Previously, we introduced the evolution of data infrastructure, where we evolved the original data monolith step by step into an architecture that can support both real time analysis and various data governance.
https://medium.com/better-programming/evolutionary-data-infrastructure-4ddce2ec8a7e
However, in that article, we didn't cover what technical selections were available but only a high-level view of the architecture evolution process.
In this article, we will focus on the stack of real time analysis and list some hot or gradually popular options.
Real Time Infra
Before starting, let's briefly introduce the whole architecture of real time analysis.
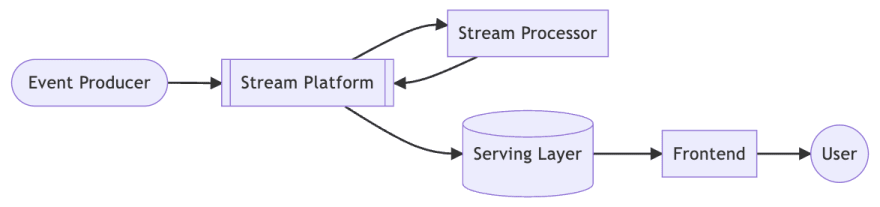
As we mentioned before, the core of the entire real time infrastructure is streaming.
In order to quickly process all events from event producers, streaming plays an important role, and within streaming there are stream platforms and stream processors. Stream platform is the broker of streaming, which is used to store and distribute streams to processors. And the processor will send the stream back to the platform after processing the stream.
Why don't processors deliver the streams directly backwards?
Because the stream may go through more than one processor. To complete a full use case, the stream may go through many processors, each of them focusing on what they are intended to do. This is the same concept as a data pipeline.
When the streaming is processed, it is persisted and available for users as needed. Therefore, the serving layer must be a data store with high throughput and provide a variety of complex queries. For this requirement, traditional RDBMS cannot meet the throughput requirements, so the serving layer is usually not a relational database.
The final frontend is for presenting the data to the end-user, which can be tables, diagrams or even a complete report.
Event Producer
We already know that event producers are responsible for generating various "events", but what kinds of events exactly are there?

There are three types.
- Existing OLTP database
- Event tracker
- Language SDK
Existing OLTP database
Any system will have a database, whether it is a relational database or a NoSQL database, and as long as the application has storage requirements, it will use the database that suits its needs.
To capture data changes from these databases and deliver them to the stream platform, we often use Debezium.
Event tracker
When a user operates a system, whether it is a web frontend or a mobile application, we always want to capture those events for subsequent analysis of user behavior.
We want the trackers to be able to digest the rapidly generated events for us, but we also want them to have some customization, such as enriching the events. Therefore, plug-ins and customization will be a priority when selecting a tracker.
Common options are listed below.
SNOWPLOW provides an open source version, while segment does not.
Language SDK
The last is the events generated by various application backends, which are delivered through the SDK provided by the stream platform. The technical selection here will depend on the stream platform and the programming language in use.
Stream Platform
The concept of stream platform is very simple, it is a broker with high throughput.
The most common option is Kafka, but there are also various open source software and managed services. By the way, the following order does not represent the recommendation order.
Open Source
Managed Service
Stream Processor
A stream processor, as the name implies, is a role that handles streams. It must have scalability, availability, and fault tolerance, and the ability to support various data sources and sinks is also an important consideration.
The Apache Flink, which is often mentioned, is one of these options, and there are many others.
Open Source
- Apache Kafka Streams
- ksqlDB
- Apache Beam: Streaming framework which can be run on several runner such as Apache Flink and GCP Dataflow
- Materialize: Streaming database like ksqlDB and based on Postgres
- MEM GRAPH: Graph database built for real-time streaming and compatible with Neo4j
- bytewax: Python framework
- Faust: Python framework
Managed Service
- GCP Dataflow
- DELTA STREAM
- Quix
Serving Layer
The function of the serving layer is to persist the results of the stream processing and make them easily available to users. Therefore, it must have two important conditions, first, a large throughput, and second, the ability to support more complex query operations.
In general, there are two different approaches, one is to choose a common NoSQL database, such as MongoDB, ElasticSearch or Apache Cassandra. All of these NoSQL databases have good scalability and can support complex queries. In addition, these databases are very mature, so the learning curve is low for both use and operation.
In addition, there are also some NoSQL databases rising up for low latency and big data, e.g., SCYLLA.
On the other hand, there are many newcomers to the SQL family. These new SQL compatible databases have a completely different implementation logic than traditional relational databases, and thus have a high throughput and can even interact directly with stream platforms.
Moreover, these databases have the scalability that traditional RDBMSs do not have, and can still have low query latency in big data scenarios.
Frontend
The most common in the frontend is still to build services using common web frameworks, such as these three most commonly frameworks.
Furthermore, low-code frameworks are becoming popular in recent years. Low-code means developers only need to write a small amount of code to use plenty of pre-defined functions, which can significantly shorten the development time and speed up the release.
In order to make the data more real time, the purpose is to make the value of the data as early as possible, so agile development on the production environment is also a reasonable consideration. Here are two popular low-code frameworks.
Finally, there are various data visualization platforms.
- Apache Superset
- Metabase
- redash
- PowerBI
Conclusion
Although this article lists a lot of targets for technical selection, there are definitely others that I haven't listed, which may be either outdated, less-used options such as Apache Storm or out of my radar from the beginning, like JAVA ecosystem.
Besides, I did not put links to the three major public cloud platforms that are already relatively mature (AWS, GCP, Azure), because those can be found in many resources on the Internet at any time.
Even though these technical stacks are listed by category, some fields actually overlap. For example, although Materialize is classified as a stream processor, it makes sense to treat as a serving layer because it is essentially a streaming database, and the same is true for ksqlDB.
Each project has its own strengths and applications. When making a choice, it is important to consider the existing practices and stacks within the organization, as well as the objectives that you want to accomplish, so that you can find the right answer among the many options.
If there is a project I didn't list and you feel it is worth mentioning, please feel free to leave me a comment and I will find time to survey it.

Top comments (0)