How to do it and is it a good idea?
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--Z-IOIPNZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/11520/0%2AX8A8V7gkYlcNNzD4)
TL;DR
Adding sequential unique IDs to a Spark Dataframe is not very straight-forward, especially considering the distributed nature of it. You can do this using either zipWithIndex() or row_number() (depending on the amount and kind of your data) but in every case there is a catch regarding performance.
The idea behind this
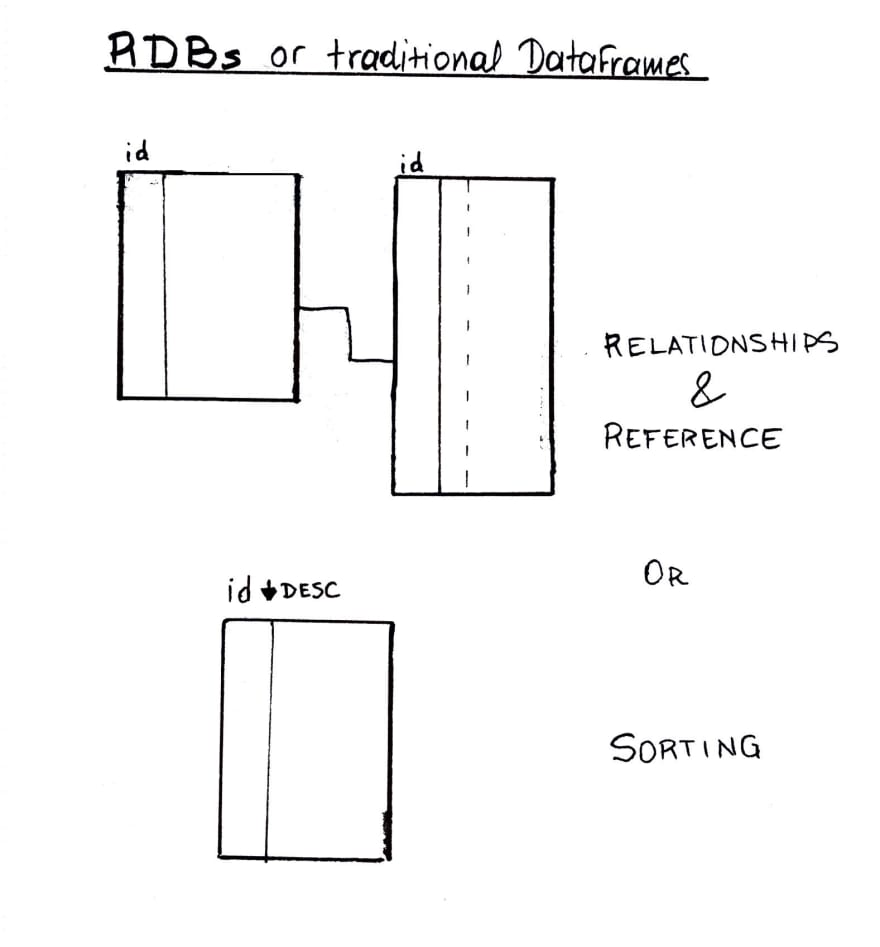
Coming from traditional relational databases, like MySQL, and non-distributed data frames, like Pandas, one may be used to working with ids (auto-incremented usually) for identification of course but also the ordering and constraints you can have in data by using them as reference. For example, ordering your data by id (which is usually an indexed field) in a descending order, will give you the most recent rows first etc.
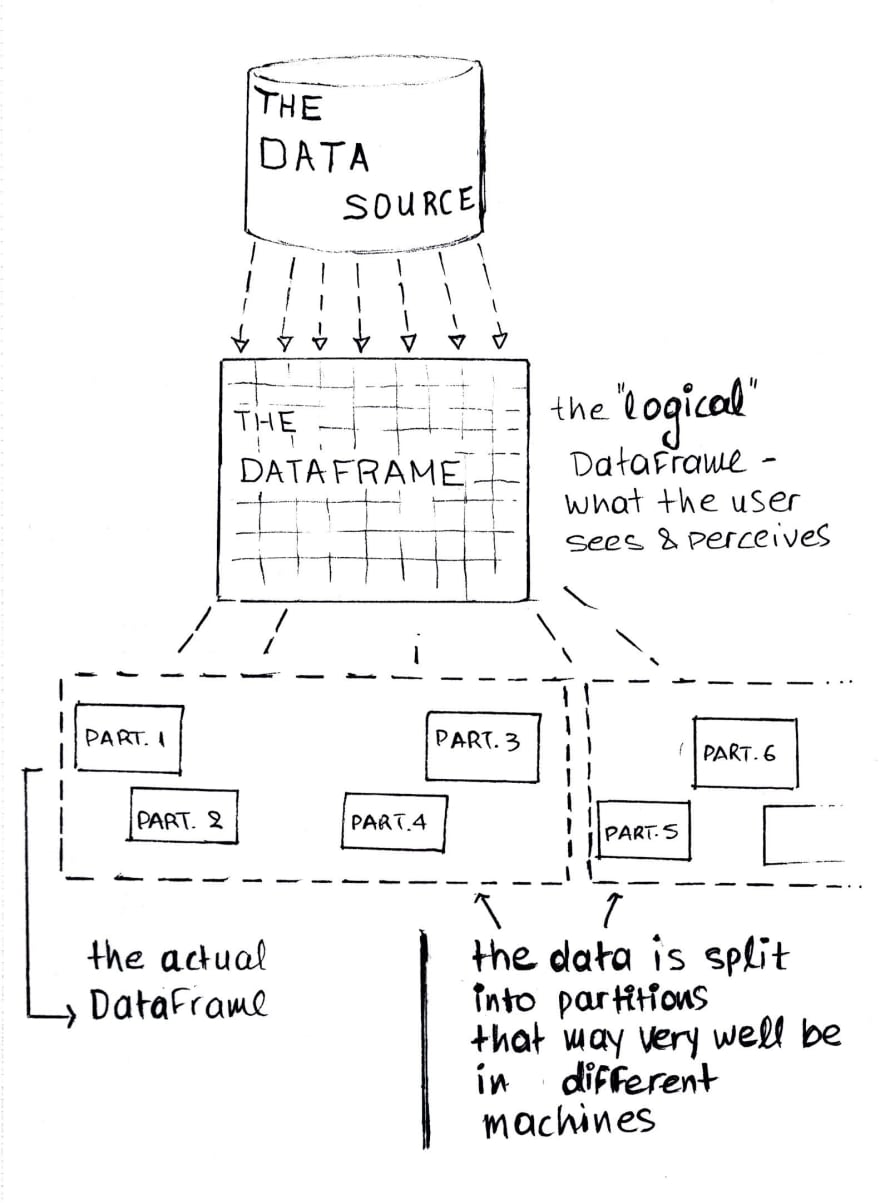
Depending on the needs, we might be found in a position where we would benefit from having a (unique) auto-increment-ids’-like behavior in a spark dataframe. When the data is in one table or dataframe (in one machine), adding ids is pretty straigth-forward. What happens though when you have distributed data, split into partitions that might reside in different machines like in Spark?
(More on partitions here)
Throughout this post, we will explore the obvious and not so obvious options, what they do, and the catch behind using them.
Notes
Please, note that this article assumes that you have some working knowledge of Spark, and more specifically of PySpark. If not, here is a short intro with what it is and I’ve put several helpful resources in the Useful links and notes section. I’ll be glad to answer any questions I can :).
Practicing Sketchnoting again, yes, there are terrible sketches through out the article, trying to visually explain things as I understand them. I hope they are more helpful than they are confusing :).
The RDD way — zipWithIndex()
One option is to fall back to RDDs
resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel
and use df.rdd.zipWithIndex():
The ordering is first based on the partition index and then the
ordering of items within each partition. So the first item in
the first partition gets index 0, and the last item in the last
partition receives the largest index.
This method needs to trigger a spark job when this RDD contains
more than one partitions.
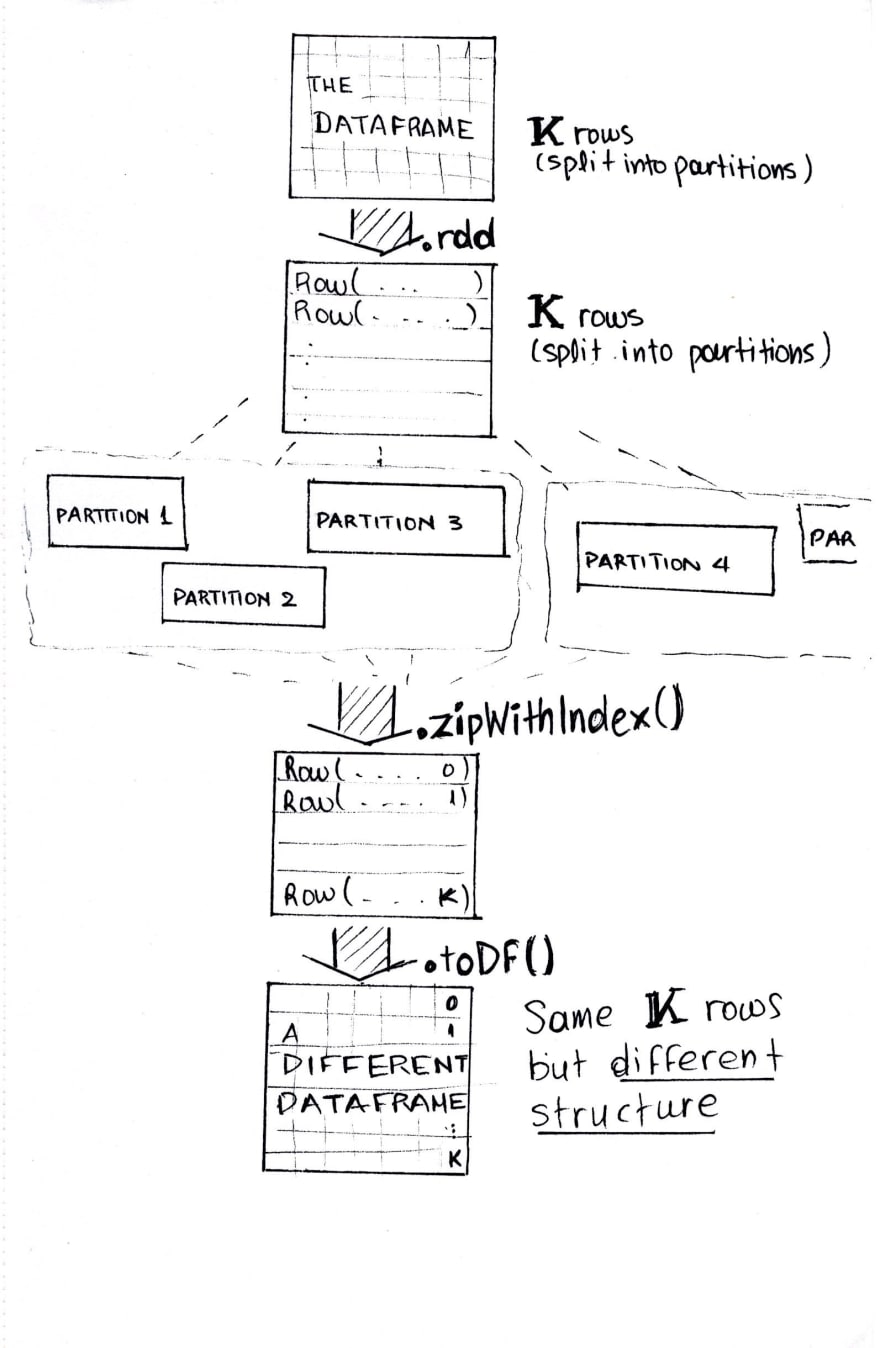
Four points here:
The indexes will be starting from 0 **and the **ordering **is done **by partition
You will need to have all your data in the dataframe — additions* will not add an auto-increment id
Falling back to rdds and then to dataframe **can be quite expensive.**
The updated version of your dataframe with ids will require you to do some extra work to bring your dataframe back to its original form. Which also adds to the performance toll.
*You cannot really update or add to a dataframe, since they are immutable but you could for example join one with another and end up with a dataframe that has more rows than the original.
The Dataframe way
If your data is sortable
If you can order your data by one of the columns, let’s say column1 in our example, then you can use the row_number() function to provide, well, row numbers:
row_number() is a windowing function, which means it operates over predefined windows / groups of data.
The points here:
Your data must be sortable
You will need to work with a very big window (as big as your data)
Your indexes will be starting from 1
You will need to have all your data in the dataframe — updates will not add an auto-increment id
No extra work to reformat your dataframe
But you might end up with an OOM Exception, as I’ll explain in a bit.
If your data is NOT sortable — or you don’t want to change the current order of your data
Another option, is to combine row_number() with monotonically_increasing_id(), which according to the documentation creates:
A column that generates monotonically increasing 64-bit integers.
The generated ID is guaranteed to be monotonically increasing and unique, but not consecutive. The current implementation puts the partition ID in the upper 31 bits, and the record number within each partition in the lower 33 bits. The assumption is that the data frame has less than 1 billion partitions, and each partition has less than 8 billion records.
The monotonically **increasing and unique, but not consecutive **is the key here. Which means you can sort by them but you cannot trust them to be sequential. In some cases, where you only need sorting, monotonically_increasing_id() comes in very handy and you don’t need the row_number() at all. But in this case, let’s say we absolutely need to have consequent ids.
Again, resuming from where we left things in code:
There are of course different ways (semantically) to go about it. For example, you could use a temp view (which has no obvious advantage other than you can use the pyspark SQL syntax):
>>> df_final.createOrReplaceTempView(‘df_final’)
>>> spark.sql(‘select row_number() over (order by “monotonically_increasing_id”) as row_num, * from df_final’)
The points here:
- Same as above but also a small side note that practically the ordering **is done **by partition
And the very big catch to this whole effort
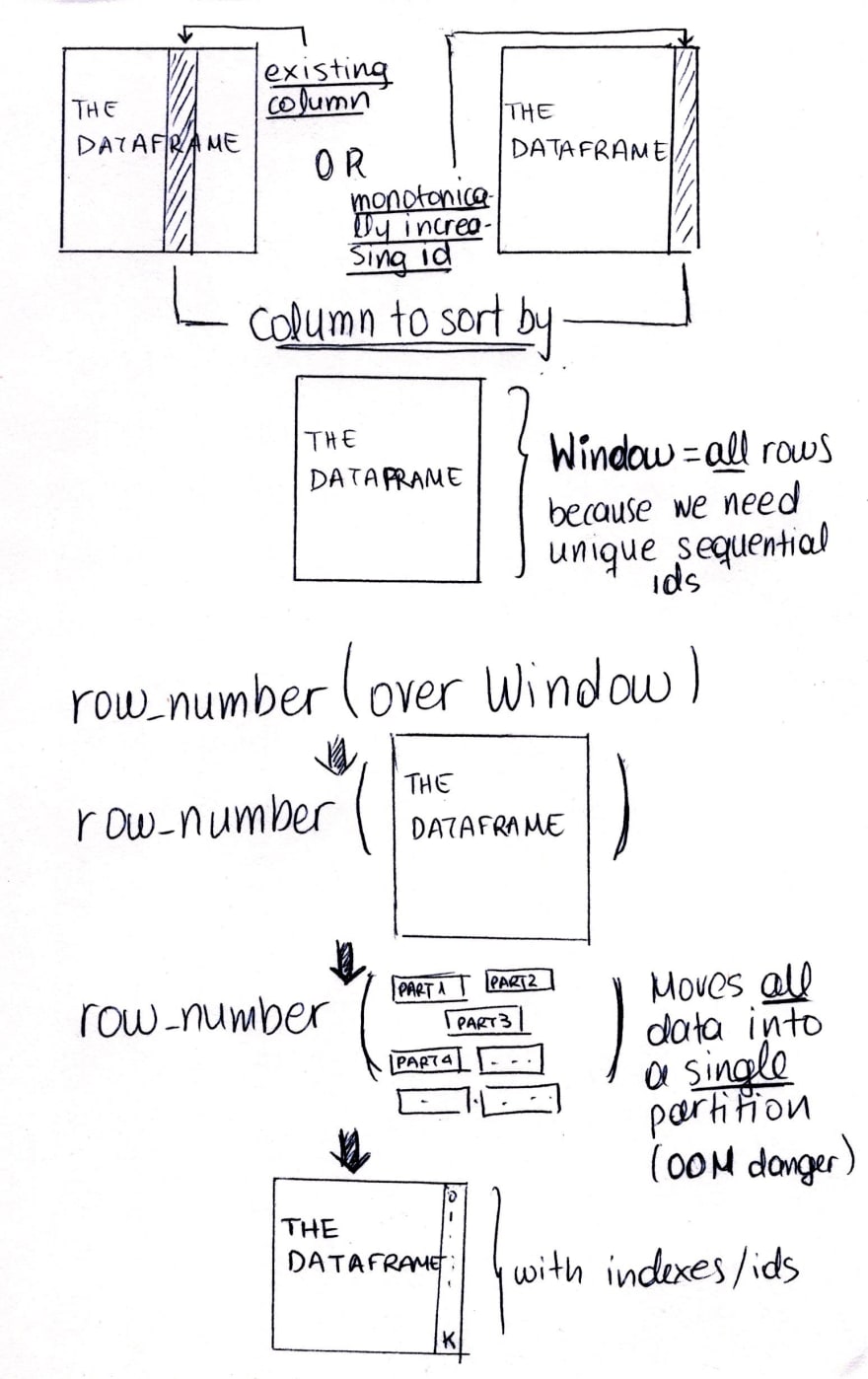
In order to use row_number(), we need to move our data into one partition. The Window in both cases (sortable and not sortable data) consists basically of all the rows we currently have so that the row_number() function can go over them and increment the row number. This can cause performance and memory issues — we can easily go OOM, depending on how much data and how much memory we have. So, my suggestion would be to really ask yourself if you need an auto-increment/ indexing like behavior for your data or if you can do things another way and avoid this, because it will be expensive. Especially if you process arbitrary amounts of data each time, so careful memory amount consideration cannot be done (e.g. processing streaming data in groups or windows).
Spark will give you the following warning whenever you use Window without providing a way to partition your data:
WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
Conclusion: is this a good idea or not?
Well, probably not. In my experience, if you find yourself needing this kind of functionality, then you should take a good look at your needs and the transformation process you have and figure out ways around it if possible. Even if you use zipWithIndex() the performance of your application will probably still suffer — but it seems like a safer option to me.
But if you cannot avoid it, at least be aware of the mechanism behind it, the risks and plan accordingly.
I hope this was helpful. Any thoughts, questions, corrections and suggestions are very welcome :)
Useful links and notes
Adjusting the indexes start from 0
The indexes when using row_number() start from 1. To have them start from 0 we can simply deduct 1 from the row_num column:
df_final = df_final.withColumn(‘row_num’, F.col(‘row_num’)-1)
On RDDs and Datasets
A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets
*In summation, the choice of when to use RDD or DataFrame and/or Dataset seems obvious. While the former offers you…*databricks.com
RDD Programming Guide
*Spark 2.4.4 is built and distributed to work with Scala 2.12 by default. (Spark can be built to work with other…*spark.apache.org
About createOrReplaceTempView
This creates (or replaces if that view name already exists) a lazily evaluated “view” of you data, which means that if you don’t cache/ persist it, each time you access the view any calculations will run again. In general, you can then use like a hive table in Spark SQL.
pyspark.sql module - PySpark 2.4.4 documentation
*schema - a pyspark.sql.types.DataType or a datatype string or a list of column names, default is . The data type string…*spark.apache.org
Row Number and Windows
pyspark.sql module - PySpark 2.4.4 documentation
*schema - a pyspark.sql.types.DataType or a datatype string or a list of column names, default is . The data type string…*spark.apache.org
Introducing Window Functions in Spark SQL
*In this blog post, we introduce the new window function feature that was added in Apache Spark 1.4. Window functions…*databricks.com
Where to next?
Understanding your Machine Learning model’s predictions:
Machine Learning Interpretability — Shapley Values with PySpark
*Interpreting Isolation Forest’s predictions — and not only*medium.com
Originally published at Medium

Top comments (0)