Data is the new age fuel — If I am not wrong you would have somehow witnessed the power of data and how often we encounter them in our walks of life. The demand to harness the wide range of data, usage of resources, insights gathered from them and necessity to network pushed us to adapt wide varieties of database solutions.
Today’s data we encounter tend to be unstructured preferably. This led to the revolution of No-SQL database solutions. Right now, if you experiment with the market, you would probably encounter hundreds of such solutions available to adapt to your problems. Let’s break the doors of MongoDB now, one of the most popular and widely adapted No-SQL solution briefly.

As a programmer, you think in objects. Now your database does too.
This one from MongoDB’s official document is pretty self-explanatory and note-worthy.
Diving a bit into their homepage you could find this definition,
MongoDB is a general-purpose, document-based, distributed database built for modern application developers and for the cloud era.
Enough with the theory let’s take a use case and experiment the basics of MongoDB intuitively,
Usecase that would make much sense, relatable and interesting would be the present COVID-19 pandemic we are witnessing. Let’s use MongoDB to explore few useful insights about COVID-19 and find how these kinds of solutions stand out when we are dealing with huge volumes of unstructured data.
Note: I do preassume you have MongoDB installed on your machine and we are good to go.
We are going to stick with absolute basics and thus we would deal with data via Mongo shell. We are not going to interact with any actual backend like node or python, which we would possibly cover in one of the upcoming posts.
Make sure your MongoDB server is running and start the shell with the command,
mongo
If you are noticing a terminal screen similar to this you are good to go, just make sure the (>) arrow pointing at,
MongoDB is a document database, which means it stores data in JSON-like documents. You would more likely to encounter such kind of data often and MongoDB community believes this as the most natural way to think about data, and is much more expressive and powerful than the traditional row/column model.
Let’s create a database (say, COVID19-dB) and create a new collection(say, covidReports) and store the current numbers as per the reports from WHO. We planned to continuously update the collections almost every day.
First, let’s check for the available databases using the command,
show dbs
This will list all the available databases,
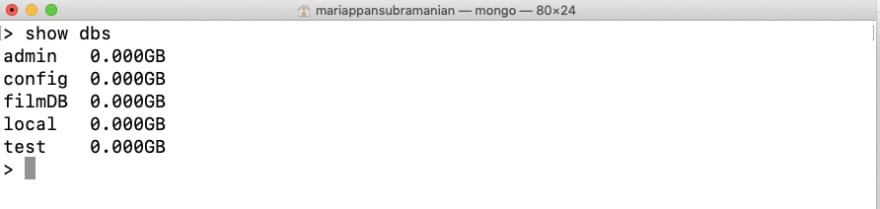
If you notice you can find the database name along with the storage information for each,
Now let’s create one for us,
use COVID19-db — will do the job for us.

Now let’s create a new collection for general COVID world-wide stats and add some data,
Note: MongoDB checks if the collection is available else it creates one for us exclusively on insert.
Let’s say our overall report looks like this,

To add it to the collection covidReports,
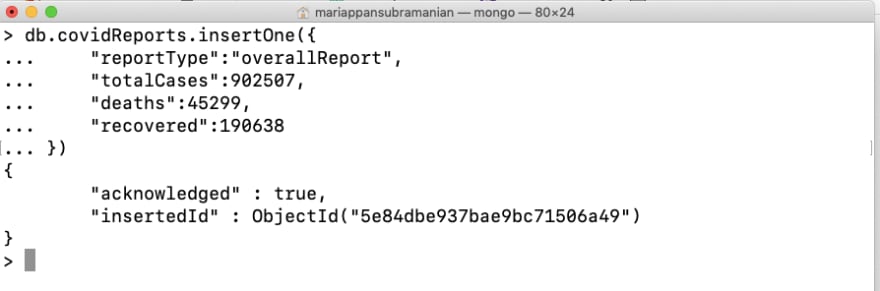
You can notice that the data is successfully inserted and acknowledged, to verify we can use find and inspect all the collections available.

Note: The pretty() over there is just to prettify the document to make it more readable. One more thing is you can find a unique id is being created for the document automatically by MongoDB.
Now let’s say we need country-wise reports too. We can just insert them at the same collection following the previous report as follows,

If we look closer, this is an array of data being inserted, let’s check how the collection looks like,
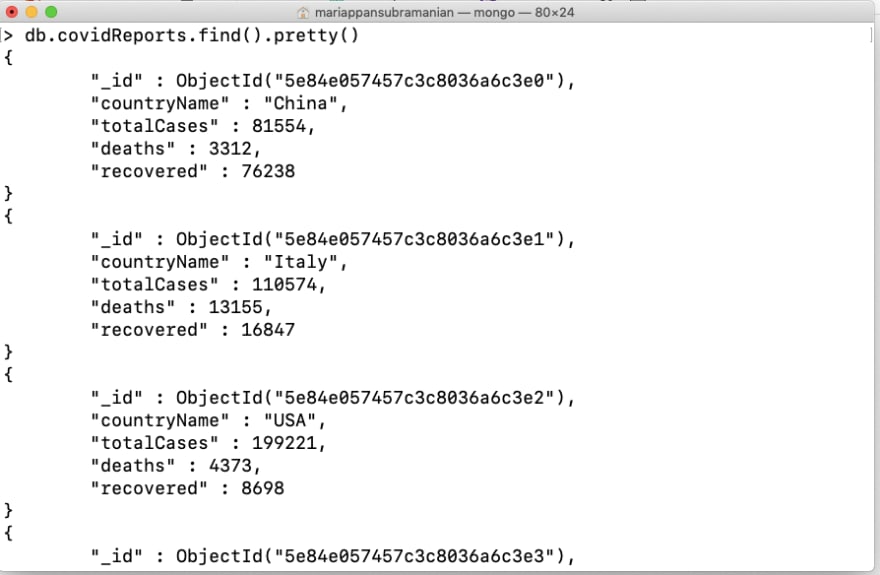
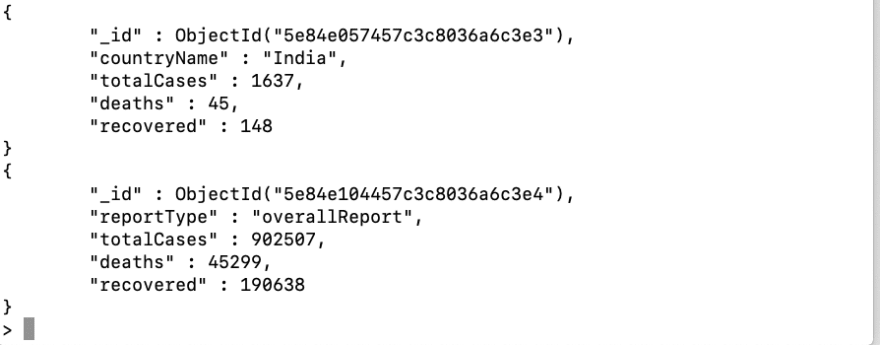
If we look at this result carefully you will find two different types of data is present inside the same collection(one is an overall report and country-wise report with different key-value pairs). This is termed as unstructured data and MongoDB completely accepts this. But we should avoid this kind of usage. Why?
Because imagine you are interacting with this data from some backend like Node.js or PHP and if you try to iterate over this you will find it difficult. Thus even though MongoDB is a schema-less database,it’s good to have a schema model based on our use case to facilitate such kinds of retrievals.
Fine, now we have all the data needed.
For some reason, Let’s say India plans to maintain a separate collection so that they can operate independently and planned. Thus we should remove them from this collection.

World leaders also wish to know the critical cases count so that they could focus more on their welfare and work accordingly. To update,

Now let’s verify if things are going as required,
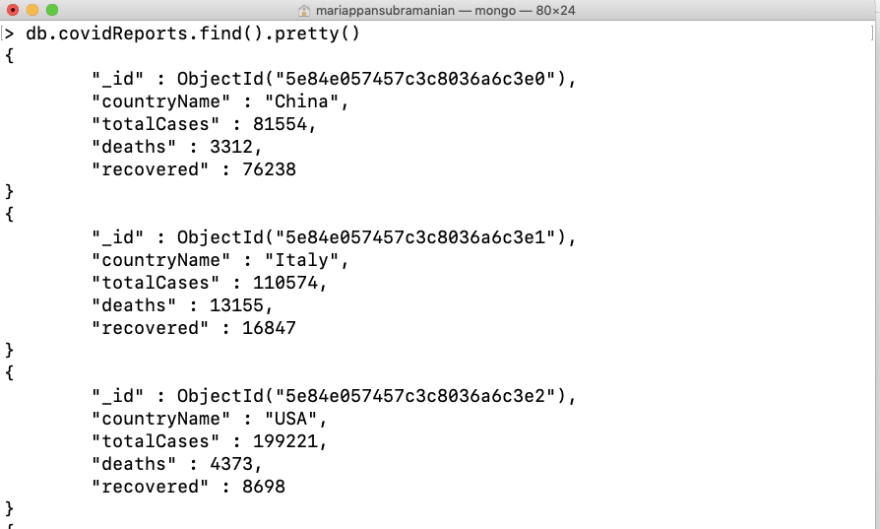
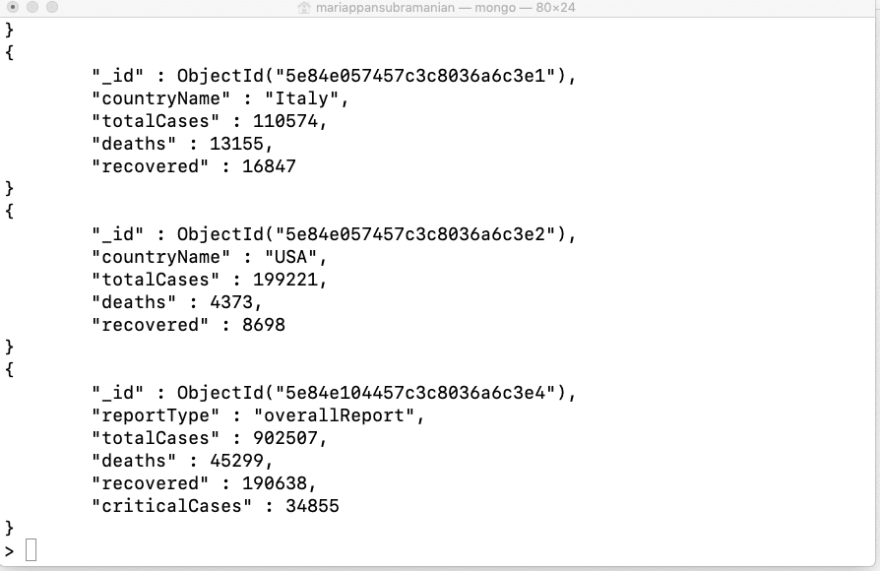
So If you notice here, we see India is been removed and new additional information regarding the critical cases is also updated. Hurray!
Now let’s say we need to mark all those countries and overall report status as critical those satisfies the condition death count greater than 2000, how can we achieve this?

In our case all four documents satisfy the condition, thus all get updated.
One unique feature of MongoDB is embedded documents. This you will not find in any other databases. Thus MongoDB is so much popular and widely used.
This means you can embed any levels of documents inside other documents.
MongoDB supports a maximum of 100 levels of nesting (but it’s a good practise to stop with 2,3 levels itself)
It facilitates us to store a maximum of 16MB, which is fair reasonable since we are going to store only key-value pairs, nothing that heavy.
Now let’s see it in action. Well, each country will have its set of testing and treatment centers at different locations. It should include information such as total patients they could accommodate, helpline numbers, address information, etc.How can we embed such data,
For simplicity let’s embed those data only for the USA since they were in most critical condition and thus it would be extremely helpful for them.
We can update something similar to this,

If you execute find and see how the data looks now,
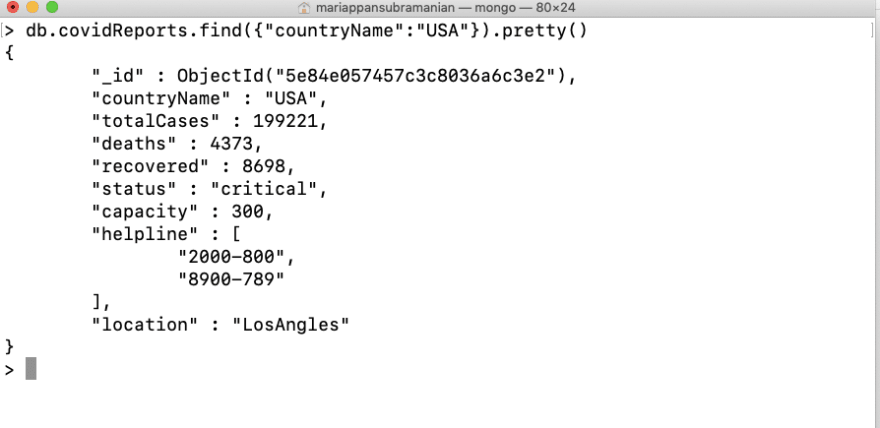
This way you can embed any levels of data if required.
Apart from this, I just wish to touch upon a few things but definitely not in-depth as we decided to stick to the very basics, right? So let me just give a glance of them,
You can have these many types of data types when working with MongoDB,
text
boolean
number — integer, long, decimal
objectId — will contain the timestamp at which the object is created
ISODate — date format to store the date and time in MongoDB
Embedded document — can store one entire document against a key
array — multiple documents or multiple nested documents can be stored for a key
You can also establish a certain relationship between data just like any other databases,
one to one
one to many
many to many
There is a lot more to cover, let’s shift those experimentations to some other future posts hopefully. I hope you had some fun working with MongoDB and let me know if something could have been better 😄
Regards,
Mariappan S
Email: mariappangameo@gmail.com

Top comments (0)