Hello, how are you today?
In this post I talk about how to modify the multicolumn package and how to create new pages or avoid break pages
multicolumn Package
We talked about this package here and we have a notion on how this package works but, do you know that you can customize a little this package?
These commands must be in the preamble
-
\setlength{\columnsep}{Xpt}to set the spacing between columns toXpt -
\setlength{\columnseprule}{Xpt}to set a column separator ofXpt
Before
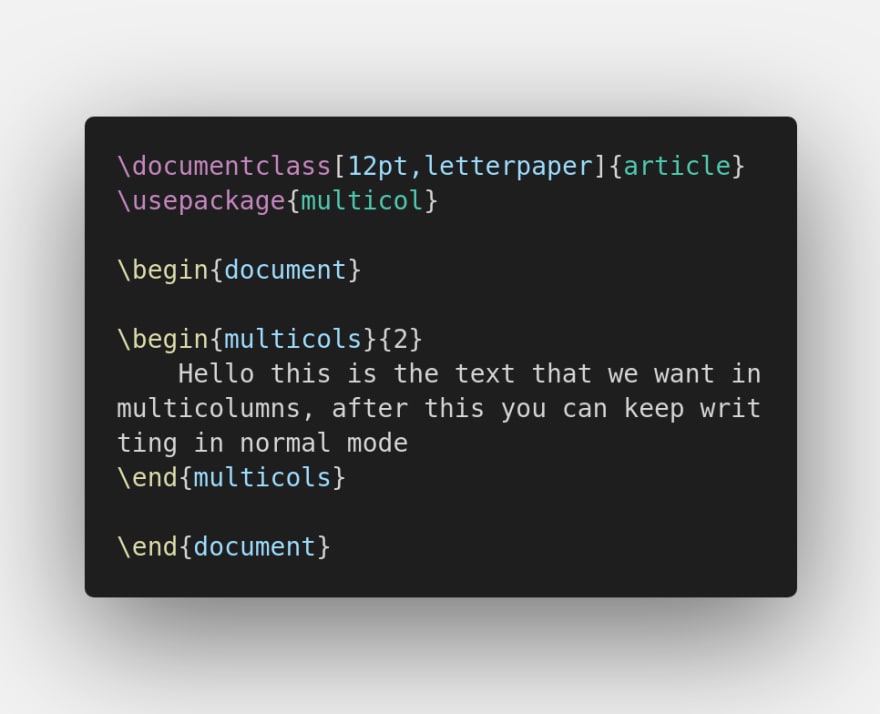
Produces

After
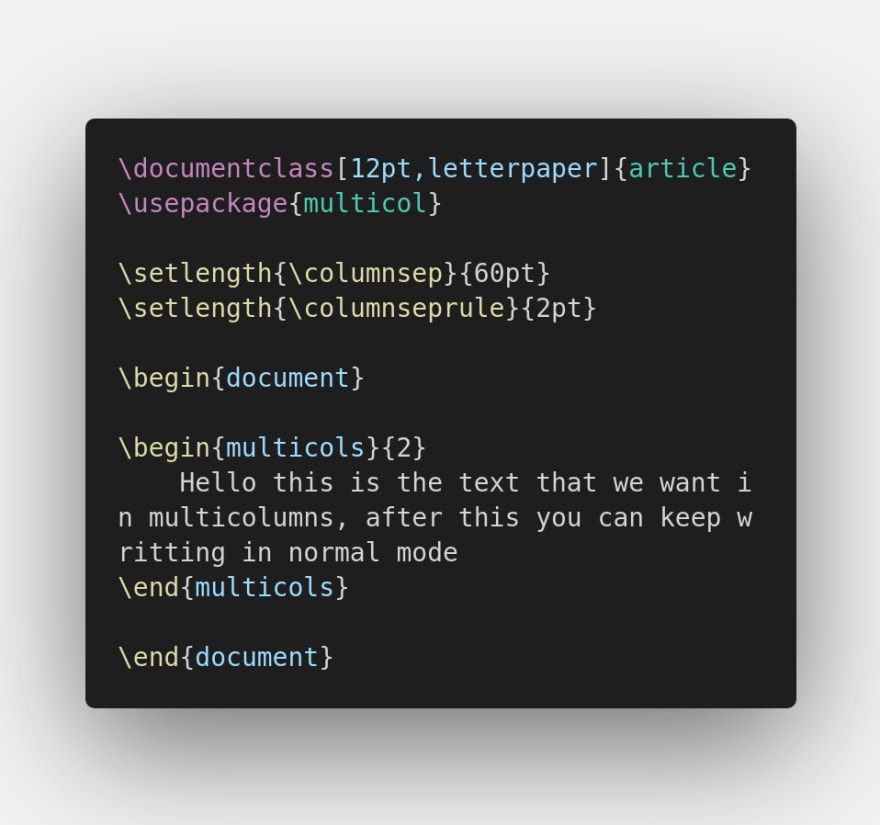
Produces
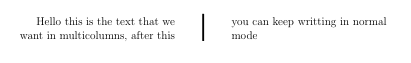
Page Breaking
- We can use
\nopagebreakto avoid breaking the page at that point - We can use
\newpageto print the remaining contents (from the point where we declare the command) of our document on a new page
This is all for today, thanks
Do not forget to follow me on Twitter @latexteada
Greetings :)

Top comments (0)