
Intro
Since getting my AWS Solutions Architect certification, I have been finding ways to actually build products in AWS. I especially want to focus on serverless applications. AWS provides some guidelines on hands-on projects to engage users. This project utilizes AWS Lambda, builds an API Gateway, writes to a persistent DynamoDB table, authenticates with Cognito, and employs Git via the Amplify Console. This post will summarize the actions I took and what I learned throughout the hands-on project.
The Project
The AWS Hands-On Project can be found at:
https://aws.amazon.com/getting-started/hands-on/build-serverless-web-app-lambda-apigateway-s3-dynamodb-cognito/
For the purposes of the Hands-On Project, the website WildRydes.com has been created for us to use. It allows users to request a ride from a unicorn, similar to Uber. Users must first sign up and validate through their email.
Git Repository via Terminal
We clone the git repository to copy all of the website source code to our computer, and use AWS CodeCommit to store our application code. I've spent lots of time in GitHub, but not lots of time working with Git in terminal. I employed Stack Overflow to help with some errors I encountered.
I also had to install Git after receiving 'git' is not recognized as an internal or external command error.
Creating the empty git repository was as simple as git clone.
Populating the git repository provided a couple errors. I copy the contents from AWS S3 into my newly created repository using aws s3 cp s3://wildrydes-us-east-1/WebApplication/1_StaticWebHosting/website ./ --recursive. In this case the cp copies, and --recursive repeats for each instance in the folder.
The warnings about line endings were unnerving, but a quick search shows that in Windows a line is represented with a carriage return (CR) and a line feed (LF). I turned this message off by using git config core.autocrlf true.
This is my first real error. I add all contents to my repository, but was not able to push to CodeCommit.

After searching for similar errors, I found I needed to do an initial commit before pushing content. This was fixed by git commit -m "initial commit"
Then I was able to push the content to CodeCommit without issues.
AWS Amplify Console
This was my first time using the Amplify Console. The Amplify Console provides a git-based workflow for continuous deployment and hosting full-stack web resources (including HTML, CSS, JavaScript, and image files which are loaded in the user's browser). This is where the changes go when I "push".
Amplify was useful to preview the changes during code reviews and changes, manage production and staging environment, ensure my app rendered on different mobile device correctly. Amplify detects when there are new pushed changes, and rebuilds and redeploys the app accordingly.


AWS Cognito
We use Cognito User Pools to authenticate and sign-up clients for our web app. We could have used an Identity Pool if we wanted our users to authenticate via third party platforms such as Google or Facebook. All actions are completed in a user-friendly console. I require new users to verify via their emails and provide a single use code after registration.

Cognito allows use to manage password attributes to ensure the security of our web app. This includes, minimum password length, requiring special characters and numbers in the password, password expiration rules, MFA, and can even trigger Lambda to complete actions for us.
Serverless Backend
To build the backend handling requests, we use AWS Lambda and Amazon DynamoDB. Each time a user makes a request on the website (to ride a unicorn), a Lambda function will be triggered. The DynamoDB table (also serverless) responds to the front-end application and logs the requests.
DynamoDB
DynamoDB is a fast, NoSQL database. It can automatically scale throughput capacity to meet workload demands. It is fully managed, meaning AWS takes care of all hardware, configuring, patching, and scaling. Sign me up.

The table and its settings were easy to set up. I set the Primary Key to be a String, and AWS generates a unique string for each row. The figure above shows the attributes when a user makes a request from the website.
IAM Roles
An AWS role had to be created to allow the Lambda function and DynamoDB table interact with each other. These are just permissions to interact and write the data to the table and write logs to CloudWatch.
The most important part for me was to ensure the custom inline policy was done correctly. This was done by entering PutItem as a service for DynamoDB.

Lambda
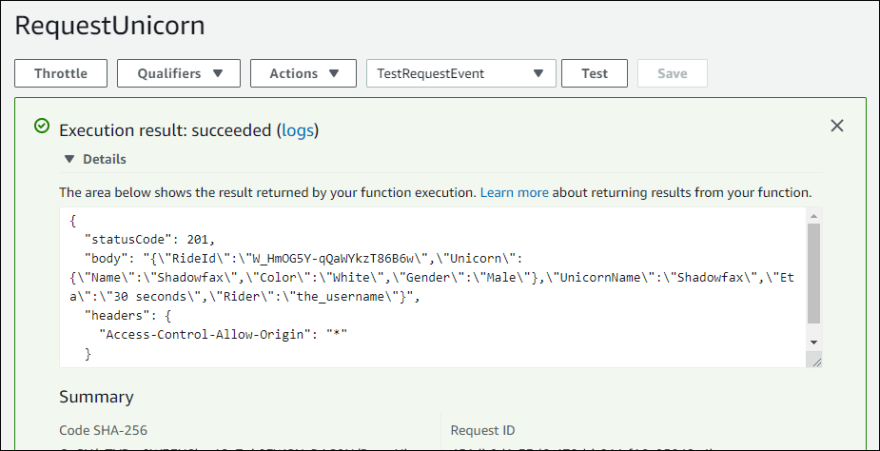
Lambda functions are the true heart of serverless services. Lambda ensures that we only run a compute service at the moment we need it, and terminate when we are done. This is much, much cheaper than keeping an EC2 instance running at all times waiting for users. The Lambda service is triggered by the HTTP request of a user requesting a unicorn ride on our website. AWS allows you to run tests in the console. This image shows I set up the Lambda function and it runs with the function code.
RESTful APIs
The API Gateway is HTTP-based enables stateless client-server communication. This connects our website to AWS Services and acts as a "gateway" as in it handles all the tasks involved in accepting and processing many calls. So if there were a massive surge in unicorn ride requests, the API gateway will handle all these requests and call the correct amount of Lambda functions to handle the surge. This also interacts with the Cognito User Pool to authenticate the API calls.
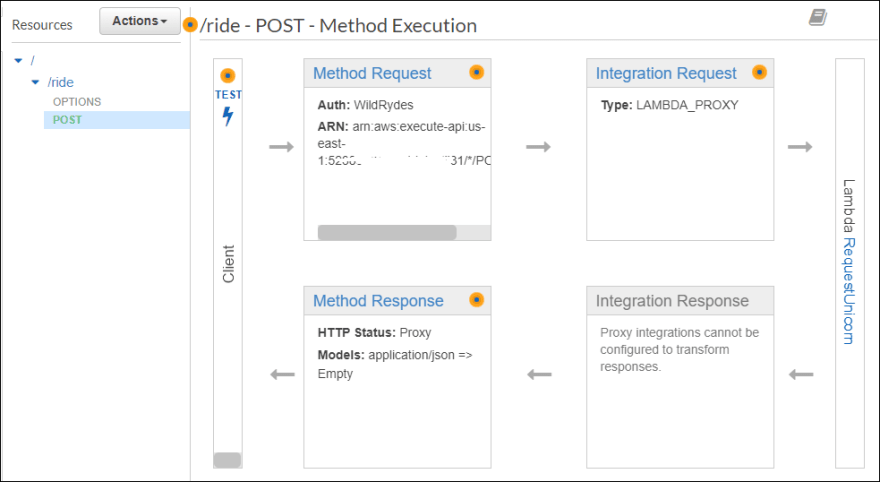
This figure shows the path taken by the API Gateway: A POST method is used to call the Lambda function. The HTTP POST method is used to send data to a server to create or update a resource. It is different from a PUT method is non-idempotent and its response can be cached, the PUT method is idempotent, and its responses are not cacheable. This I had to look up to understand the difference.
Deploying
The config.js file in our website has to be updated to include the API invoke URL and the Cognito User Pool information.
This was then pushed to the git repository and deployed via AWS CodeCommit.
Testing Website
Testing the website shows I am able to create a new user, verify identity with a single-use code from the supplied email, load a map and successfully hail a unicorn for a ride. The request returns that I am getting a ride from Shadowfax.
Wrap it Up
This project provided really great practice at building with foundational AWS tools. I've read tons of documentation, and able to say in theory how they work, but putting them together in a functional website solidified my understanding.
Creating a serverless backend is important to understand and implement. There seems to be a huge push to move to serverless. This makes sense as it saves money and requires less resources to be constantly up and running. Letting AWS manage the resources makes sense for a web app like ours. If we were running an app that constantly had requests or known surge hours, we may have wanted to spin up some EC2 instances. For example, if we knew on everyday at exactly 9am and 5pm thousands of requests for rides would happen, then auto-scaling EC2 instances at a scheduled time might make sense. But since we are working with serverless products, staying with Lambda is the best option and has the capacity to handle the requests.
The biggest lesson learned for me was creating the RESTful API. Truthfully, when I first started studying cloud computing last year, I did not understand what an API was. I just assumed it was over my head and did not read into it. Learning more about APIs in theory and practice has been very eye opening. RESTful APIs are used to expose and organize access to web services such as AWS and provides efficient code to complete HTTP methods. REST means the API is stateless and can be easily redeployed if it fails and can scale to accomodate an surges. Cloud computing has made RESTful APIs incredibly useful and will be here to stay.
Overall, I am glad I was able to practice with more AWS services. I learned a lot from this project. I am looking forward to completing more hands-on projects that will really test my skills and get me out of my comfort zone.

Top comments (0)