Data behind parking tickets in New York City
Here, we shall analyse the "NYC Parking Tickets" dataset from Kaggle. To dig deeper into the data and uncover various insights, I will introduce such tools as Docker and Metabase, and explain the setup step by step.
Live demo of the resulting dashboard can be found here.
About the dataset
The NYC Department of Finance collects data on every parking ticket issued in NYC (~10M per year!). This data is made publicly available to aid in ticket resolution and to guide policymakers.
This dataset is quite large - it contains about 42.3M rows, and covers the period from Aug 2013 to June 2017. Columns include information about the vehicle ticketed, the ticket issued, location, and time.
Here are some questions that might be interesting to address
- When are tickets most likely to be issued? Any seasonality?
- Where are tickets most commonly issued?
- What are the most common years and types of cars to be ticketed?
- Geographical distribution of the parking violations
- What time of the day are you most likely to get a ticket?
- What police precincts issue the most tickets?
Tools
The raw data is provided via multiple CSV files, the combined size of which exceeds 8GB. This is hard to analyse directly. My approach will involve importing the data into a Postgres database first, so I can run SQL and iterate faster.
Then, I will connect an open-source BI solution called Metabase and will build the resulting queries and the dashboard using Metabase's UI. Metabase is a great BI tool for individuals and small startups and is an ideal solution for prototyping.
In addition, it is open-source and has solid visualisation capabilities, and will be ideal for small teams that might not even have a data analyst.
The above will be packed into a Docker container using Compose and deployed to AWS Cloud for demo purposes. I'd assume that you have some basic understanding of containers, Docker, and Compose, but just in case, here's a link to the "Get Started" section of Docker documentation.
So, here's the summary of the steps we're going to take:
- Download CSV files from Kaggle
- Create Postgres container and import the files into a database
- Create Metabase container and attach it to our Postgres database
- Run analysis using SQL queries and build the resulting dashboard using Metabase
Importing data into Postgres
Container Definition
Our Postgres container definition will look like this
FROM postgres:13.3
COPY pg.conf /etc/postgresql/postgresql.conf
COPY init.sql /docker-entrypoint-initdb.d/
# importing data using 'copy' command
COPY ./data/* /docker-entrypoint-initdb.d/
CMD ["-c", "config_file=/etc/postgresql/postgresql.conf"]
We are using postgres:13.3 image from the official Postgres repository, and we are providing our own Postgres config, which is almost identical to the default one, with only a few adjustments in ./containers/postgres/pg.conf:
statement_timeout = 1200000 # in milliseconds (20 minutes) to allow COPY command to finish
max_wal_size = 3GB
Let's download the data files and put them in ./containers/postgres/data folder under the following names:
./containers/postgres/data/year_2014.csv
./containers/postgres/data/year_2015.csv
./containers/postgres/data/year_2016.csv
./containers/postgres/data/year_2017.csv
Database Initialisation
Now, let's look at the init.sql file in the postgres folder. There's an SQL definition of the table nyc_tickets that will contain all our data. I will create a few indices on the table, to speed up the future queries:
CREATE INDEX "IDX_tickets_vehicle_make" ON "nyc_tickets" ("vehicle_make");
CREATE INDEX "IDX_tickets_issue_date" ON "nyc_tickets" ("issue_date");
⚠️Cleaning and Preparing the Data
As per the dataset description on Kaggle, I am using summons_number as the primary key. However, in the input CSV files, there is a number of collisions and duplicates (i.e. multiple rows with identical summons_number values).
Normally, when inserting a possible duplicate into a table in Postgres, I would use something like
INSERT ... ON CONFLICT DO NOTHING;
or use a rule
CREATE RULE ... AS ON INSERT TO ... WHERE EXISTS ... DO INSTEAD NOTHING;
but, unfortunately, COPY command won't allow that syntax. So instead, we'll apply the following trick:
- First, we will create a temporary table
temp_ticketsthat is identical to the original but doesn't contain any primary keys or indices. - Then, we will
COPYthe data to that temporary table. - And finally, we will copy the data from the temporary table to
nyc_ticketsusingON CONFLICT DO NOTHINGrule.
One thing to note though is that the 2017 CSV file doesn't have 8 additional columns, which are present in the other files (2013-2016). To address that issue, I will specify which exact fields I need to copy, while the rest will be replaced with default values:
COPY "temp_tickets" ("summons_number", "plate_id", "registration_state", "plate_type", "issue_date", "violation_code",
"vehicle_body_type", "vehicle_make", "issuing_agency", "street_code_1", "street_code_2",
"street_code_3", "vehicle_expiration_date", "violation_location", "violation_precinct",
"issuer_precinct", "issuer_code", "issuer_command", "issuer_squad", "violation_time",
"time_first_observed", "violation_county", "violation_in_front_of_or_opposite", "house_number",
"street_name", "intersecting_street", "date_first_observed", "law_section", "sub_division",
"violation_legal_code", "days_parking_in_effect", "from_hours_in_effect", "to_hours_in_effect",
"vehicle_color", "unregistered_vehicle", "vehicle_year", "meter_number", "feet_from_curb",
"violation_post_code", "violation_description", "no_standing_or_stopping_violation",
"hydrant_violation", "double_parking_violation")
FROM '/docker-entrypoint-initdb.d/year_2017.csv' DELIMITER ',' CSV HEADER;
Here is what the final version of init.sql looks like:
-- creating Metabase DB first
CREATE DATABASE "metabase";
GRANT ALL PRIVILEGES ON DATABASE "metabase" TO "analyst";
BEGIN;
GRANT ALL PRIVILEGES ON DATABASE "tickets" TO "analyst";
CREATE TABLE "nyc_tickets"
(
"summons_number" BIGINT NOT NULL,
"plate_id" TEXT,
"registration_state" TEXT,
"plate_type" TEXT,
"issue_date" DATE,
"violation_code" INTEGER,
"vehicle_body_type" TEXT,
"vehicle_make" TEXT,
"issuing_agency" TEXT,
"street_code_1" INTEGER,
"street_code_2" INTEGER,
"street_code_3" INTEGER,
"vehicle_expiration_date" TEXT,
"violation_location" TEXT,
"violation_precinct" INTEGER,
"issuer_precinct" INTEGER,
"issuer_code" INTEGER,
"issuer_command" TEXT,
"issuer_squad" TEXT,
"violation_time" TEXT,
"time_first_observed" TEXT,
"violation_county" TEXT,
"violation_in_front_of_or_opposite" TEXT,
"house_number" TEXT,
"street_name" TEXT,
"intersecting_street" TEXT,
"date_first_observed" TEXT,
"law_section" INTEGER,
"sub_division" TEXT,
"violation_legal_code" TEXT,
"days_parking_in_effect" TEXT,
"from_hours_in_effect" TEXT,
"to_hours_in_effect" TEXT,
"vehicle_color" TEXT,
"unregistered_vehicle" TEXT,
"vehicle_year" INTEGER,
"meter_number" TEXT,
"feet_from_curb" DECIMAL,
"violation_post_code" TEXT,
"violation_description" TEXT,
"no_standing_or_stopping_violation" TEXT,
"hydrant_violation" TEXT,
"double_parking_violation" TEXT,
"latitude" DECIMAL,
"longitude" DECIMAL,
"community_board" TEXT,
"community_council" TEXT,
"census_tract" TEXT,
"bin" TEXT,
"bbl" TEXT,
"nta" TEXT,
CONSTRAINT "PK_tickets" PRIMARY KEY ("summons_number")
);
CREATE INDEX "IDX_tickets_vehicle_make" ON "nyc_tickets" ("vehicle_make");
CREATE INDEX "IDX_tickets_issue_date" ON "nyc_tickets" ("issue_date");
COMMIT;
BEGIN;
CREATE TEMP TABLE "temp_tickets"
(
LIKE "nyc_tickets"
) ON COMMIT DROP;
COPY "temp_tickets" FROM '/docker-entrypoint-initdb.d/year_2014.csv' DELIMITER ',' CSV HEADER;
COPY "temp_tickets" FROM '/docker-entrypoint-initdb.d/year_2015.csv' DELIMITER ',' CSV HEADER;
COPY "temp_tickets" FROM '/docker-entrypoint-initdb.d/year_2016.csv' DELIMITER ',' CSV HEADER;
COPY "temp_tickets" ("summons_number", "plate_id", "registration_state", "plate_type", "issue_date", "violation_code",
"vehicle_body_type", "vehicle_make", "issuing_agency", "street_code_1", "street_code_2",
"street_code_3", "vehicle_expiration_date", "violation_location", "violation_precinct",
"issuer_precinct", "issuer_code", "issuer_command", "issuer_squad", "violation_time",
"time_first_observed", "violation_county", "violation_in_front_of_or_opposite", "house_number",
"street_name", "intersecting_street", "date_first_observed", "law_section", "sub_division",
"violation_legal_code", "days_parking_in_effect", "from_hours_in_effect", "to_hours_in_effect",
"vehicle_color", "unregistered_vehicle", "vehicle_year", "meter_number", "feet_from_curb",
"violation_post_code", "violation_description", "no_standing_or_stopping_violation",
"hydrant_violation", "double_parking_violation")
FROM '/docker-entrypoint-initdb.d/year_2017.csv' DELIMITER ',' CSV HEADER;
INSERT INTO "nyc_tickets"
SELECT *
FROM "temp_tickets"
ON CONFLICT DO NOTHING;
COMMIT;
Metabase container
Metabase dockerfile doesn't contain anything except for the official image and environment files
FROM metabase/metabase:v0.39.4
Docker Compose
Now, we are ready to combine both containers into a docker-compose setup:
version: "3.0"
services:
postgres:
build: ./postgres
ports:
- "5432:5432"
environment:
- POSTGRES_USER=analyst
- POSTGRES_PASSWORD=tickets
- POSTGRES_DB=tickets
volumes:
- pg-data:/var/lib/postgresql/data
metabase:
# Database env variables are set in environment specific env files in ../containers/metabase
build: ./metabase
ports:
- "3000:3000"
volumes:
pg-data:
Let’s now launch the containers:
cd path/to/project
docker-compose -f containers/compose.yml up
Note, that you should probably give enough system resources to Docker, and it can take up to 10 minutes to import all 42M records into the database. Once it’s done, it time now to open Metabase at localhost:3000 and after a quick Metabase setup, start building our dashboard.
Analysis and Visualisation
This is probably the most interesting part of this tutorial, as we will be building SQL queries here to uncover different kinds of insights and visualising them on a dashboard.
Our first question is very simple: what types of cars are the most likely to receive a parking ticket
SELECT COUNT(*) AS "vehicle_count", "vehicle_make"
FROM "nyc_tickets"
GROUP BY "vehicle_make"
ORDER BY "vehicle_count" DESC

Let's group further by the make and year:
SELECT COUNT(*) AS "vehicle_count", concat("vehicle_make", '_', "vehicle_year") as make_year
FROM "nyc_tickets"
GROUP BY "vehicle_make", "vehicle_year"
ORDER BY "vehicle_count" DESC

When are tickets most likely to be issued? Any seasonality?
For this one, we will group our results using a Postgres function [date_trunc](https://www.postgresql.org/docs/13/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC) which truncates the input date to the specified date precision, in our case month
SELECT date_trunc('month', issue_date) AS "ticket_month", COUNT(*) AS "tickets_count"
FROM "nyc_tickets"
WHERE issue_date BETWEEN '2013-07-01 00:00:00+00' AND '2017-07-01 00:00:00+00'
GROUP BY "ticket_month"
ORDER BY "ticket_month" ASC
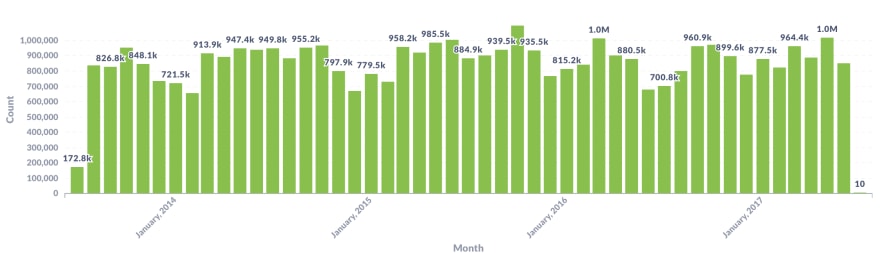
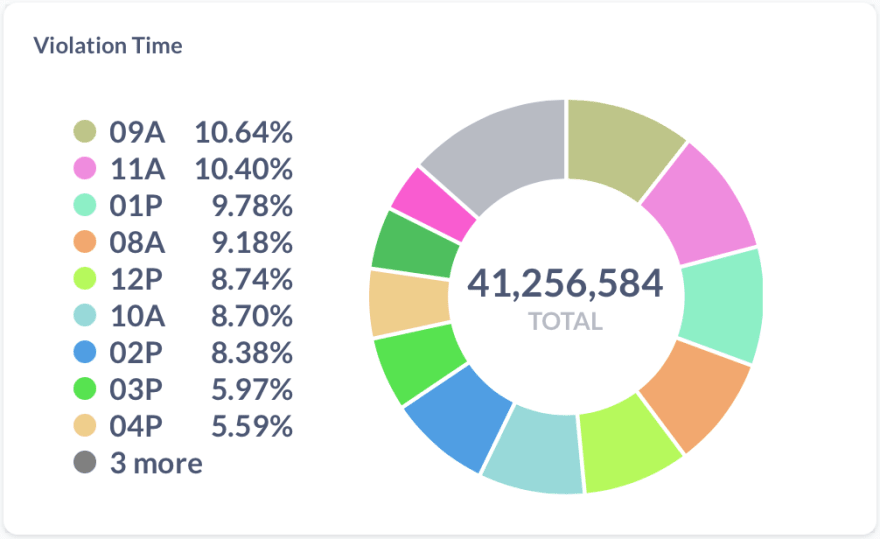
What time of the day are you most likely to get a ticket:
SELECT COUNT(*) AS "vehicle_count", concat(left("violation_time", 2), right("violation_time", 1)) as vtime
FROM "nyc_tickets"
GROUP BY vtime
ORDER BY "vehicle_count" DESC
Distribution by month
SELECT to_char("issue_date", 'month') AS "ticket_month", COUNT(*) AS "tickets_count"
FROM "nyc_tickets"
WHERE issue_date BETWEEN '2013-07-01 00:00:00+00' AND '2017-07-01 00:00:00+00'
GROUP BY "ticket_month"
ORDER BY "ticket_month" DESC

July is the most quit months, while October, March and May are when more tickets are issued.
Tickets issued by Police precinct
SELECT COUNT(*) AS "vehicle_count", "violation_precinct"
FROM "nyc_tickets"
WHERE "violation_precinct" != 0
GROUP BY "violation_precinct"
ORDER BY "vehicle_count" DESC
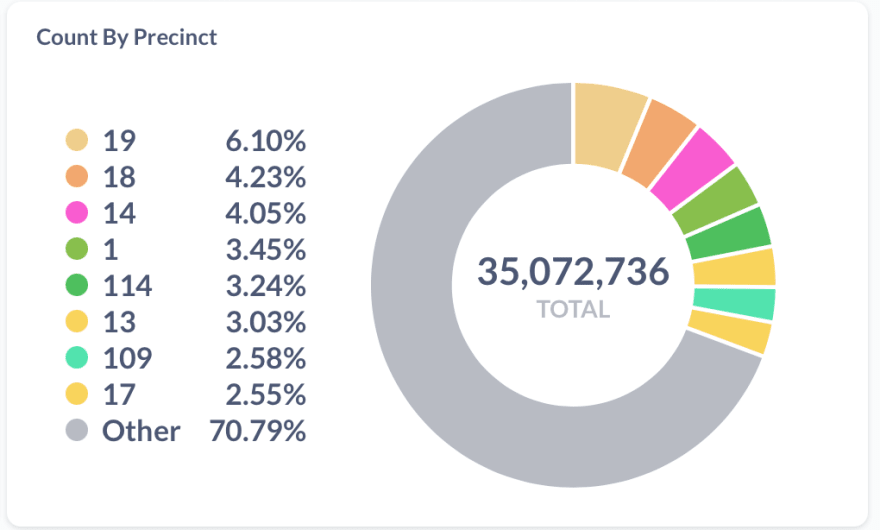
Visualising geographical distribution is a bit hard because the initial dataset doesn’t have geodata in it. Enriching the data by geocoding the address would not be possible either, as geocoding of 42M rows will cost approximately ~$20,000.
Instead, we can use the police precinct id as the geolocation source and get the geodata from here.
Source Code and Demo
You can find the source code for this project in my Github repository, and the live dashboard is hosted in AWS Cloud in here.
Thank you!

Top comments (0)