Here are eight key database design rules, which are aimed to make your life easier. As it turns out, we often forget about painfully obvious things, so being prudent and wise stands above all rules.
#1: Figure out the nature of the application: OLTP or OLAP
When you start your database design the first thing to analyze is the nature of the application you are designing for, is it Transactional (OLTP) or Analytical (OLAP). If you think CRUD i.e., creating, reading, updating, and deleting records are more prominent then go for a normalized table design, else create a flat denormalized database structure.
#2: Break your data in to logical pieces
You probably will need to apply this rule if your queries are using too many string parsing functions like substring, charindex, etc. Sometimes it is better to break fields into further logical pieces so that clean and optimal queries could be written.
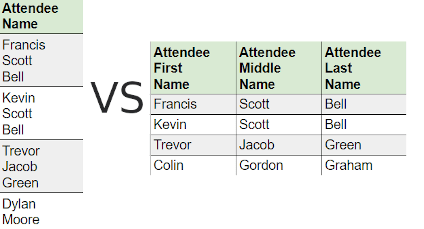
#3: Do not get overdosed with breaking your data
When you think about decomposing, give a pause and ask yourself, is it needed? For example, here’s the base of phone numbers. It’s rare that you will operate on ISD codes separately until your application demands it. So it would be a wise decision to just leave it as it can lead to more complications.

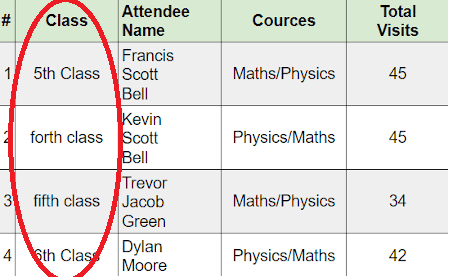
#4: Avoid non-uniform data
Focus and refactor duplicate data. For instance, in the below diagram, you can see “5th Class” and “Fifth class” means the same. If you ever want to derive a report, they would show them as different entities, which is very confusing.
#5: Avoid repeating groups
One of the examples of repeating groups is explained in the below diagram.These kinds of columns which have data stuffed with separators need special attention and a better approach would be to move those fields to a different table and link them with keys for better management.

#6: Choose derived columns preciously
If you are working on OLTP applications, getting rid of derived columns would be a good thought, unless there is some pressing reason for performance. In the case of OLAP where we do a lot of summations, calculations, these kinds of fields are necessary to gain performance.
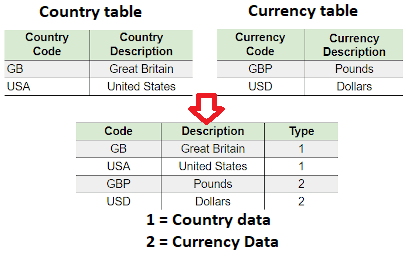
#7: Centralize name value table design
Name and value tables means it has key and some data associated with the key. For instance in the below figure you can see we have a currency table and a country table. If you watch the data closely they actually only have a key and value. For such kinds of tables, creating a central table and differentiating the data by using a type field makes more sense.
#8: Do not be hard on avoiding redundancy, if performance is the key
Do not make it a strict rule that you will always avoid redundancy. If there is a pressing need for performance think about de-normalization. In normalization, you need to make joins with many tables and in denormalization, the joins reduce and thus increase performance.
As a bonus, I would recommend using dbForge Studio. The solution will help you to avoid a whole bunch of mistakes while developing and managing databases. The following features will be especially useful:
1) Database Diagram which shows the structure of an already created database. It often helps to decide whether tables and the relationships between them have to be redesigned;
2) Visual Table Editor provides convenient editing, filtering, sorting, copying of randomly selected cells, quick data export to INSERT query and many more;
3) Data Editor to view data, edit, and roll back changes, if necessary;
4) Source Control to make controlled changes to the database during teamwork with the ability to view the history of changes (including revision ID, date, author and comments);
5) Schema Compare to compare the developed and live versions of the database and understand what differences they have;
6) Query Profiler allows comparing the performance of modified queries with current ones.

Top comments (1)
Ssms visual editors might seem like the easy choise to work with but are not the recommended way to work with Sql Server.
Check out Aaron Bertrand's Bad habits to kick : using the visual designers for details.