I accidentally came across this CloudGuru challenge while I was browsing their website. I love challenges, and after reading the description I thought I could give it a go for a few reasons:
- it would give me a good practical experience with a range of AWS technologies
- it seemed interesting
- it's not too much time consuming
About the challenge
The challenge was to implement ETL process using AWS cloud which pulls US COVID-19 data daily from 2 different sources. Then, process the data and create a dashboard for it.
Link with full description is here
My approach
I have some experience with AWS and recently started to learn Python, so I had an idea where to start with.
Here's the architecture diagram:
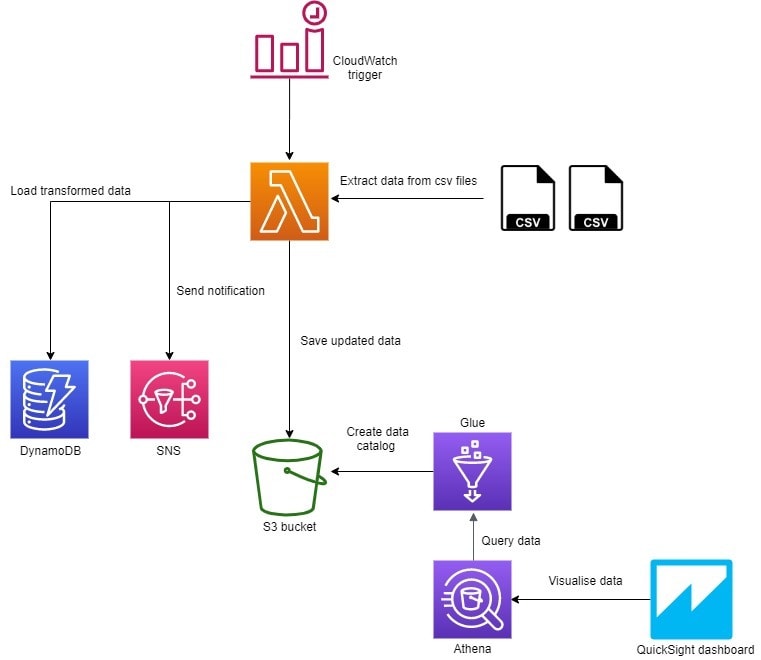
ETL
I used Pandas to read the data from csv files into DataFrame. The data is merged, validated and loaded into DynamoDB. Here, I thought about having 3 Lambdas, one for each part of the process, but since the data is small, decided not to do it.
DynamoDB was chosen to keep the project serverless.
After data is in the database, its copy is stored in csv file in S3, and notification with ETL result is sent to SNS.
Dashboard
I never used QuickSight before, and playing with it was the most fun part of the project.
Here are my visualisations (there's no option to share then publicly in QuickSight unfortunately, so only the screenshots):


My learnings
Lambda. When Lambda has external dependencies which are not part of AWS Linux distribution on which it will run, you need to zip them up with your code. I used Windows computer for development, and when I ran install libraries from requirements.txt file, it installed Windows version of them. So, when I deployed it to the cloud, it didn't work. It took me several hours to figure out what was the problem.
CloudFormation. I never worked with it before, and happy I had this opportunity to learn it.
Visualisation. When I was planning my solution, I knew that Glue crawler works with S3 and DynamoDB. I also knew that Athena works with Glue catalogs. So I assumed that Athena would be able to query table generated by Glue crawler if I store data in DynamoDB. When I got to this point in implementation, and everything else was working, it turned out that Athena can't query Glue table if it was generated from DynamoDB. To solve this, I decided to save a copy of DynamoDB data in a csv file in S3 and then Glue crawler would create catalog from this file. Considering the small size of data, I think it's appropriate in this case. Probably not the best solution, and a point to improve in the future.
Conclusion
Although I've done the all tasks required in the challenge, I think there are things that can be improved/further worked on, e.g. creating CI/CD pipeline.
I'd like to say big thank you to Forrest Brazeal for setting up this challenge. I've learned a lot from it and looking forward to do more challenges!
GitHub repo: https://github.com/nadyaf/cloudguru-092020-challenge

Top comments (0)