
My Final Project
A novel approach to document exploration using Machine Learning. Let's cluster similar research articles together to make it easier for health professionals to find relevant research articles, and respond to rapidly spreading COVID-19 promptly.
Demo Link
https://maksimekin.github.io/COVID19-Literature-Clustering/plots/t-sne_covid-19_interactive.html
Link to Code
 MaksimEkin
/
COVID19-Literature-Clustering
MaksimEkin
/
COVID19-Literature-Clustering
A novel approach to document exploration using Machine Learning. Let's cluster similar research articles together to make it easier for health professionals to find relevant research articles, and responde to rapidly spreading COVID-19 promptly.
COVID-19 Literature Clustering
Goal
Given the large number of literature and the rapid spread of COVID-19, it is difficult for health professionals to keep up with new information on the virus. Can clustering similar research articles together simplify the search for related publications? How can the content of the clusters be qualified?
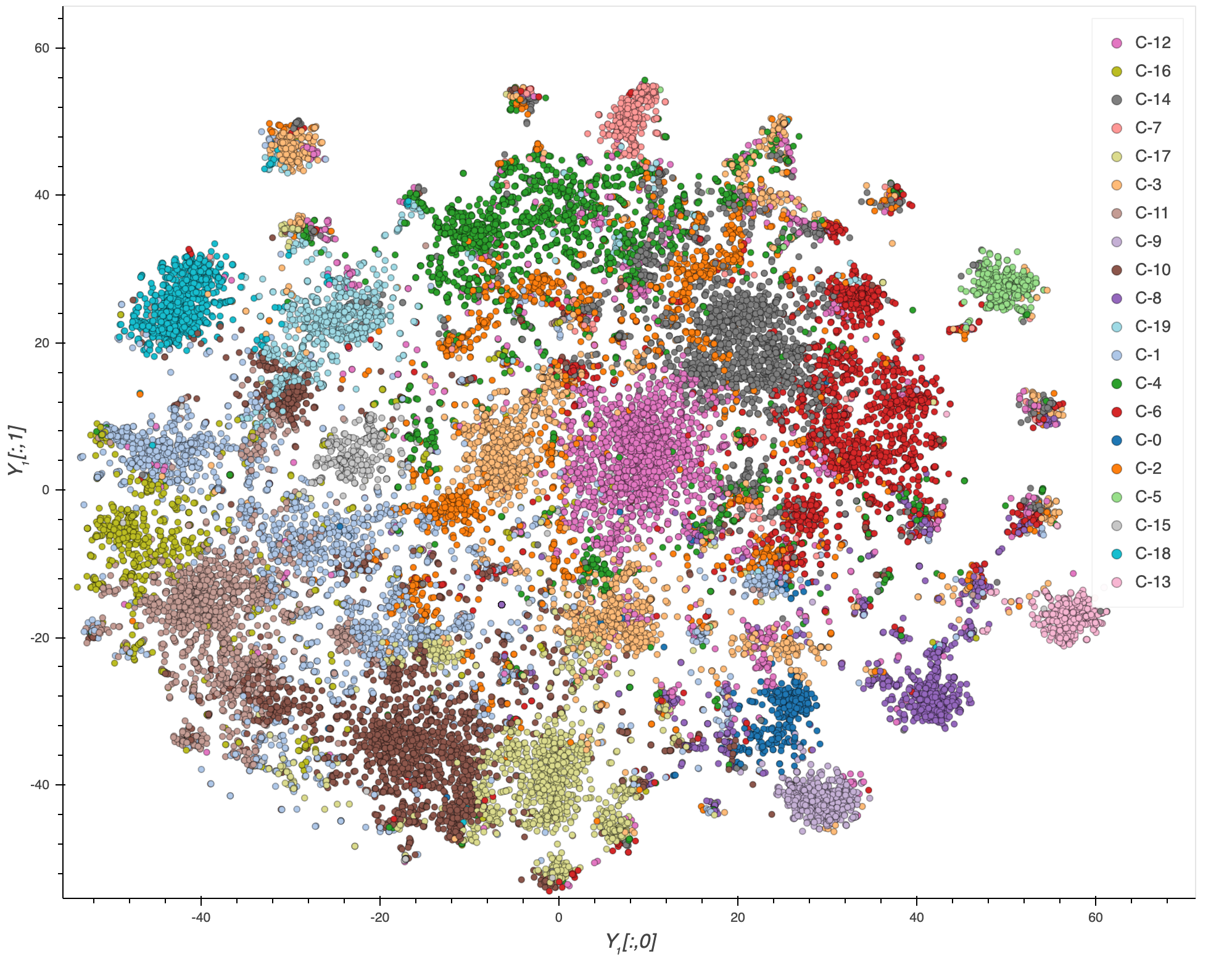
By using clustering for labelling in combination with dimensionality reduction for visualization, the collection of literature can be represented by a scatter plot. On this plot, publications of highly similar topic will share a label and will be plotted near each other. In order, to find meaning in the clusters, topic modelling will be performed to find the keywords of each cluster.
By using Bokeh, the plot will be interactive. User’s will have the option of seeing the plot as a whole or filtering the data by cluster. If a narrower scope is required, the plot will also…
How I built it
- Parse the text from the body of each document using Natural Language Processing (NLP).
- Turn each document instance di into a feature vector Xi using Term Frequency–inverse Document Frequency (TF-IDF).
- Apply Dimensionality Reduction to each feature vector Xi using t-Distributed Stochastic Neighbor Embedding (t-SNE) to cluster similar research articles in the two-dimensional plane X embedding Y1.
- Use Principal Component Analysis (PCA) to project down the dimensions of X to a number of dimensions that will keep .95 variance while removing noise and outliers in embedding Y2.
- Apply k-means clustering on Y2, where k is 20, to label each cluster on Y1.
- Apply Topic Modeling on X using Latent Dirichlet Allocation (LDA) to discover keywords from each cluster.
- Investigate the clusters visually on the plot, zooming down to specific articles as needed, and via classification using Stochastic Gradient Descent (SGD).
Additional Thoughts / Feelings / Stories
You can see the analysis Jupyter Notebook here: https://maksimekin.github.io/COVID19-Literature-Clustering/COVID19_literature_clustering.html
The news video that featured the project can be found here: https://www.youtube.com/watch?v=vyOrM8zC_Iw

Top comments (0)