
I'm getting started with eBPF programming with Aya. The idea behind this series of articles is to get you started too.
In this section, we'll create our first Aya program. We'll also see that there are different types of eBPF programs.
FYI, this is the English version of an article originally published in French.

Example of Hello world Program
I assume you have an operating environment as defined in Part 1. You can also follow this step-by-step lab on creating an Aya program:

Types of eBPF programs
To generate an Aya program, we'll use cargo generate :
cargo generate https://github.com/aya-rs/aya-template
We're going to answer a few questions:
-
Project Name: the name of the project (I puttest-aya) - The second question is more interesting:
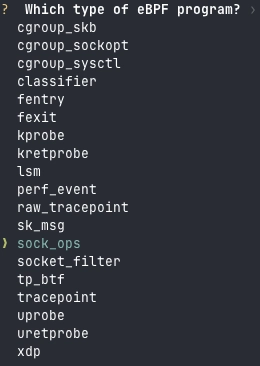
In fact, there are different types of eBPF programs. As we saw in Part 1, I wrote that there are 3 types of eBPF software:
- Network
- Observability and Tracing
- Security
The choices presented to generate the eBPF program are, in fact, parts of the Linux kernel that can be modified or supervised by eBPF. So you need to think carefully about this before jumping headlong into programming.
As I wrote in Part 1, Aya is not yet fully mature compared with other solutions. Here's one reason why: although it may seem as if there are already a lot of program types available, there are still quite a few missing:
 Meta: Add Support For All BPF Program Types
#205
Meta: Add Support For All BPF Program Types
#205
- [x] BPF_PROG_TYPE_SOCKET_FILTER
- [x] BPF_PROG_TYPE_KPROBE
- [x] BPF_PROG_TYPE_SCHED_CLS
- [ ] #206
- [x] BPF_PROG_TYPE_TRACEPOINT
- [x] BPF_PROG_TYPE_XDP
- [x] #207
- [x] BPF_PROG_TYPE_CGROUP_SKB
- [x] #208
- [ ] #209
- [ ] #210
- [ ] #211
- [x] BPF_PROG_TYPE_SOCK_OPS
- [x] BPF_PROG_TYPE_SK_SKB
- [x] #212
- [x] BPF_PROG_TYPE_SK_MSG
- [x] BPF_PROG_TYPE_RAW_TRACEPOINT
- [x] #213
- [ ] #214
- [x] BPF_PROG_TYPE_LIRC_MODE2
- [ ] #215
- [ ] #216
- [x] #217
- [ ] #218
- [ ] #219
- [x] BPF_PROG_TYPE_TRACING
- [ ] #220
- [x] BPF_PROG_TYPE_EXT
- [x] BPF_PROG_TYPE_LSM
- [x] #223
- [ ] #221
What's more, as the Linux kernel continues to evolve, there will certainly be other types of eBPF programs available in the near future.
Time to choose
I tested a few types of eBPF program with Aya before writing this article. To study each type, you can quickly spend days: "I don't understand, it doesn't work" is certainly the phrase I'm uttering the most at the moment. There aren't many similarities between eBPF program types. If you've already played with XDP programs, you'll have other problems with Kprobe programs, for example. For this article, we'll be looking at TracePoint eBPF programs.
TracePoint
Tracepoints are, as the name suggests, places in the Linux code that have been marked (see recommendations). They are mainly used for tracing and debugging the Linux kernel.
All these points are accessible in the /sys/kernel/debug/tracing/available_events file:
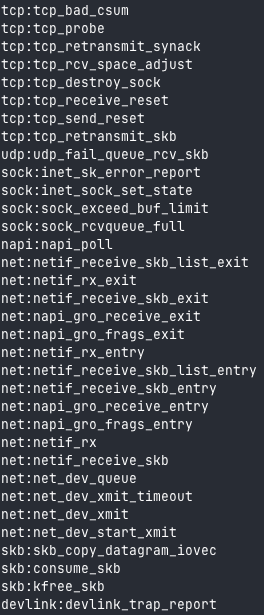
They are in the format:
[Category]:[Name]
Just in time, this is the supplementary question we ask:
![]()
We're going to choose syscalls because everyone knows what a syscall is. Does everyone?
Syscalls
When a program is run, it asks the kernel to perform primary functions called syscalls (system calls).
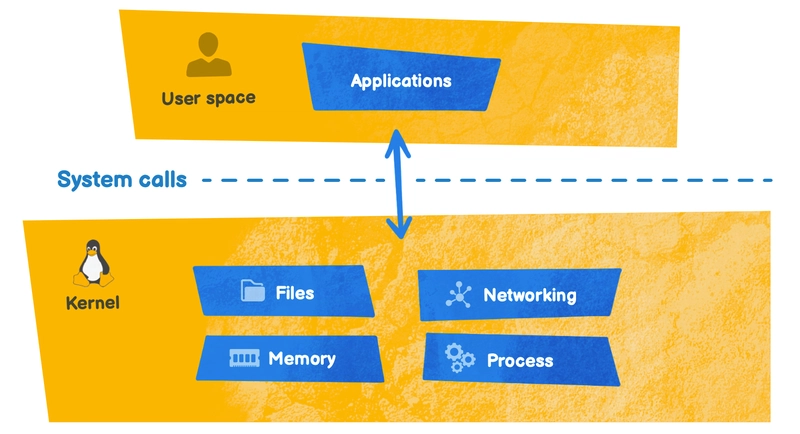
To view the syscalls performed when a command is run, you can use the strace program. For example, you can use:
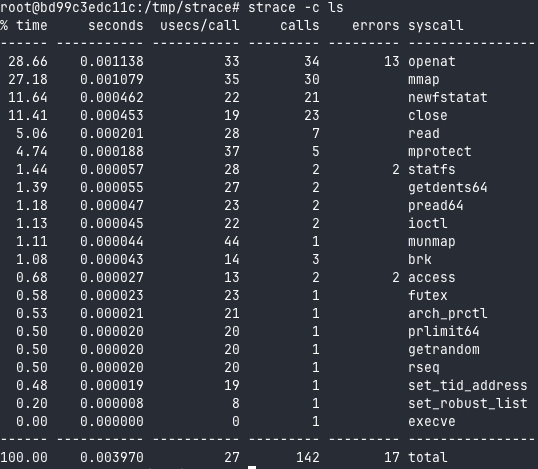
Which syscall to use

To find available tracepoint names, simply issue this command:
grep syscalls: /sys/kernel/debug/tracing/available_events
We can see that they are of the : sys_(enter|exit)_$name_of_syscall
-
enter: starting of syscall -
exit: closing of syscall
We'll arbitrarily choose execve, which is the syscall that executes a program and the one that starts the syscall. So we have sys_enter_execve.

Test
Now we're going to test the generated program directly:
cd test-aya
RUST_LOG=info cargo run
This will take a little while: the time it takes to download and compile all the dependencies. Now you can go and have a cup of coffee!
Once your program has been demarched, run commands on another terminal, e.g.: ls
On the cargo run terminal, you'll see the following message every time you type a command:
[INFO test_aya] tracepoint sys_enter_execve called
So every time the syscall execve is called, this message will be displayed. We've just created the "Hello World" of the Tracepoint eBPF program (syscall:sys_enter_execve). So, for an eBPF program to start up, it needs an event (event-driven) that tells it to run: this is what we call a hook.
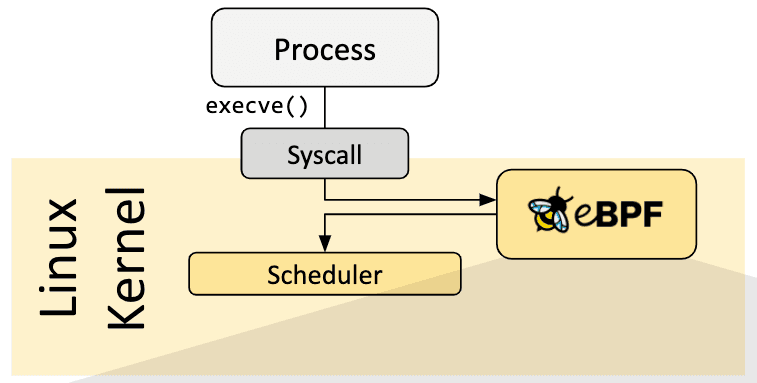
Anatomy of a Hello world Aya program
Let's take a look at what the cargo generate command has generated. As we saw in part 1, there are two parts to an eBPF program: kernel space and user space.
Kernel space
The eBPF program source code can be found here: test-aya-ebpf/src/main.rs. It is compiled first.
Here are its contents:
#![no_std]
#![no_main]
use aya_ebpf::{macros::tracepoint, programs::TracePointContext};
use aya_log_ebpf::info;
#[tracepoint]
pub fn test_aya(ctx: TracePointContext) -> u32 {
match try_test_aya(ctx) {
Ok(ret) => ret,
Err(ret) => ret,
}
}
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
#[cfg(not(test))]
#[panic_handler]
fn panic(_info: &core::panic::PanicInfo) -> ! {
loop {}
}
If you've been following part 1, there's one thing that should already shock you about Rust code: there is no main() function. This is a prerequisite for writing an eBPF program. To overcome this problem, we use the notation: #![no_main]
Another more disturbing prerequisite is that the standard library (std) is forbidden. Only the core library and all libraries that use it are allowed. This means you can't use the println! macro. To tell Rust not to use the standard: #![no_std]
But then how are we going to display anything if println! isn't possible? That's where Aya comes to the rescue: use aya_log_ebpf::info;
This library can be used to display messages if the RUST_LOG environment variable is set. It also includes warn, error, debug and trace (see documentation).
Thanks to this library, you can display :
info!(&ctx, "tracepoint sys_enter_execve called");
We're going to discard this part of the program:
#[cfg(not(test))]
#[panic_handler]
fn panic(_info: &core::panic::PanicInfo) -> ! {
loop {}
}
Don't panic! We'll never change it. It's the code that makes the program work.
All that's left is to explain :
use aya_ebpf::{macros::tracepoint, programs::TracePointContext};
#[tracepoint]
pub fn test_aya(ctx: TracePointContext) -> u32 {
match try_test_aya(ctx) {
Ok(ret) => ret,
Err(ret) => ret,
}
}
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
Ok(0)
}
Two aya_ebpf libraries are used, including one for the tracepoint macro:
#[tracepoint] //here
pub fn test_aya(ctx: TracePointContext) -> u32 {
...
}
In other words, we're going to create an eBPF tracepoint program with the function test_aya().
The pub keyword is to say that the function is public; it's not really “important”, it's just to make the Aya framework work. If we remove these unwanted elements:
use aya_ebpf::programs::TracePointContext;
fn test_aya(ctx: TracePointContext) -> u32 {
match try_test_aya(ctx) {
Ok(ret) => ret,
Err(ret) => ret,
}
}
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
Ok(0)
}
We're back to a few things we've already seen in part 1.
Things to remember:
- the
test_aya()function is attached to the tracepoint program. - All the work will be done in the
try_test_aya()function. -
ctx: this is the context variable that will enable us to go beyond a hello world program.
As you can see, there's no mention of syscalls for the moment. I want this Tracepoint program to be attached to an execve syscall. Good timing: let's take a look at the user-space code now.
User space
In this article, we won't be modifying the user space code. It can be found in this file: test-aya/src/main.rs.
I'll simplify its code for a better understanding:
use aya::programs::TracePoint;
use log::{debug, warn};
use tokio::signal;
#[tokio::main]
async fn main() -> anyhow::Result<()> {
let mut ebpf = aya::Ebpf::load(aya::include_bytes_aligned!(concat!(
env!("OUT_DIR"),
"/test-aya"
)))?; //1
if let Err(e) = aya_log::EbpfLogger::init(&mut ebpf) {
warn!("failed to initialize eBPF logger: {}", e);
} //2
let program: &mut TracePoint = ebpf.program_mut("test_aya").unwrap().try_into()?; //3
program.load()?; //4
program.attach("syscalls", "sys_enter_execve")?; //5
let ctrl_c = signal::ctrl_c();
println!("Waiting for Ctrl-C...");
ctrl_c.await?;
println!("Exiting...");
Ok(())
}
This Rust code is a little more traditional: you can use the standard library, as evidenced by the println! and the main() function.
I've commented out the important parts of the code with numbers:
- 1: We'll load the previously compiled eBPF code into an ebpf variable
- 2: We'll start displaying the eBPF logs (for example, the
info!from the previous code) in the user space - 3: Convert the main function of the eBPF code into Tracepoint code
- 4: Load the main program function (the
test_aya()function) - 5: Attach it to the tracepoint syscalls:sys_enter_execve
The rest of the code is for program operation, such as not quitting the program before the logs start.
If you're new to Rust, there are certainly some parts of the code that may seem obscure to you. That's a good thing! The next section is dedicated to Rust.
Rust, it's getting complicated!
Before modifying the code, I think it's worth reviewing the Rust language a little more theoretically. I didn't want to scare you too much in part 1 😃

Types
In Part 1, we looked at variable declaration and modification. But we didn't talk much about types. This is important because, for example, all functions must be filled in with the various types.
There are two types:
- scalar types
- compound types
Scalar types
Let's take a look at scalar types: for integers, for example, we can define very precisely how many bits they are encoded in:

It's often optional to declare the variable with its type, but to remove any ambiguity, we do it this way:
let my_variable :i64 = 2055;
With println!, you can display the contents in a different way, for example, you can convert to hexadecimal:
println!("{:x}", ma_variable);
That's the magic of the macro! There's also this kind of possibility with info! in Aya. For example, you can convert a number into an IP or MAC address: very useful for eBPF networking.
Let's finish with scalar types and talk about casting, i.e. modifying the type. Let's take a look at this example:
fn addition(x: u32, y: u32) -> u32 {
x + y
}
fn main() {
let a: u16 = 10;
let b: u16 = 20;
let res = addition(a, b); //❌ ERROR: u16 != u32
println!("{}", res);
}
This program won't work because the arguments require u32 and not u16. It is of course possible to change the function directly, but you don't always have access to the function as you would in a library. How do I change the code? Use the keyword as:
fn addition(x: u32, y: u32) -> u32 {
x + y
}
fn main() {
let a: u16 = 10;
let b: u16 = 20;
let res = addition(a as u32, b as u32); // come as you are
println!("{}", res);
}
Compound types
Now let's talk about compound types, for example how to represent integer arrays:
let _my_array: [i8; 2] = [0, 2]; // An array of 2 entries of type i8
An array has a fixed number of entries: you can't add a number after the fact. There are also dynamic arrays in Rust, such as Vec. However, eBPF programs (on the kernel side) cannot use them: they require arrays with a number of entries already defined before compilation. The strategy is therefore to evaluate the maximum number an array can have by filling it with 0.
let _zeros_array = [0u8; 256]; // An array of 256 entries of 0 of type u8
And what about strings?
The default string in Rust is an array (a slice, to be precise - I'll get a slap on the wrist if I don't) with a fixed number of u8 entries (and therefore UTF-8 encoding). It is not, as in other programming languages, an array of characters (char). The notation is &str.
Thus, it's not possible to concatenate in this way:
let _toto = "aaaa";
let _tutu = "bbbb";
let _toto = _toto + _tutu;
However, if we convert _toto to String, it works:
let _toto = "aaaa"; //_toto is of type &str
let _tutu = "bbbb"; //_tutu is of type &str
let _toto = _toto.to_owned() + _tutu; //_toto is of type String
String is the equivalent of Vec. This makes it possible to have arrays of u8 dynamically.
Structures
Structures are a mixture of different types. The keyword is struct. For example, to create a simple role-playing game :
struct Person {
name: String,
age: u32,
}
fn main() {
let person = Person {
name: String::from("Alice"),
age: 30,
};
println!("Name: {}, Age: {}", person.name, person.age);
}
If you find initialization a little complicated, you can create methods with the impl keyword:
struct Person {
name: String,
age: u32,
}
impl Person {
fn new(name: &str, age: u32) -> Person {
Person { name: String::from(name), age }
}
fn old(&mut self) { //👴🏻
self.age += 1;
}
fn change_name(&mut self, name: &str) {
self.name = String::from(name);
}
}
fn main() {
let mut person = Person::new("Julia", 40);
println!("Before: Name: {}, Age: {}", person.name, person.age);
person.age();
person.changer_name("Julian");
println!("After: Name: {}, Age: {}", person.name, person.age);
}
As you can see, thanks to the structures, the programming language reads almost naturally. In a way, it's like an object language.
To give you a more realistic example, take a look at the code generated in the user area above:
let program: &mut TracePoint = ebpf.program_mut("test_aya").unwrap().try_into()?;
program.load()?;
program.attach("sys_enter_execve", "syscalls")?;
TracePoint is actually a structure. Let's read the documentation:

What can be deduced from the doc, the approximate code:
struct TracePoint {
[I don't know]
}
impl TracePoint {
pub fn load(&mut self) -> Result<(), ProgramError> {
[see the source code]
}
pub fn attach(&mut self, category: &str, name: &str) -> Result<...,...>{
[see the source code]
}
}
Generic Functions
Previously, we had to cast to have the same type:
fn addition(x: u32, y: u32) -> u32 {
x + y
}
fn main() {
let a: u16 = 10;
let b: u16 = 20;
let res = addition(a as u32, b as u32); //Here
println!("{}", res);
}
Using generic function, we don't need to cast:
fn addition<T>(x: T, y: T) -> T
where
T: std::ops::Add<Output = T>,
{
x + y
}
fn main() {
let a: u16 = 10;
let b: u16 = 20;
let res = addition(a, b);
println!("{}", res);
}
This way, you won't have to think about which type you need to use the addition function.
The function is inevitably a little more complicated to write. We won't be writing any in this section. But for use via a library, it's pure bliss (I'm exaggerating a little bit).
Soon, we'll see a generic function:

Result
We've been seeing Result<...,...> a lot since part 1. Let's talk about it in a little more detail.
Result is an enumeration. We haven't seen what it is, but to put it simply: Result lets you create functions that can result in a success or an error. This is elegant when used with match or ? as we saw in Part 1.

As with generic functions, T and E can be of any type (within certain constraints).
As a reminder, here's a simple example of a function that returns Result :
fn get_some_value(value :u32) -> Result<u32, u32> {
match value > 10 {
true => Ok(value),
false => Err(0),
}
}
const NUM :u32 = 55;
fn main() -> Result<(), u32> {
let v = get_some_value(NUM)?;
println!("{}", v);
Ok(())
}
In this example, only integers greater than 10 are displayed.
Option
Option is another enumeration quite similar to Result: the function returns either Some(T) or None. It's an optional value.

To retrieve the T value, there's no equivalent to the question mark with Result. However, a trick is to convert the Option type with ok_or(...) to Result and then add the question mark.
Here's an equivalent of the previous code with a function that returns Option<T> :
fn get_some_value(value :u32) -> Option<u32> {
match value > 10 {
true => Some(value),
false => None,
}
}
const NUM :u32 = 55;
fn main() -> Result<(), ()> {
let v = get_some_value(NUM).ok_or(())?;
println!("{}", v);
Ok(())
}
Another solution to retrieve this value is to use unwrap() method:
fn get_some_value(value :u32) -> Option<u32> {
match value > 10 {
true => Some(value),
false => None,
}
}
const NUM :u32 = 55;
fn main() -> Result<(), ()> {
let v = get_some_value(NUM).unwrap(); //No need of "?" now
println!("{}", v);
Ok(())
}
But there's a big BUT: it's not possible to use unwrap() in kernel space code. Why not? To cut a long story short: unwrap() can panic, and an eBPF program can't afford that:

The piece of code that we discarded in the kernel space above :
#[cfg(not(test))]
#[panic_handler]
fn panic(_info: &core::panic::PanicInfo) -> ! {
loop {}
}
It can be used to manage the case of unwrap(), for example.
Memory Management
When a variable is created in a program, the compiler must take care of finding where in RAM to add the variable, as well as deleting it to avoid so-called memory leaks. For fixed variables such as integers or non-dynamic arrays, variables are stored in stacks, so there are no problems with releasing them. Thus, because of the restrictions in kernel space programs, there are no clean-up problems in eBPF. Dynamic variables, on the other hand, are stored in heaps, and that's where the problems come in.
In C, we let the developer do this with malloc and free. If he forgets to free memory, it often goes unnoticed, but is a potential source of bugs.
In other languages (such as Python or Go), the garbage collector takes care of cleaning up automatically, without developer intervention. However, this is done at the expense of performance.
In Rust, we use the notion of ownership to solve the problem.
Let's take an example:
fn main() {
let s1 = String::from("Hello");
let s2 = s1;
println!("{}", s1);
}
-
s1has theStringtype, which is dynamic
This program cannot compile. Why?
-
s1will reserve memory space in the heap:let s1 = String::from("Hello"); -
s2will retrieve the ownership of this memory space:let s2 = s1;Thuss1has lost ownership of this memory space:

This means that no two (or more) variables can have the same memory space. Rust will automatically release a variable once it has left the scope.
Borrowing
The most elegant solution is to use a reference (Keyword: &). These references are also known as safe pointers:
fn main() {
let s1 = String::from("Hello");
let s2 = &s1;
println!("{}", s1);
println!("{}", s2);
}
This will display Hello twice.
We say that s2 borrows s1's value, but s1 retains its property.
Let's take one last example to show you that this isn't always obvious:
fn print_length(s: String) {
println!("Length: {}", s.len());
}
fn main() {
let s = String::from("Hello");
print_length(s);
println!("{}", s);
}
This code doesn't compile either. Why?
s will reserve a memory space in the heap:
let s = String::from("Hello");
The print_length() function will take the property of this memory space:
print_length(s);
At the end of this processing, Rust will delete this memory space:
fn print_length(s: String) {
println!("Length: {}", s.len());
}
So the display of s crashes.
To solve this problem simply use this borrowing system:
fn print_length(s: &String) { // We add an "&"
println!("Longueur: {}", s.len());
}
fn main() {
let s = String::from("Hello");
print_length(&s); // We don't forget to also add it
println!("{}", s);
}
When you're not used to it, you often make the mistake. But the error messages are self-explanatory and therefore easy to correct.
Unsafe
The unsafe keyword is very useful when working at low level. It's the sysadmin equivalent of sudo. By default, Rust has protections, notably for reading memory. The unsafe keyword lets you tell Rust: "Don't worry, I know what I'm doing! If you set unsafe anywhere, Rust will remind you with a warning, or if you don't set unsafe anywhere, Rust will tell you to set it if that's what you really want to do.

Raw pointers
Let's finish this busy section with raw pointers. The notion is similar to the C pointer. It lets you know the address of the variable. There are two types of raw pointers:
- If data of type T cannot change :
*const T - If data of type T can change:
*mut T
To convert to a raw pointer, use the as_ptr() function:

Let's give an example:
fn main() {
let a = "toto";
let memory_location = a.as_ptr() as usize;
println!("toto is on the memory address: {:x}", memory_location);
let a = 12;
let memory_location = &a as *const i32 as usize;
println!("12 is on the memory address {:x}", memory_location);
}
That's all for this Rust part. I hope it wasn't too complicated and dense to understand. If it was, don't worry: let us guide you through the rest, and we'll review each point for a concrete case.
Improving the program
What are we going to do?
We've already created a program that every time a binary is executed, it displays a few things in the logs. It would be nice to be able to see which binary is being executed. So we're going to create a little program that will log all the binaries that are executed on the machine. It might be handy to see this for security reasons.
Reminder
To do this, you'll need to modify the aya code in kernel space test-aya-ebpf/src/main.rs
This is the main part you'll need to modify:
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
This is based on the ctx variable, which is a TracePointContext structure.
To do this, we'll take a look at the documentation:

The library is located at the program level:
use aya_ebpf::programs::TracePointContext;
This shows all the documentation for each type of eBPF program:

This shows the functions that can be used with TracePointContext:

We're not interested in the first function, which is used to create a TracePointContext. It's probably used in the macro. That leaves us with the second function: read_at(). This function reads the tracepoint at a certain offset. How do we find this offset?
You need to look in the syscall tracepoint file. To find it, go to: /sys/kernel/debug/tracing/events/[category]/[name]. And the file name is format.
So the file is here: /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/format.

We'll try to retrieve the filename with offset 16:
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
let filename = ctx.read_at::<u64>(16);
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
I wasn't sure what to put in place of T, so I arbitrarily set the type to u64.
If you try to compile :

It works better now with unsafe:
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
let filename = unsafe {ctx.read_at::<u64>(16)};
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
Now let's try using this variable. The result of the read_at function is Result(u64, i64). The aim is to retrieve u64. Just use the question mark (?).
So we'll get :
fn try_test_aya(ctx: TracePointContext) -> Result<u32, u32> {
let filename = unsafe {ctx.read_at::<u64>(16)?};
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
Nevertheless, compilation won't work because if it makes an error, the read_at function returns an i64 and my final function returns a u32.

We have to change:
fn try_test_aya(ctx: TracePointContext) -> Result<u32, i64> { //u32 -> i64
let filename = unsafe {ctx.read_at::<u64>(16)?};
info!(&ctx, "tracepoint sys_enter_execve called");
Ok(0)
}
Similarly, the Tracepoint function must always return a u32. We must therefore cast the type to u32 :
pub fn test_aya(ctx: TracePointContext) -> u32 {
match try_test_aya(ctx) {
Ok(ret) => ret,
Err(ret) => ret as u32, //cast
}
}
With these type-matching modifications, it should compile. Let's have a look at the contents of filename. Here's the whole file now if you're lost :
#![no_std]
#![no_main]
use aya_ebpf::{macros::tracepoint, programs::TracePointContext};
use aya_log_ebpf::info;
#[tracepoint]
pub fn test_aya(ctx: TracePointContext) -> u32 {
match try_test_aya(ctx) {
Ok(ret) => ret,
Err(ret) => ret as u32,
}
}
fn try_test_aya(ctx: TracePointContext) -> Result<u32, i64> {
let filename = unsafe {ctx.read_at::<u64>(16)?};
info!(&ctx, "tracepoint sys_enter_execve called {}", filename); // the modif
Ok(0)
}
#[cfg(not(test))]
#[panic_handler]
fn panic(_info: &core::panic::PanicInfo) -> ! {
loop {}
}
If we run a cargo run again, here's what we see:
[INFO test_aya] tracepoint sys_enter_execve called 94803283704040
[INFO test_aya] tracepoint sys_enter_execve called 94803283704112
[INFO test_aya] tracepoint sys_enter_execve called 94173001563176
[INFO test_aya] tracepoint sys_enter_execve called 824637710416
[INFO test_aya] tracepoint sys_enter_execve called 94865232898256
[INFO test_aya] tracepoint sys_enter_execve called 824638316624
[INFO test_aya] tracepoint sys_enter_execve called 94865232898256
These numbers are not file names. This was to be expected, given that the type is u64. What I notice is that when I run a command: I'm always number 94865232898256 if it's the server it's the other numbers, if I change user I get a different number.
Well... that's not much help. Shall we give up? The documentation isn't complete, it doesn't say what it's really for.
I look at the source code of the read_at function:
pub unsafe fn read_at<T>(&self, offset: usize) -> Result<T, i64> {
bpf_probe_read(self.ctx.add(offset) as *const T)
}
And what does bpf_probe_read do?

In this way, an address in memory is accessed. Now we need to think about how to successfully read this address.
I'll take a look at the helper functions:

I have the feeling that this is this function that i need:

Let's add these lines and see what happens:
let mut buf = [0u8; 16]; //let's create a array of u8
let _my_str_bytes = unsafe { aya_ebpf::helpers::bpf_probe_read_user_str_bytes(filename, &mut buf)? };

So all we have to do is change the u64 type to *const u8 (a raw pointer) and we'll change the variable names to be consistent with the documentation:
let filename_src_addr = unsafe {ctx.read_at::<*const u8>(16)?};
let mut buf = [0u8; 16];
let _filename_bytes :&[u8] = unsafe { aya_ebpf::helpers::bpf_probe_read_user_str_bytes(filename_src_addr, &mut buf)? };
info!(&ctx, "tracepoint sys_enter_execve called {}", filename_src_addr as u64); //We also cast
The compilation works! Now we have a byte-coded file name. Now we need to figure out how to convert it to &str.

That's what I want, but as I said earlier, eBPF doesn't accept the standard library (std).
Miracle! It also exists in the core library :

So we add:
let _filename = core::str::from_utf8(_filename_bytes);
Let's see if it compiles:

So it compiled fine. But the eBPF verifier is not happy at all. The verifier is a kernel protection system that prevents an eBPF program from being launched if it considers it dangerous for the kernel. What we see in the screenshot is JIT code (Just In Time code).

The explanation is at the end:

In the documentation, there's another function that might suit us. Perhaps from_utf8 makes too many checks that are not compatible with the eBPF verifier?

Let's add _unchecked and unsafe:
let _filename = unsafe { core::str::from_utf8_unchecked(_filename_bytes) };
It compiles!
By modifying the log line:
info!(&ctx, "tracepoint sys_enter_execve called Binary: {}", _filename);
I connect with ssh on the server where the program is installed, I see all the binaries that are executed :

The code works, and if you clean it up afterwards, you'll get a code similar to this one

You can find the program in GitHub.
That's all for this part. I hope you enjoyed it. It was much more technical than the first part. In the next part, we'll be looking at a few things we've already mentioned: the eBPF map. This will, for example, solve the problem we have with the program: file names are truncated. With an eBPF map, we can solve the problem!


Top comments (1)
Thank you for the great tutorial about Rust and Aya!
Found trivial typos in the code snippet about the struct implemetation:
person.
age()-> old()person.
changer_name()-> change_name()Happy coding!