In this article, we are going to introduce how to archive the audit logs stored in MongoDB to AWS S3, but before we start, let's understand why we need it and the meaning of the need.
Audit logs are records of user actions on the system, including signing in and out, modifying data, enabling a feature, and so on. These records are kept as part of the system security, and recent data is made available for users to view. Users may be interested in the last three months of related operations, but not in records older than that.
Therefore, data that is older than three months is classified as hot data, while data that is older than three months gradually becomes warmer, i.e., rarely accessed, perhaps sometimes still. Data older than six months will be completely cold and will not be accessed except for data analysis and internal system auditing, and users will not care about the existence of such data.
That is to say, if these cold data are still in the original database, it will consume a lot of resources, including hard disk space and indexes. So, we need a way to archive these data to a lower cost storage space, but we still need to make the cold data directly available when they are to be analyzed, instead of doing further migration.
So, today's title tells you that we will archive the data in MongoDB to AWS S3.
There are several advantages to S3, first of all, the data in AWS S3 can be easily analyzed and SQL-compatible queries can be performed through AWS Athena.
In addition, S3 is also a storage option supported by many data analytics platforms, such as Apache Spark.
Furthermore, storage cost of S3 is very low. Moreover, if it is determined that the data in S3 is for preservation purposes only and not for query purposes, it can be easily transferred to much lower cost storage, such as AWS Glacier.
Hot-Cold Separation on MongoDB
Now let's review the requirement again.
In order to reduce the storage cost, we need to move the past audit logs from MongoDB to AWS S3. In addition, we want this to be fully automated, and I don't believe anyone wants to manually migrate data periodically.
So what's the best way to do this? Yes, through streaming.
We have three things to do.
- Pass the events from the new audit log through MongoDB's CDC (and ignore the delete events).
- The stream processor archives the stream events into AWS S3.
- Use MongoDB's TTL index to automatically delete expired data when adding audit logs.
By the way, the MongoDB mentioned here is not a self-hosted database, but a managed platform through Atlas. However, the same approach still applies to self-hosted databases, just with a little more setup and implementation than the managed platform.
After knowing what to do, let's work out a solution.
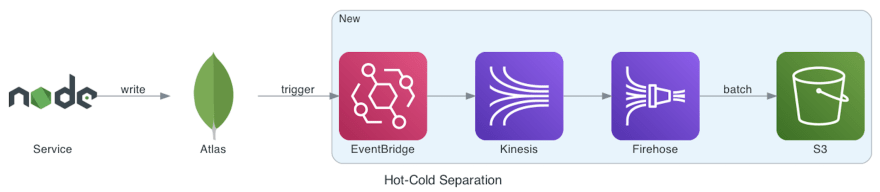
Approach Details
Then, let's explain the whole solution in detail and provide some key points worth discussing.
The front services and databases are original to the architecture, only the back of the streaming chain is new. The entire chain ends with our destination, AWS S3.
The first thing to do is to turn on Atlas' built-in feature, EventBridge Triggers, and since it is a built-in feature, it only requires a few simple settings following the official documentation. There are a few key points to note here, first we only need to send INSERT events, and we need to turn on the option to send full documents so that we can save the complete audit data.
Next, we need to add a new rule to EventBridge's third-party rules: all incoming events are sent to Kinesis, so that the source of the stream is established.
In order to fully automate S3 archiving and save transmission costs as much as possible, we add Kinesis Firehose as the stream aggregator in the middle of Kinesis and S3. Through Firehose, we can aggregate a stream of events into a batch, and write to S3 in a batch process to save S3's transmission cost.
In this way, a fully automatic archiving is accomplished. All audit logs written to MongoDB will be archived into AWS S3 through streams.
Let's discuss a few topics.
Why not just let the service write S3 directly?
There are two reasons.
The first is that we can achieve the purpose without changing the original application by such modification.
The other reason is that audit logs usually require transactional consistency, and it is difficult to ensure that MongoDB and AWS S3 are consistent when the primary database is MongoDB. What if writing MongoDB succeeds, but writing S3 fails?
Why Kinesis and Firehose?
In fact, we can retain one of them, if we want to keep only one I propose to keep Firehose, because we can reduce transmission costs through batch processing.
But Kinesis has a benefit, if we later want to introduce event-driven architecture or streaming processing architecture, Kinesis can provide a very good extensibility.
Does MongoDB's TTL index affect database performance?
Yes, it does, but the impact is limited in this context. This is because we will only keep the data for a certain period of time, for example, three months.
Therefore, the amount of data is limited and the impact on the database is manageable.
Conclusion
Streaming can empower the scalability of the entire system design.
Whether it's through database CDC or events from microservices, it can effectively improve system availability and decouple business logic from data. That's why I've been sharing the streaming architecture for the last few weeks.
This time we experienced the convenience of streaming through the managed platform provided by AWS, a fully automated archiving system. Without the help of streaming, we would have to find a way to activate some scheduled mechanisms, such as a crontab, and get up once a day to check what audit logs needs to be moved, and to do large-scale data migration.
If we use such a batch design, we will immediately encounter a problem, lack of real time. When we do data migration through periodic tasks, there is a data lag, for example, one day. Any data analysis performed on S3 will not get immediate results, but rather a snapshot of some point in time in the past, which is the biggest problem with batching.
But we haven't actually introduced some of the famous streaming framework yet, so maybe we'll have a chance to do that in the future, but rather than actually operating streaming, I feel I'd share some more topics related to architecture and system design.

Top comments (0)