If you are using NetworkX, you are aware of the valuable insights you can get from a data network. These networks, or graphs, are becoming popular in diverse business use cases, where they help make important decisions that affect business success in many ways.
NetworkX has a large set of interesting graph algorithms, and it can analyze a network of data fast, but only on a certain scale. You might have found yourself wondering how you can stay in a safe world built around NetworkX graph algorithms but still be able to create production-ready applications to share your work with others easily. Maybe you are bored of writing hundreds of lines of code just to get the data you want to explore.
This blog post will tell you more about how to avoid all of that boilerplate code and smoothly deploy applications by using Memgraph, an open-source in-memory graph database, on which you can perform graph analytics using NetworkX you are familiar with, both on static and streaming datasets.
Seamlessly connect to many data sources with Memgraph
The beginning of every NetworkX project includes data import. If you are importing data from different sources, your code is probably snowballing with every additional source. Things are getting messy, and every time you change something in the code, you have to pull the data from all those different sources all over again. The project gets harder to maintain, and your time gets unnecessarily wasted on pulling the data rather than on the actual analysis.
With Memgraph, you can easily connect to data sources and import the data at the beginning of your project, as well as change it on the fly. Although it is in-memory, Memgraph still persists your data, meaning your dataset doesn’t have to be loaded on each run. It’s enough to load it once and then query, analyze and change it. You can explore parts of the graph you need and deliver an analysis of the dataset. How does Memgraph do it?
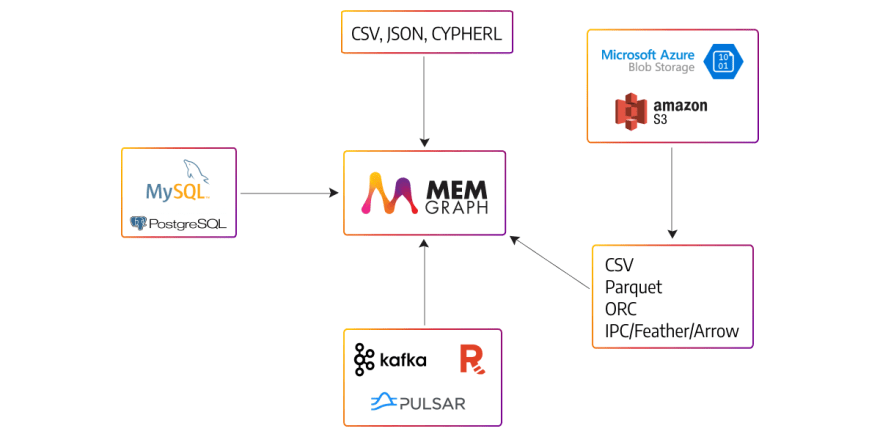
Memgraph natively has several methods of data import - import from files, MySQL or PostgreSQL, and data streams. Memgraph is also highly extendable, and with the help of its Python client, GQLAlchemy, you can import data from almost anywhere.
GQLAlchemy’s loaders.py translates table data from a file to graph data and imports it into Memgraph. Currently, GQLALchemy supports the reading of CSV, Parquet, ORC, and IPC/Feather/Arrow file formats via the PyArrow package. These files can be loaded from local sources, Azure Blob storage, or Amazon S3 service. Besides that, if you want to read from a file system currently not supported by GQLAlchemy, or read from a different source, you can implement a custom file system importer, by extending abstract classes FileSystemHandler and DataLoader.
Memgraph is especially useful when it comes to importing streaming datasets because it can connect to any Kafka, Pulsar, or Redpanda stream of data. For example, if you are using Debezium in your company to monitor changes in a database, with Memgraph, you can connect to that Kafka stream.
Since NetworkX algorithms are run on graphs that are currently in-memory, it doesn’t offer the possibility of having a dynamic graph and running dynamic graph algorithms on each change. Memgraph can do that with the help of triggers that fire up dynamic algorithms on a certain change or update in the database. This kind of setup gives you the results of graph algorithms much faster. Check out which dynamic graph algorithms are so far implemented in MAGE, an open-source repository that contains graph algorithms and modules written in Python, C/C++, and Rust.
So, if your project requires importing streaming or static data from various sources, you don’t have to worry about importing in your NetworkX code.
Memgraph and NetworkX integration
NetworkX offers a wide range of graph algorithms to explore the data, and it is possible to use them within Memgraph. Memgraph is built in C++ and it holds wrapper objects for Memgraph’s graphs, called MemgraphGraph, MemgraphDiGraph, MemgraphMultiGraph or MemgraphMultiDiGraph, depending on the graph type stored in the database.
These objects optimize the usage of NetworkX algorithms. To make the transition to Memgraph more convenient, we implemented procedures that call NetworkX functions with Memgraph graphs so that you have out-of-the-box access to graph algorithms.
For example, call the betweenness_centrality algorithm on the preloaded dataset by running:
CALL nxalg.betweenness_centrality() YIELD *;
Here is a list of all implemented NetworkX algorithms. To learn more about the usage of NetworkX algorithms in Memgraph, check out the Social network analysis with NetworkX tutorial.
Cypher query language, used to query Memgraph, is easily extendible with custom procedures bundled up in query modules. These procedures can be written in Python, C/C++ and Rust. Inside the custom procedures written in Python you can use the NetworkX library. The easiest way to implement a custom procedure is to use Memgraph Lab, Memgraph’s visual user interface. Just paste the NetworkX code to the custom read or write procedure in the code editor in the Query Modules section of Memgraph Lab.
To use the custom procedure, call it with the Cypher CALL clause. Memgraph doesn’t have a custom implementation of the girvan_newman community algorithm so it can be implemented within the custom read procedure. Just be careful to use the correct graph type, depending on the dataset - Graph, DiGraph, MultiGraph, or MultiDiGraph.

In the above example, MemgraphDiGraph is created from mgp.ProcCtx, which represents the whole graph inside the database in its current state. That graph is cast to the NetworkX DiGraph, so that NetworkX girvan_newman algorithm can be used. The procedure returns lists of nodes belonging to a certain community.
To call the above custom procedure, we first need to import a dataset. Many datasets can be found in the Datasets section of the Lab. We are going to query the dataset Karate club friendship network.

The query used to call the custom procedure and return its results is:
CALL communities.detect()
YIELD communities
UNWIND communities AS community
RETURN community;
Here are the obtained results on the template dataset Karate club friendship network.

In the standalone NetworkX script, you would first need a bunch of code to pull all the data you want to explore. Then you would call the algorithm, and at the end, the results would have to be stored somewhere. So, to run one simple algorithm, you would have to write A LOT of code. Now multiply that with a couple more data sources and a much more complicated analysis with NetworkX. With Memgraph, you import data or connect to data sources and run your favorite existing or custom graph algorithm.
For more examples of utilizing NetworkX integration, check out the Exploring a musical social network tutorial on Memgraph documentation.
Share the results of your work easily
NetworkX is not a database, so of course, it is missing other features that come in handy when you are deploying your application. For example, with a graph database, you can always do ad-hoc graph querying. If you are using Memgraph, you also get a set of scalable and production-ready algorithms called MAGE (Memgraph Advanced Graph Extensions). This means that you can have your whole project in one place.
Dataset is loaded inside Memgraph, you can explore it with Memgraph Lab by querying the database or by running already implemented or custom procedures. It gives you the necessary flexibility while still remaining easy to use and share with others. Your script can hold graph analysis, machine learning projects, simple calculations, and can write back to the database or just read and return the wanted results.
Your queries can be visualized with Memgraph Lab and sent or presented to your colleagues. Also, if you are deploying your project, you don’t need to worry about the set of components needed for your application to run, you just have to manage Memgraph.
There are many ways to deploy and manage your project, but to make it easier for you, we prepared docker-compose.yml files necessary to run Memgraph Docker images. Read one our blog posts to learn more about how to orchestrate your graph application with Docker Compose. If you need Memgraph as a part of your Kubernetes cluster, you can use the prepared Helm Chart for a simple setup.

Memgraph Lab offers the possibility to save prepared queries in query collections. Memgraph Lab has rich query collections, allowing you to name every query inside the collection and add its description. Also, you can run each query inside the collection to present the results of your work.
Conclusion
Memgraph is a drop-in replacement for a huge part of the boilerplate code in the NetworkX project and give relevant insights. It can work with streaming or static datasets and it offers easy integration of any NetworkX code.
The results provided by Memgraph, in terms of visualization and speed, are incredible and good enough reason to try it out now. Check out how Memgraph deals with data persistency, large-scale data analytics and visualizations when compared to NetworkX and how much faster Memgraph graph algorithms are.
To learn more, head over to our resources for NetworkX developers.

Top comments (0)