
Introduction
For instance, zero-shot classification only requires some label names to estimate the topic of a document.
I really love football and am a big fan of Liverpool!
Possible topics: [sports, economics, science]
-> Sports (83.52%)
Now, how does that work? Let’s look under the hood and understand why prompt engineering is so interesting.
Using context to predict classes
These models work using context. Let’s say we want to predict the sentiment of a sentence: “The sky is so beautiful”. If we now have the following sentence, “That is [MASK]”, we can try to predict the token for [MASK], i.e., we have a mask prediction. We now provide two options to fill that mask: “positive” and “negative”. If we look at the token likelihood for that prediction, we’ll see that the model picks “positive” due to a higher probability of the chained sentence “The sky is so beautiful. That is positive.”.
We often refer to the masked sentence as the hypothesis template. If we change it, we end up with different predictions. They can be very generic but also specific to the task at hand.
Now, how can we make use of that knowledge of how zero-shot modules work? We can try to enrich the context with as much valuable metadata as possible. For instance, let’s say we have not only label names but also label descriptions. If we want to zero-shot classify hate speech, it is relevant for a classifier to know that hate speech consists of toxic and offensive comments. What could this look like? We add that data to the hypothesis template: “Hate Speech is when people write toxic and offensive comments. The previous paragraph is [MASK]”.
What’s really interesting is that the order of your hypothesis template actually matters. For instance, you could also split the hypothesis template and put the label description on the front of your context, which might improve the accuracy of your model.
Learning without changing parameters
If you think about it, we can turn zero-shot classifiers into few-shot classifiers without fine-tuning the actual model. That is, we don’t have to change any parameters of a given model. Instead, if we have some labeled data, we can just add it to the context. Let’s say we have some examples for positive sentences. We can add to the hypothesis template, “I ate some pizza yesterday, which was delicious. That was great. I saw the movie Sharknado. That was terrible.”
Of course, we don’t want to add enormous amounts of examples to the context, as at some point, it would result in too long runtimes. Additionally, zero-shot classifiers usually hit plateaus in learning quite fast, so regular active transfer learning is a better choice in these cases. Still, adding a few samples to your context, turning a zero-shot model into a few-shot, can significantly improve its performance.
In our soon-to-be-released open-source software Kern, we’re integrating zero-shot classifiers as heuristics to apply weak supervision (we’ve also covered what that is, so check it out in our blog). This way, you can make perfect use of these models without worrying about them hitting plateaus or taking too long during inference.
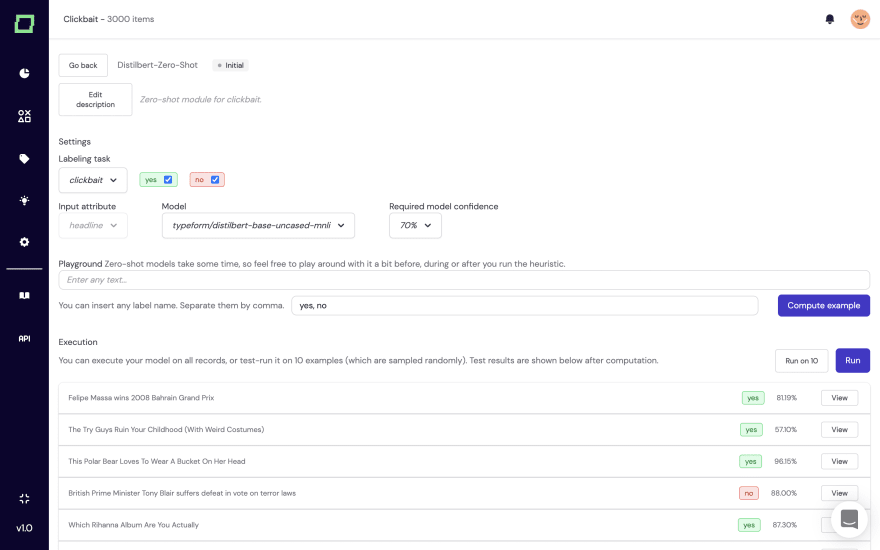
We’re going open-source, try it out yourself
Ultimately, it is best to just play around with some data yourself, right? Well, we’re launching our system soon that we’ve built for more than a year, so feel free to install it locally and play with it. It has a rich set of features, such as integrated transformer models, neural search, and flexible labeling tasks.
Check out our website for more information 👉🏼https://www.kern.ai/
Subscribe to our newsletter 👉🏼 https://www.kern.ai/pages/open-source and stay up to date with the release so you don’t miss out on the chance to win a GeForce RTX 3090 Ti for our launch 😉

Top comments (0)