There comes a time in many MongoDB database, or any database for that matter, life cycles in which our data outgrows our servers. Either physically outgrows storage capabilities or the data grows so large that performance is degraded. Even scaling our physical servers up with a more powerful CPU, more RAM, or hard drives (vertical scaling) may not be enough. This is where horizontal scaling through sharding comes into practice.
Sharding
What is sharding exactly? It is the practice of distributing data across multiple machines. In MongoDB it supports instances with large data sets and needed high throughput operations. The data is distributed across all shards allowing the workload to be evenly shared. This has the potential for much better efficiency than a single server.
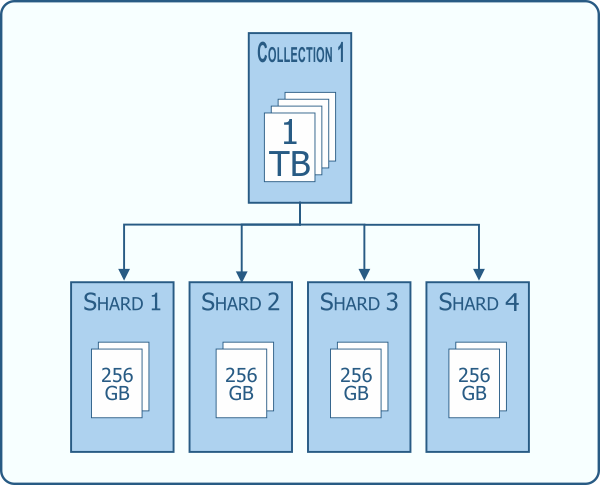
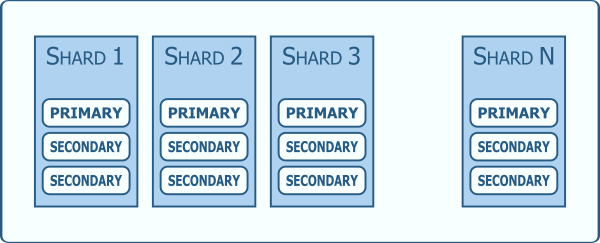
Each cluster should, for redundancy, also be replica sets with primary and secondary servers.
MongoDBÂ data is sharded at a collection level, therefore it isn't necessary to distribute the entire database across a sharded environment.
Cluster Configuration
There are three components to a sharded cluster that we need. We need the shards themselves, a query router in the way of a mongos server, and configuration or config servers.
The shards are what store the subset of the data. The config servers store all of the metadata about the cluster and which shard houses what data. Data is stored in chunks on each shard and the config server keeps track of all that information.
The mongos, in its role as a query router, acts as the interface between the application and the data. It routes queries and write operations to the appropriate shards. An application, therefore, will only access the data through a mongos, never by touching the data itself. Queries are routed via the mongos to all shards unless it can be determined the data resides on a particular shard.
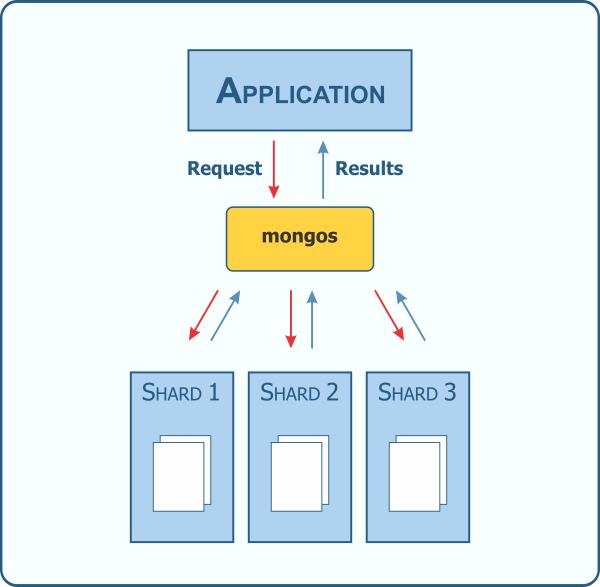
There has to be a better way than broadcasting that request to all shards though, right? As you might imagine, this "scatter/gather" approach to querying can result in some long running operations. Well, I kind of eluded to it before by qualifying it with the "unless", so there is a better way! Enter the shard key.
Shard Keys
A shard key determines how documents in a collection are distributed across the shards. It is an indexed field, or indexed compound fields, that exists in every document in the collection. Recall that MongoDB allows for a flexible schema within the document model. This is one consideration when choosing a shard key; every document must have the indexed field.
If provided with a shard key during a query, the mongos knows how to route the request.
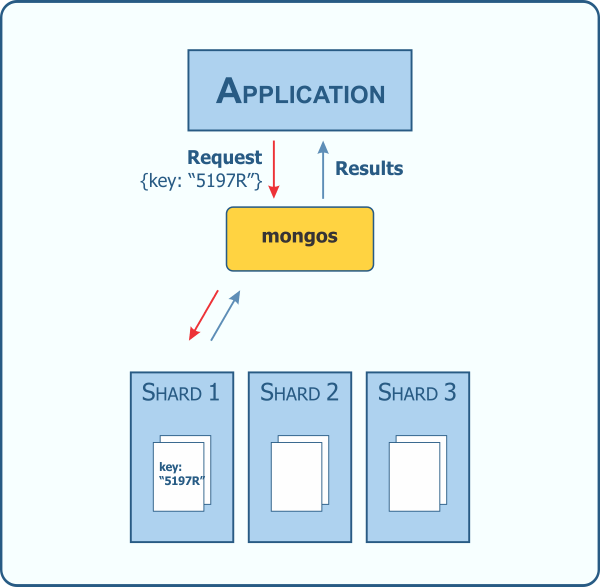
This can greatly enhance performance. Choosing a good shard key, however, is very important. I'll cover what goes into the selection of a good shard key in a future post.
Trade offs to Sharding
As the saying goes, there's no such thing as a free lunch. Sharding is the same way. Sharding your data sets increases infrastructure complexity as well as maintenance. One solution to help mitigate both of these is to utilize a DBaaS such as Atlas to host your MongoDB data.
If queries are run without including a shard key, the "scatter/gather" approach is used. This can result in slow queries, therefore it is definitely something to remember when writing your applications.
Once a collection is sharded, it cannot be unsharded. Similarly, once a shard key is selected, it cannot be changed. So these steps need to be undertaken with careful planning.
If you are handling things yourself on your own hardware I have briefly discussed some of the tools which can be used to check performance of a sharded collection in previous posts. Specifically in MongoDB CLI Tools and briefly in MongoDB explain() explained.
Wrap Up
When your data has outgrown a single server, sharding is a great approach to keep your database performing well. There are some things to watch out for though. Make sure you choose a good shard key and stay up to date with database maintenance.
There are a lot of MongoDB specific terms in this post. I created a MongoDB Dictionary skill for the Amazon Echo line of products. Check it out and you can say "Alexa, ask MongoDB what is a Shard?" and get a helpful response.
Follow me on Twitter @kenwalger to get the latest updates on my postings, or see the original post on my blog.

Top comments (0)