Using a story-telling example, I would like to differentiate between schema on read and schema on write.
Ria is running a retail shop. She had to store a lot of information on products, sales, customers and many more. Lets focus on the use case of product table here.
When she started storing the data, she created a product table with the following fields - 'product id' of type number which is the primary key, 'product name' of type text with unique constraint, 'cost' of type float, 'category' of type text, 'base discount percentage' of type float.
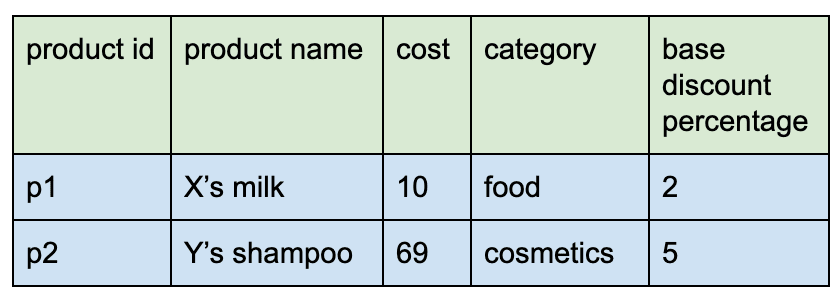
Six months had passed and she had about a few thousand records in it. To expand her customer base, she introduced promotional discount for her products. She had to alter the table definition to add a new column 'promotional discount percentage' of type float.
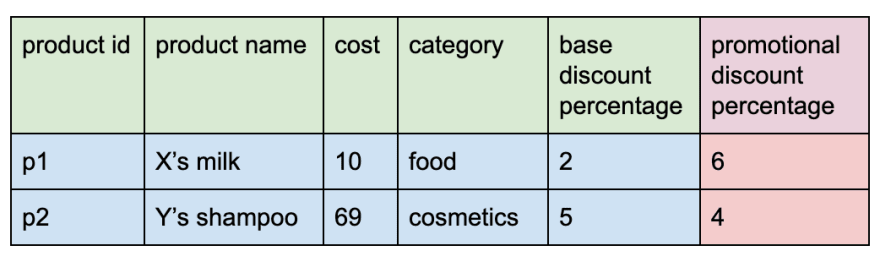
After a few months, she realized that it would be beneficial to store the supplier information in the product table. Again, she had to alter the table to add a new column 'supplier'.
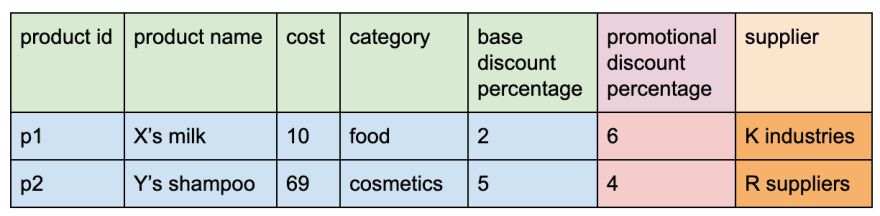
The next day, she was talking with her data analyst, Tim. Tim helps in calculating the recommended price of products based on various factors. After talking, she realized that Tim did not need the supplier column, yet the table he used for analysis had the supplier column. She felt it was unnecessary to have the columns one does not need. But she could not remove that column since she needed it for logistics purposes. She was perplexed.
Later, one day, she was taken aback to know that product name is not unique. It looked like product names can repeat with different categories. Because of the unique constraint, she was not able to put some product data into the table. She had to remove the unique constraint from the table immediately to avoid data loss.
She had to face similar problems frequently until she met her friend Amy. Amy patiently listened to her problem. She explained to Ria that she has been following 'schema on write' approach for her data. She added that 'schema on read' would have been a better fit for her use case.
Schema on write
'Schema on write' approach is where we have a predefined schema for the data. Traditionally, most applications use relational databases to store data. In relational databases, we have multiple tables which has well defined column names, data types, constraints and even indexes. This is suitable for transaction data.
Schema on read
'Schema on read' approach is where we do not enforce any schema during data collection. When reading the data, we use a schema based on our requirements. In our example, Ria could have two different schemas: one with 'supplier' column for her logistic needs and one without 'supplier' column for the data analyst.
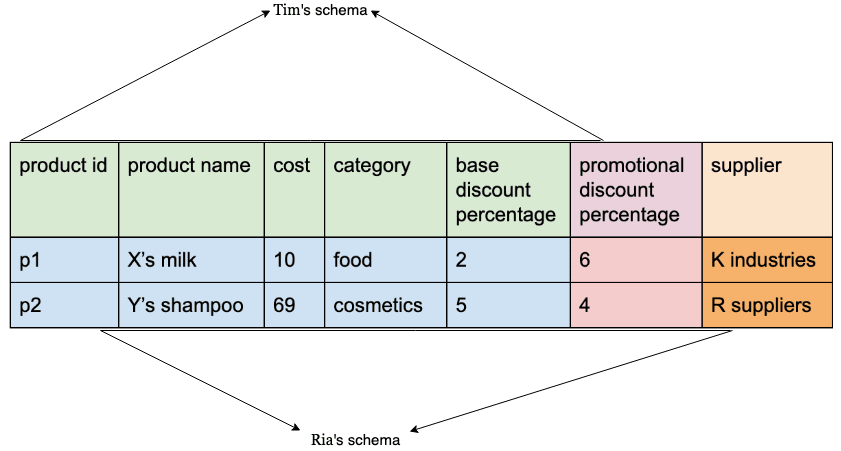
If there is an additional column coming as part of the data, that would be collected even before modifying the schema. Schema can be modified to include the additional column if it is needed. One big risk with Schema on Write is that schema is enforced on data up front and there are chances that we might lose additional information.
Also if any constraint in schema used for reading is not satisfied, it does not affect data collection. Data collection is independent of the schema.
Ria understood what Amy suggested. She agreed that 'schema on read' would have been a better fit for her use case and started working towards it.
Thanks for reading! Please post your feedback and comments.

Top comments (2)
The first thought I had was, if the extra column is unnecessary for some consumers, like the data analyst, traditional relational databases have the select statement to select only some columns, or there are other operators that can help view only some parts of the table. Would that also be a solution to that problem?
Another thought I had was - in between I got the sense that - data collection is easier if schema is not checked before writing data, which is the case for traditional relational databases with schema already defined, so, we could use databases / stores that don't enforce schema. But when reading does it mean the if a data does not conform to the schema I expect, then that data alone won't be parsed / read ?
Using select statement for selecting only some columns would work. Still, in big data world, where we are storing data in denormalized format, there might be more than 100 columns. So, a consumer has as additional overhead to find and select the columns they need. This can be overcome by having schema based on specific needs of the consumer. The consumer need not even know about other columns.
When reading the data, if schema does not conform, we would face issues in reading the data. Eg: If my schema has a column which data does not have, I cannot read the data based on that schema.