
Introduction
I have been digging into Git internals to really understand the tool beyond the basics and gain an indepth understanding of how git does what it's known for -- Version Control. In this article I intend to share with you my discoveries by exposing git internals in simple language as much as possible for any Git user to comprehend the core concepts behind this amazing tool.
Important: This article is not an introduction to Git material but it's intended to show you how Git is able to keep track of the various versions of your project files. If you're new to Git, follow this Git documentation to get to read the documentation or download progit to get an awesome explanation of Git basic's, then you can comeback to read this article for a deeper dive into Git.
GIT FRONT-END (What you already know)
You surely know by now that Git at it's core is a version control system (VCS) used by people(Now i did not say developers, anyone can use git for instance I used git to keep track of the various versions of this article as i wrote and made changes before publishing) to keep track of the different versions/iteratons of their project files(documents).
Before Git numerous VCS existed e.g CVS, subversion, perforce and they are all categorized under the Central version control system (CVCS) which means that all the versioned files are stored in one database and every other person(client) working with/on that project will have to connect to the central database (All commits goes into this singular database).
Git on the other hand falls under the category of Distributed Version Control System (DVCS), which means that there are no central database where people have to push or save files to. Every Git user computer serves as a database for the files, it means that everyone working on the project has the whole history of the project living in their local machine as at the time they cloned the project. So where does this database sit in your computer? i'm pretty sure if you check your project directory were you use Git you will see only your project's sub-directories and files. I'd be exposing this Git magic inabit
GIT INTERNALS
What makes a project directory a git repository is the hidden .git directory living in that project directory. The .git folder houses the Git Object database and this is where the Git magic happens. This folder is intentionally hidden to avoid stories that touches the heart (file mutaion, mistakes) and to maintain Git integrity. If you're a windows geek, you can view this folder by enabling show hidden files feature, follow this tutorial if you have no clue how to do this, if you're a mac user, here is your link.
The .git directory houses some other directories and files and it looks like this:
- .git/
- hooks
- info/
- exclude
- objects/
- info
- pack
- refs/
- heads
- tags
- config
- description
- HEAD
Git is able to effectively manage different versions of your project because it is designed to track file contents and store's the tracked contents as Objects in an Object database.
OBJECTS DIRECTORY
Git works as a content addressable filesystem which means that Git stores it's files(objects) using a key:value pair format, where the key is the address where Git stores the content(refered to as objects) which is the value.
Git uses SHA-1(Secure Hash Algorithm) to generate a unique key for every object is stores. The SHA-1 generates 40 character long alpha-numeric character to reference the objects stored in the object database eg f7de3a39b026386f8f826bc230a112ae792ec035
This object directory is the location were Git stores every object i.e the object directory is the object database.

There are three major object types stored by Git in the object database(Object directory), they are:
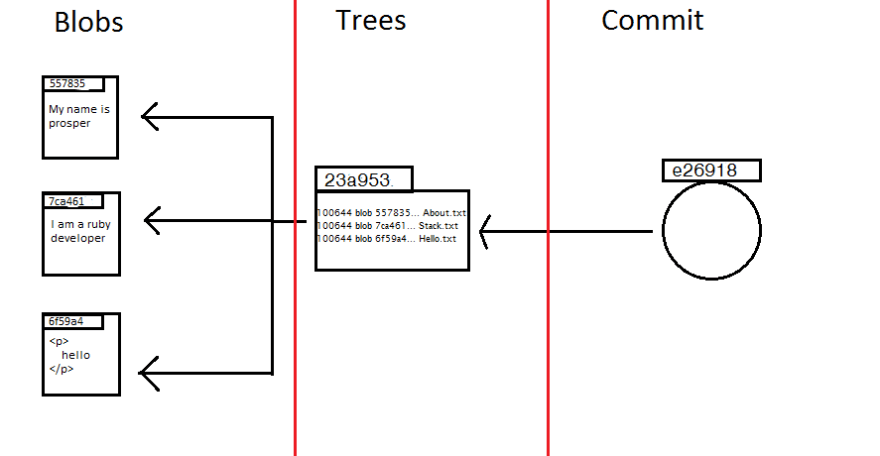
Blobs Object - Git stores file contents as blobs. It is important to note that blobs do not include the file name or the file mode, rather they are strictly contents from the files Git is versioning. The SHA-1 serves as the filename(key) for the blob contents(value).
Tree Object - Tree objects are like directories, they contain blob objects and other tree objects. Tree objects are snapshots of your working directory at the time of your last commit.
Commit Object - Commit objects basically stores details of the last commit of the currently checked out branch (this is referenced as parent), a pointer to the current tree object for the commit, the name of the committer, and the actual commit message.
Git object types are organized in sub-directories git automatically creates when trying to store the objects. The sub-directory are named using the first two characters of the SHA-1, and the object are stored in a file named using the remaining 38 hash keys.
Objects/
f7/
de3a39b026386f8f826bc230a112ae792ec035
GIT IN ACTION
In this section we will be doing some versioning and seeing for ourself how Git objects are created and stored in the object database, i belive everything will begin to make more sense by the end of this section.
I will be working with git bash for the demostrations.
Open up your terminal/cmd and Cd into any directory of your choice, and type the command
$ git initto create an empty Git Repository. In my case i got the messageInitialized empty Git repository in C:/Users/opara prosper/Desktop/GitHub Projects/Git-Backend/.git/you would surely get a message similar but with a different directory.Open up a new terminal and cd into the project directory and place both terminals side by side, this will enable us keep track of what is happening inside the .git directory.
Create a new file
example.txtto containHello worldas it's content - you can do this from your terminal by typing the following commandcat > example.txtthen type the content on the new line, save and exit with CTRL DOn the second terminal you opened type this command
find .git/objects -type fyou will not get any response because there is nothing in the objects directory but that will soon change.Now on the first terminal we initially opened, type in the command
git add example.txtto move the file to the staging area.Navigate back to the second terminal you opened and type
find .git/objects -type f. Now you'd get a response that looks like this.git/objects/70/c379b63ffa0795fdbfbc128e5a2818397b7ef8your's will be different because SHA-1 creates random keys for git objects. This means an object has been added to Git's object database but we don't know what that is yet. If you typegit cat-file -p 70c379b63ffa0795fdbfbc128e5a2818397b7ef8you'd notice hello world is returned, but the file name example.txt is no where to be found, this reinforces my claim of Git being a content tracker.
When you ran the git add example.txt command, Git grabbed the contents within eample.txt and compressed it into the git object database and gave it a unique identifier 70c379b63ffa0795fdbfbc128e5a2818397b7ef8 using SHA-1. To check the type of object this is type the following command git cat-file -t 70c379b63ffa0795fdbfbc128e5a2818397b7ef8, in our case a blob is returned meaning that the newly created object is a blob object.
Going back to our first terminal, type the following command
git commit -m "I created an example.txt file"to commit your changes(i.e to move your changes from the staging area into the .git directory).Naviagate back to the second terminal and type
find .git/objects -type f, this time you'd notice that two new objects have been added to the objects directory, in my case;
.git/objects/70/c379b63ffa0795fdbfbc128e5a2818397b7ef8
.git/objects/7a/68edc879868601bf427c8c2238bbc8752c33b3
.git/objects/f2/9f2741b30ecc1529da7dbae4aff9974b69e271
Lets inspect these objects, grab the any of the object and type git cat-file -t 7a68edc879868601bf427c8c2238bbc8752c33b3. In my case commit was returned and this means that this object is a commit object, to view this object chnage the -t flag from our previous command to -p i.e git cat-file -p 7a68edc879868601bf427c8c2238bbc8752c33b3 you'd get a response that looks like this;
tree f29f2741b30ecc1529da7dbae4aff9974b69e271
author OPARA-PROSPER <oparaprosper79@gmail.com> 1541583214 +0100
committer OPARA-PROSPER <oparaprosper79@gmail.com> 1541583214 +0100
I created an example.txt file
Let's look closely at what this means. The first line tree f29f2741b30ecc1529da7dbae4aff9974b69e271 is a pointer to the second object that was created when we committed last (this object is always a tree object), the second and third line contains information about who made the commit and the last line contains the commit message.
- Now we will inspect the second object which was created alongside the commit using
git cat-file -t f29f2741b30ecc1529da7dbae4aff9974b69e271. Atreeresponse is returned which means that the object is a tree, we can view the contents of this tree object by changing the-tflag to-pi.egit cat-file -p f29f2741b30ecc1529da7dbae4aff9974b69e271, this will return a response that looks like this;
100644 blob 70c379b63ffa0795fdbfbc128e5a2818397b7ef8 example.txt
Recall from my explanation that tree objects are like directories that contain blobs and other trees and also they are snapshots of the current state of your working directory at the time of your last commit. The only file in our working directory at the time we last commited is the example.txt file and thats what our tree object contains but this time its the blob object that was created when we ran the git add command to stage our changes. This is so because Git does not track files but contents.
Our tree object contain information on the file mode (100644 which means this is a normal file), the object type, the SHA-1 key and the file name from which the contents where extracted from.
WRAP UP
The more changes you make, stage and commit the more new blobs, tree and commit objects will be created and referenced in the objects database.
In conclusion, this is virtually how Git works under the hood to keep track of the changes we make to our project files.

Top comments (7)
I really enjoyed this.
Thanks for reading 🙏
Cool man, very helpful!
I'm glad you found it helpful
Nice article man, very insightful.
I'm glad you got something from it <3
Really interesting how Git tracks the files of a repository. Really helpful!