceReader; taken from the official sample here, modified it slightly to make it follow a similar pattern while (... is not null) as ReadLineUsingStringReaderAsync does.
And finally, here is the result: 40 benchmarks in 15 minutes on my machine.
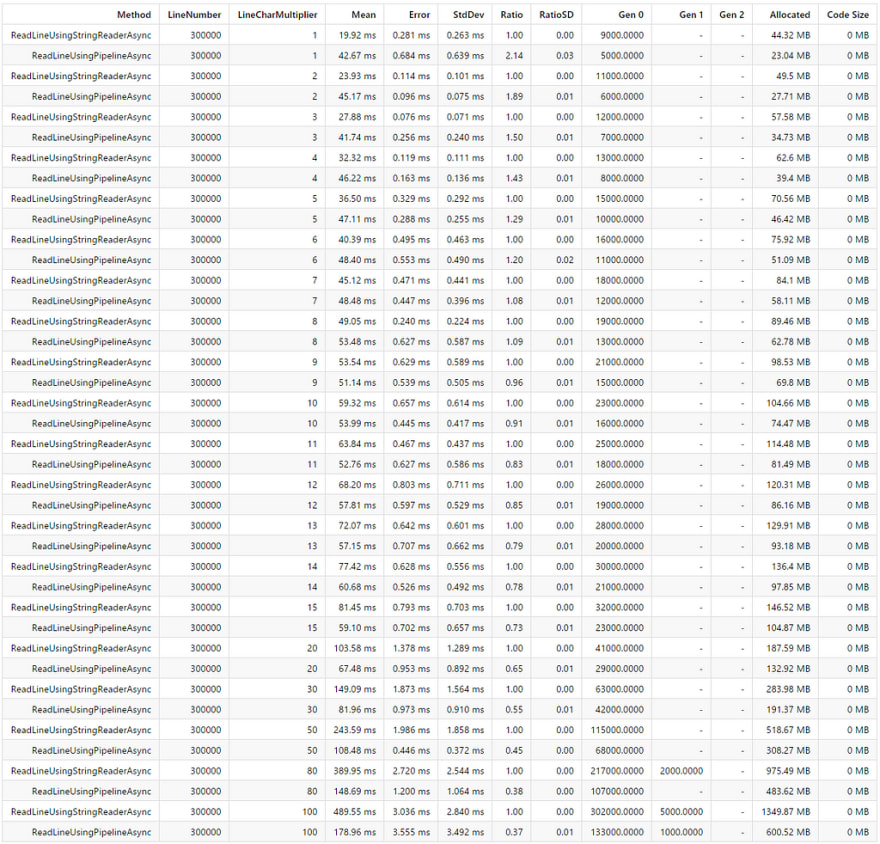
Here is the gist version:
Legends:
LineNumber : Value of the 'LineNumber' parameter
LineCharMultiplier : Value of the 'LineCharMultiplier' parameter
Mean : Arithmetic mean of all measurements
Error : Half of 99.9% confidence interval
StdDev : Standard deviation of all measurements
Ratio : Mean of the ratio distribution ([Current]/[Baseline])
RatioSD : Standard deviation of the ratio distribution ([Current]/[Baseline])
Gen 0 : GC Generation 0 collects per 1000 operations
Gen 1 : GC Generation 1 collects per 1000 operations
Gen 2 : GC Generation 2 collects per 1000 operations
Allocated : Allocated memory per single operation (managed only, inclusive, 1KB = 1024B)
Code Size : Native code size of the disassembled method(s)
1 ms : 1 Millisecond (0.001 sec)
You can find the source code in my GitHub repository.
Conclusion
- Pipelines versions are better in terms of memory usage (using less memory).
- In terms of speed, it is surprisingly slower than the ordinary ReadLine version given the string length ≤ 80 (perhaps I am doing it wrong? Let me know! I am still learning!). It is starting to shine, getting faster and faster if the string length ≥ 90. (270% 🚀 faster for string length = 1000).
- Less GC pressure (a good thing) for Pipelines versions (Gen 0, Gen 1).
- The amount of code to write for the Pipelines version is longer.
[Update] See part 2 of this series for a better version! (Spoiler: faster on every test!)
DISCLAIMER: Your mileage may vary. As with all performance work, each of the scenarios chosen for your application should be measured, measured and measured. There is no silver bullet.

Top comments (1)
What if the line is longer than buffer?