
Philosophers, politicians, and visionaries are talking about a future in 2030 in which autonomous vehicles will be driving through the streets, cities will be able to adapt efficiently to environmental influences, and digitization will be a crucial tool for operating efficiently and saving resources.
The world we live in today is subject to constant technological change. With the commercialization of the Internet, companies quickly recognized the value of data. The most authoritative innovations of this time are based on fast data-driven decisions and intelligent algorithms fed by the constant linking of data.
Examples include the recommendation algorithms of Amazon, Youtube, and Netflix or surge pricing of Uber and Airbnb and any Ad-based business (hello Facebook).

Data are archived building blocks of knowledge that can be used to be more predictive in a world of rapid change and shape the world into a better place.
Governments launched open data initiatives. Public data is made available to the general public so that businesses and individuals can work with the data. Data scientists, professions that use programming to analyze large amounts of data, became the sexiest job description in the technology world and, as a result, a scarce resource for companies.
They are under enormous pressure by expectations to make the world and especially the company more innovative.
While at the same time, they face a massive flood of data from a wide variety of data sources and formats. Surveys and studies show that data scientists spend up to 80% of their time searching, collecting, preparing, and integrating data. Rarely are the desires of policymakers and businesses and the true reality so far apart.

I worked as a Data Scientist and Data Consultant for many larger companies.
In a project for the city of Leipzig, I advised their administration on its Open Data strategy.
So in December 2019, I audited hundreds of data sources of the city of Leipzig to find out how to make the data more readily available for relevant target groups (Data Scientists and Developers) and how to simplify data access.
I spent my time just before Christmas combining hundreds of CSV files and then evaluating when, where, and to which granularity the data was available.
Together with the city of Leipzig, the results of the data audit were presented and discussed at the world-famous Chaos Communication Congress. The audience was about to challenge us! The results were clear:
- Data scientists approach external data with great skepticism regarding data quality. For good reasons, the data documentation is mostly not very useful, file formats vary, and the link between data sets is virtually non-existent.
- Searching for high-quality data is tedious and takes too long. Open Data platforms primarily launch their data on different subdomains. The data among them is not connected.
- Moreover, integrating data for digital products from various data sources requires considerable data standardization and harmonization effort. Let’s face it. My mother also works with Excel files for her private finances. But CSV, Excel, and PDF formats are not formats that facilitate the work of a Data Scientist or even an Engineer. And that’s the target group an open data platform should go for.
Then 2020 — Covid Year. Give yourself a second to go through the changes and impacts on us, on you, and others.
An interesting side effect: The world became a statistician. Curves were analyzed but never was the intensive care bed occupancy predicted correctly.
Traffic modelers from TU Berlin (Technical University of Berlin) and physicists were consulted, but even they can’t build good models with bad data. When I had a chance to talk with a science task force working on predicting ICUbed occupancy, they told me they were nowhere near modeling.
They were still trying to find and use the correct numbers from three different data sources of ICU bed occupancy. And to be honest, I don’t think they cracked the nut till this point. I have never felt so far away from the 2030 utopias as I did this spring 2020.
How can we talk about mobility transformation when e-scooters remain a fun factor for hipsters but not an efficient mobility solution? How can we dream of self-driving cars? How are we going to use technology to solve our problems?
Throw away all your AI/ML bullshit bingo when you cannot understand the world in clean data. Data Science thus becomes in that quarter a joke for me. But when you lose confidence in others, you find it in yourself.

I didn’t get it. Why is data integration from external data sources so tricky? After all, the ETL process has been around since 1980. There is at least a starting point for standardizing data.
ETL is the process of extracting, transforming, and loading data. The term first became prominent for me when Alteryx, with its visual interface, made the process accessible to analysts and data scientists. Data came in, then it was transformed, and at the end, you had a dataset that you could visualize and report in Tableau.
In an era with a lot of data, the ETL process has shifted back towards the engineer. Due to circumstances, the last two letters were swapped to ELT. Data is now extracted via APIs to fit into a data warehouse (Snowflake), loading is orchestrated (Airflow), data is observed (Great Expectations) and transformed directly in the table of data warehouses (DBT).
This works pretty well if you want to combine your Mailchimp data with your CustomerID. This works pretty well as long as you have a reliable source (e.g., Mailchimp). The data is connected via an API, and it’s managed in a commercial superlative. But there hasn’t been a similar eruption with third-party data integration.
- Today, if you ask a third-party data provider for transactional data, you get 10 CSV files with 1M rows each for your +20K bucks.
- If you look for data on an open data platform, you don’t find sufficient documentation.
- When you scrape data, you trust your own results but probably none of those scraping providers.
- And one last question, have you tried working with OpenStreetMap data?
If you are lucky, you will find the external data you are looking for. But there, the luck usually stops. The data is not of high quality, nor is it easy to integrate, or at least as adequately documented as you would expect from the APIs of SaaS solutions.
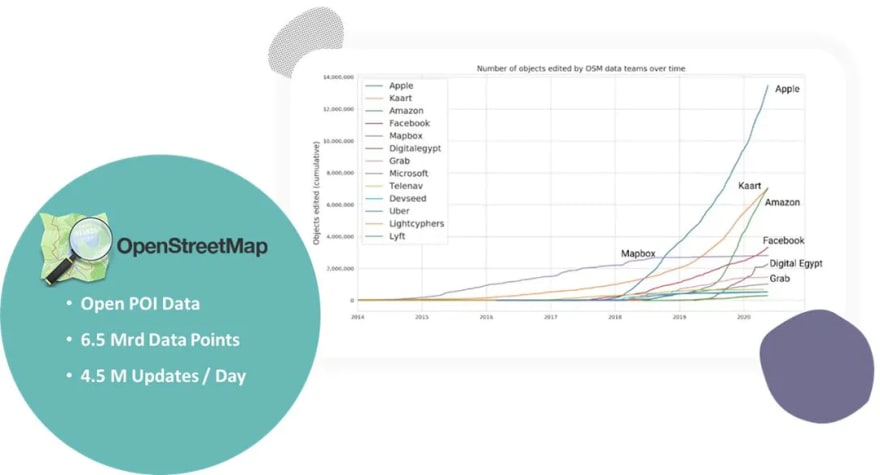
OpenStreetMap is an excellent example of a buried data treasure. One of my favorite slides shows how open-source contribution has been increasing from commercial companies since 2019. Yes, your Apple Maps is based on free, open, external data.
Your Tesla sends new road segments to this data treasure. Microsoft even put all the buildings in the U.S. into GeoJSON and shared it with the world on OpenStreetMap. Most of Mapbox is based on OpenStreetMap (it would be just fair to attribute them well and contribute more back!).
These are billion-dollar companies that put a lot of developer effort into cleaning and preparing OpenStreetMap data to build outstanding products. Just imagine if your young scooter startup would have access to those data points? And what if you don’t have just one open data treasure but 100s of those?
I am currently working with Matti on Kuwala, an open-source platform platform to transfer the ELT logic we know to external, third-party providers. For example, we are also integrating OpenStreetMap data. We pre-process the data, clean it and connect the features to each other.
This data pipeline can then be easily connected to, e.g., the High-Resolution Demographics data from Facebook for Good. The setup is straightforward via a CLI. Then you can launch a Jupyter Notebook with which you can transform the data directly in your familiar environment and create stunning insights.

We are looking for more collaborators to help us also support smaller companies to connect many external data sources, not only Apple and Co.
You have a completely different opinion, a use case, or are you just curious? Visit us on Slack and join the discussion.

Top comments (0)