
This is going to be part of a series of posts in which we show how refinery builds on top of qdrant, an open-source vector search engine.
At Kern AI, we believe that the biggest breakthrough in deep learning is all about embeddings. If you wonder what that means: computers can’t really understand unstructured texts or images. Instead, they require some numeric representation of e.g. a text. But how can you transform text into numbers? This is precisely what neural networks excel at, they can learn such representations. What is the benefit, you might wonder? You can calculate with e.g. the meaning of a text. What is the output of “king” - “man” + “woman”? With embeddings, you’ll get the numeric representation of “queen”. And that is nothing less but breakthrough material!
In other terms: embeddings are a generalization of database technologies. Instead of filtering and searching only on structured data such as spreadsheets, we’re currently experiencing search technologies build on top of embeddings. Effectively, you turn text into a query-able structure that embeds the meaning of the text.

Let’s say you’re looking for the answer to a question in a large text corpus. With embeddings, you can turn the text passages into numeric vectors, and compute the closest vector to your question. Statistically speaking, this gives you the most relevant answer to your question. You don’t even need to match keywords here, embeddings understand synonyms and context!
At Kern AI, we have built refinery, an open-source IDE for data-centric NLP. Here, we make use of large-scale language models to compute said embeddings and enable developers to find e.g. similar training samples, to find outliers, or to programmatically apply labeling to the training data.
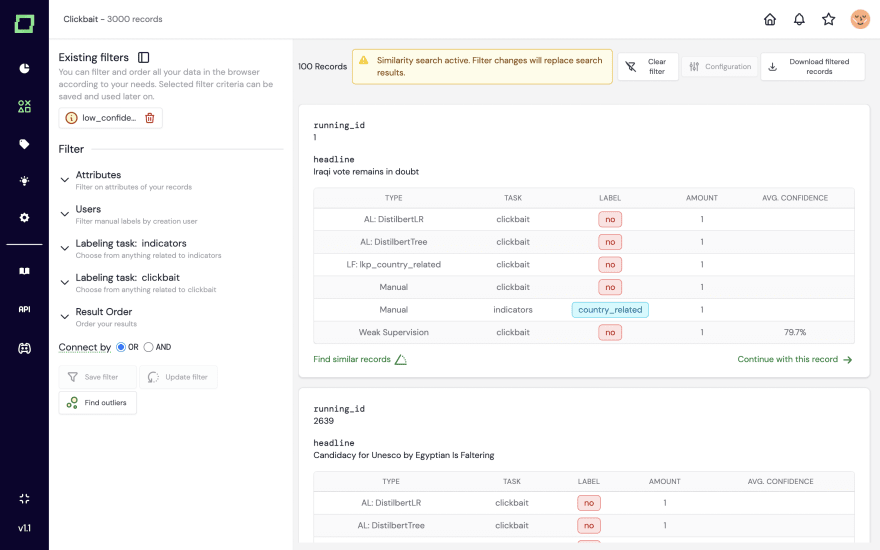
But as we’ve built our developer tool, we realized that scalability was a big issue. Retrieving similar pairs based on their cosine similarity (given by their embeddings) was something we couldn’t do on larger scales, e.g. hundreds of thousands of records.
This is where qdrant, an open-source vector search engine enters the game. Implemented in Rust, their engine provides an API to their vector database which allows you to retrieve similar pairs even under high load within milliseconds.
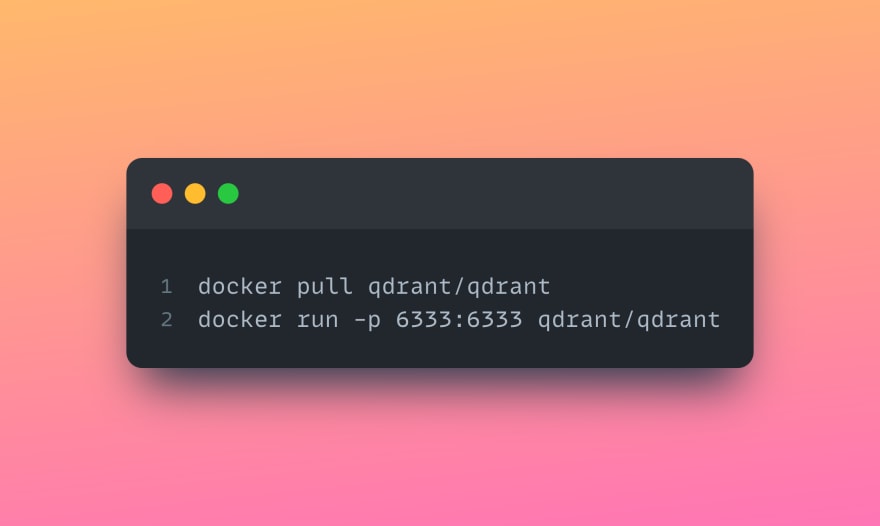
To get started with qdrant, simply execute the following lines in your CLI:
Now, let’s look into an example snippet of our application, in which we have set up an endpoint using FastAPI to retrieve the (up to) 100 most similar records given some reference record:

You can look further into the code base here
As you can see, it is rather straightforward. You need to get the query vector which is your reference, and can limit the result set by a similarity threshold (i.e. which cosine similarity do result records need to have to be contained in the filtered set?). Further, you could extend the search via query filters, which we’re not making use of so far.
With its scalability and stability, qdrant is a core technology in our stack. As the application of similarity search is not only limited to a neural search approach, we’re even using it for features such as recommendation engines. We’re going to share insights about this in a future article.
Now, we encourage you to look into qdrant and their engine. You can see one live example in our online playground, which you can find here: https://demo.kern.ai
Check out their GitHub here: https://github.com/qdrant/qdrant
And don’t forget to leave a star in our refinery: https://github.com/code-kern-ai/refinery

Top comments (0)