Originall published on my blog
Versioning RESTful API endpoints kind of sucks, there are a bunch of ways to do it all with different tradeoffs which are largely semantic and no real consensus on the "right" way to do it. Thinking about versioning endpoints brings to mind that Winston Churchill quote about democracy:
democracy is the worst form of government – except for all the others that have been tried.
Where you can replace democracy & government with your preferred style & versioning respectfully. I think this largely comes from the fact that there isn't an ordained way to go about making breaking changes to your API outside of either don't or version it.
Endpoints though are not the only thing that should be versioned in an API, you should also be thinking about how you want to version your data. If you aren't versioning the data in your API and taking the default naive approach you are left in a place where the last write wins where whoever sends their request last will potentially overwrite any previous changes. You can visualise the problem like so:
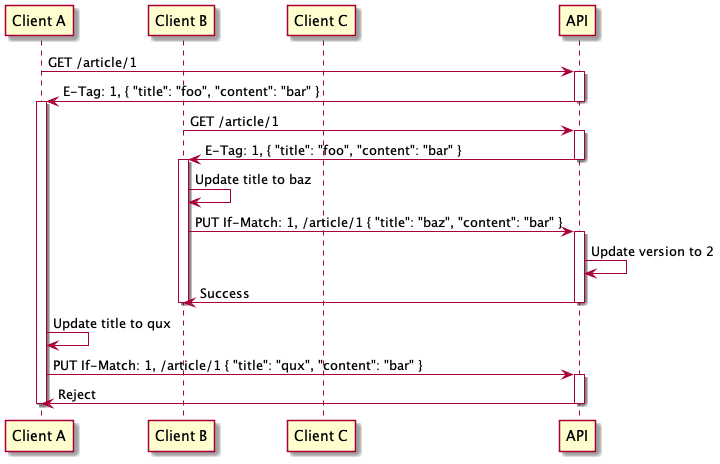
In our hypothetical example both Client A and Client B have fetched and modified the same resource from the API but because Client A submitted their change last they have overwritten the changes made by Client B and none are the wiser Client B doesn't know their changes have been overwritten and Client A didn't know they weren't working on the latest version of the resource. In the worst case scenario from there those two clients may continue working working on the increasingly divergent resource each time overwriting the others changes.
This issue is most prevalent when updating an entity using the PUT method where you are replacing the entire resource (as opposed to PATCH which is only a partial modification). You could find yourself changing fields back to a previous state that someone else had modified.
Unlike endpoint versioning HTTP does provide us a couple of "right" ways to version the data in our APIs utilising standard headers. The first of these is If-Unmodified-Since this header accepts a datetime as a value that should correspond to the the datetime which the client retrieved the resource, when updating the resource if the last changed time on the server is more recent than that supplied in the header the change is rejected.

While this is likely this is the easier of the two options to implment (IMO) it doesn't completely mitigate the last write wins problem. With this approach we are reliant on clients to track when they retrieved the resource, if the client so chooses they could just specify the current datetime when making the update and the API would be none the wiser.
The second approach utilises two HTTP headers ETag and If-Match. The ETag header is supplied by an API when returning a resource and the value is intended to represent the version of that resource. What you use to represent that version is up to you as an API implementor, I often use a UUID that I store with the resource in the database but more commonly you will see APIs use a hash of the content or a revision number. The If-Match header is the other half of the solution, the client uses this header when sending the update to the API and it should contain the version of the resource (received via the ETag) that the client has modified. If the version supplied in the request does not match what the API is expecting then it will reject the update.

My preference is to use the ETag / If-Match combination as while it is a little more effort to implement it provides better protection against overwritting other clients changes to resources. Regardless of how you approach versioning of data in your API I think that it's important that you do version the data. It provides clients integrating against your API a consistent and expected experience where they can rely on any data they submit not being accidentally overwritten.

Top comments (0)