
Written by David Omotayo✏️
Schema libraries have been a boon to validation in web development for some time, but since the widespread adoption of TypeScript, these libraries have evolved to handle more complex operations such as type-safety, data validation, and transformation. Schema libraries prevent developers from accidentally using the wrong type of data, which can lead to bugs and errors, help ensure that data is correct and meets the requirements of the application, and convert data from one format to another.
In this article, we’ll introduce Valibot, one of the newest validation libraries on the block. We’ll also investigate how it works and we'll see how it compares with existing validation libraries such as Zod and Yup.
Jump ahead:
- Prerequisites
- What is Valibot?
- Comparing Valibot’s design approach to Zod and Yup
- Comparing Valibot’s bundle size to Zod and Yup
- Installing Valibot
- Using Valibot for validation
- Transformation with pipelines
- Understanding validation errors
- Use cases
Prerequisites
To follow this tutorial, you should have the following:
- A working knowledge of TypeScript
- Node.js installed on your machine
- An IDE, preferably VS Code
What is Valibot?
Valibot is an open source, TypeScript-first schema library that validates unknown data. It is comparable to other schema validation libraries such as Zod and Yup, but is 98% smaller in size. Valibot is modular and type-safe and enables bundle size minimization through code splitting, tree shaking, and compression.
Valibot has a minimal, readable, and well-designed API that is fully tested with 100 percent code coverage. Here’s a basic example of how to validate a string using Valibot:
import { parse, string } from "valibot";
const schema = string();
const result = parse(schema,"David"); // David
Valibot's core function is to create and validate schemas. In this respect, it is the same as other schema validation libraries; it differs in terms of how it defines and executes schemas.
Valibot’s schemas could be a string of any data type or a complex nested object. This is comparable to how types are defined in Typescript, but unlike Typescript, they are executed at runtime to ensure type safety for unknown data.
Valibot also employs TypeScript inference to automatically generate TypeScript types that correspond to the defined schema. In other words, Valibot validates your schema at runtime and also provides TypeScript types that reflect the expected structure of the validated data.
For example, we can define a Valibot schema for a user object, like so:
Import {object, Output} from "valibot";
const user = object({
id: string,
name: string,
email: string
})
type userData = Output<typeof user>;
In this case, the TypeScript type userData is automatically inferred from the defined Valibot schema using the Output<typeof user> type. This means that the userData type will have properties id, name, and email, with the correct type inferred from the schema. This feature helps maintain consistency between runtime data validation and type safety in your code.
Valibot also offers a number of utility types that operate similarly to TypeScript's utility types, which can be used to manipulate and transform existing types. Here are some of those functions:
-
partial: Constructs a type with all properties ofTypeset to optional -
pick: Constructs a type by picking the set of propertiesKeys(string literal or union of string literals) fromType -
omit: Constructs a type by picking all properties fromTypeand then removingKeys(string literal or union of string literals) -
readOnly: Constructs a type with all properties ofType set to read-only, meaning the properties of the constructed type cannot be reassigned
Refer to the documentation to learn more about these utility functions.
Comparing Valibot’s design approach to Zod and Yup
Valibot employs a modular design, similar to Lodash's one-function-per-file design approach. It relies on small and independent functions, each with just a single task.
This design approach has several advantages, such as extended functionality with external code and more. However, its biggest advantage is that a bundler can use the import statements to remove dead code (i.e., code that is not needed). With this process, also referred to as tree shaking, only the code that is actually used ends up in the production build.
To provide a clearer view of this concept, here’s a comparison of a single import from Valibot, Zod, and Yup:  It should be noted that Zod and Yup aren’t modular by design; their methods are properties of a global object like the
It should be noted that Zod and Yup aren’t modular by design; their methods are properties of a global object like the z object in Zod, or a number and string subrule in Yup. However, it is possible to mimic tree-shaking in Zod and Yup with some functions like string or number:  While it may appear that tree shaking has been achieved, the function actually imports its sub-rules behind the scenes. This implies that, even though we are only importing the
While it may appear that tree shaking has been achieved, the function actually imports its sub-rules behind the scenes. This implies that, even though we are only importing the string method, we can still access every potential sub-method of string, such as email, min, and max length, whether or not they are required.
string().email().min();
number().required().positive().integer()
Valibot eliminates the need to worry about such quirks, as each function is truly independent and is imported separately:  It is also worth noting that tree-shaking is not always available during development, as it requires a build step. However, Valibot's modular design allows you to import only what you need using multiple direct imports.
It is also worth noting that tree-shaking is not always available during development, as it requires a build step. However, Valibot's modular design allows you to import only what you need using multiple direct imports.
Comparing Valibot’s bundle size to Zod and Yup
Given Valibot's design, it shouldn’t come as a surprise that its bundle size is significantly smaller than the competition. However, it is important to note that schema validation libraries are not always large in size.
For example, Zod's bundle size is just 57kB minified and 13.2kB when minified and compressed with gzip:  While Yup’s bundle size is only 40kB minified and 12.2kB when minified and compressed with gzip:
While Yup’s bundle size is only 40kB minified and 12.2kB when minified and compressed with gzip: 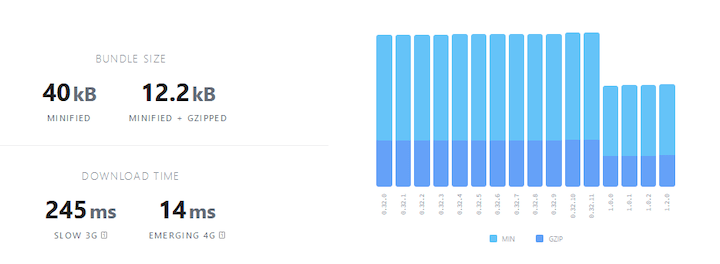 So it should go without saying that Zod and Yup are highly unlikely to cause overhead in your application. However, if you are a stickler for bundle sizes and would not mind a further reduction in size, Valibot is the better choice, as it is half the size of Zod and Yup:
So it should go without saying that Zod and Yup are highly unlikely to cause overhead in your application. However, if you are a stickler for bundle sizes and would not mind a further reduction in size, Valibot is the better choice, as it is half the size of Zod and Yup:  5.3kB is a very small bundle size, but it’s still larger than the <1kB size noted in several places throughout the Valibot docs:
5.3kB is a very small bundle size, but it’s still larger than the <1kB size noted in several places throughout the Valibot docs:  So where is this difference in bundle size coming from? Well, because Valibot is tree-shakable, only the code that is needed is included in the final bundle. This can result in a 98% reduction in bundle size compared to Zod and Yup.
So where is this difference in bundle size coming from? Well, because Valibot is tree-shakable, only the code that is needed is included in the final bundle. This can result in a 98% reduction in bundle size compared to Zod and Yup.
Going back to our earlier example, Valibot's bundle size will be exactly 513 bytes, as the string function will be the only Valibot code added to your codebase during the build step: 
Installing Valibot
Integrating Valibot into your project is as straightforward as running one of the following commands in your terminal:
npm install valibot
yarn add valibot
pnpm add valibot
The installation status can be verified by inspecting the package.json file in the project directory: 
Using Valibot for validation
Valibot offers various small functions that can be used to perform a variety of validation-related operations, from validating primitive values, such as strings, to more complex data sets, such as objects, and then parsing them and returning the appropriate response, which could be an error or the validated data.
Here’s an example of validating primitives with Valibot:
import { string, parse } from 'valibot';
const schema = string();
const result = parse(schema,('Hello World!'));
Hare’s an example of using Valibot to validate objects:
import { string, number, parse, object } from 'valibot';
const schema = object({
name: string(),
age: number(),
});
const result = parse(schema, {
name: 'John Doe',
age: 30,
});
The parse method in the examples above is used to validate unknown data and make it type-safe using an existing schema. It takes two arguments: a defined schema and an unknown data:
parse(schema, unknown data);
Transformation with pipelines
We can use Valibot’s pipelines to perform more detailed and extensive validation and transformation of our data. For example, here we use pipelines to ensure that our string is an email and ends with a certain domain:
const EmailSchema = string([toTrimmed(), email(), endsWith('@example.com')]);
Pipelines are optional and are always passed as an array to a schema function as the last argument if other arguments are passed to the function at the same time. You can link multiple transformations together to create complex pipelines, as demonstrated here:
const schema = string([
((input) => input.toUpperCase()),
((input) => input.replace(/ /g, '_'))
])
const result = parse(schema, "hello world"); // HELLO_WORLD
Understanding validation errors
Valibot's functions by default return a valid input and throw an error when an unsupported type is parsed using the valiError method. For example, if we pass a number to a property where a string is expected, we’ll get the following error from Valibot:  The
The ValiError method can be used to throw personalized errors based on certain conditions. For instance, a validation function that controls the length of a string might look like this:
const StringSchema = string([
(input, info) => {
if (input.length > 10) {
throw new ValiError([
{
validation: 'custom',
origin: 'value',
message: 'Invalid length',
input,
...info,
},
]);
}
return input;
},
]);
The string function would raise a ValiError exception if the string is not the correct length. The ValiError exception can be used to provide more specific information about the error, such as the minimum and maximum length of the string: 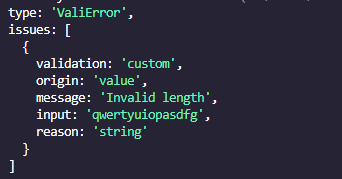 However, due to the complexity of validating with
However, due to the complexity of validating with ValiError and the boilerplate code that it adds to the pipeline, Valibot provides utility functions that handle these errors with minimal code, thus making your code more concise.
Some of these functions are as follows:
-
email -
minValue -
maxValue -
maxLenght -
endWith
These utility functions can be used in the pipeline of different schema functions. For instance, the minValue and maxValue utility functions can be used in the pipeline of string, number, and more:
const StringSchema = string([minValue('2023-07-29')]);
const NumberSchema = number([minValue(1234)]);
Refer to the documentation to learn more about these utility functions.
Use cases
Valibot is well suited for a variety of use cases, but the most common are form validation and server request validation.
Form validation
It is safe to say that form validation is the reason most schema libraries were created. Although their functionality has expanded far beyond form validation, this is still the primary use case for schema libraries.
Valibot's small bundle size and intuitive error handling ensures that user input is accurate and meets your application's requirements. In addition, Valibot eases the validation process in full-stack frameworks such as Next.js, Remix, and Nuxt by allowing them to use the same schema to validate structural data on the client and server simultaneously:
import { object, parse, string } from "valibot";
import { loginUser } from "/api";
const LoginSchema = object({
email: string(),
password: string()
})
export default function LoginRoute() {
async function login(formData: FormData) {
"use server";
try {
const { email, password } = parse(
LoginSchema,
Object.fromEntries(formData.entries())
);
await loginUser({ email, password });
} catch (error) {
// Handle errors
}
}
return (
<form action={login}>
<input name="email" type="email" required />
<input name="password" type="password" required minLength={8} />
<button type="submit">Login</button>
</form>
);
}
Server requests
Server requests are typically handled with a variety of conditional codes, but often these codes are not sufficiently secure to prevent exploitation. Schema rules help to mitigate this risk by ensuring that the data being sent or received from the server conforms to specific requirements. This helps to prevent invalid data from reaching the server or application, which can lead to security vulnerabilities.
Valibot ensures that data is formatted correctly and matches the structure defined in your request schema when making API requests. You can use libraries such as Axios, Fetch, or others in conjunction with Valibot to send HTTP requests.
Below is an example using Axios with Valibot:
import {string, parse, object} from 'valibot'
const schema = object({
username: string(),
email: string(),
password: string()
})
const requestData = parse(schema,{
username: "john_doe",
email: "john@example.com",
password: "securepassword",
});
axios.post("/api/users", requestData);
This helps ensure data consistency, validation, and better communication between the client and server.
Conclusion
Schema validation libraries aren't inherently resource-intensive, so they won't impose significant overhead on your applications. It is a matter of choosing what works best for you. If you prefer the idea of code splitting, tree shaking, and the extra reduction in bundle size, then you may want to make the switch. to Valibot.
I hope you enjoyed this article. Refer to Valibot's documentation for additional information about the library.
LogRocket: Full visibility into your web and mobile apps

LogRocket is a frontend application monitoring solution that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page and mobile apps.

Top comments (0)