
Even though deep learning performance advanced greatly over recent years, its vulnerability remains a cause for concern. Learn how neural networks can be fooled in this post and stay tuned for more tips on improving your neural networks’ safety .
In 2014 Szegedy et al. [1] discovered that many machine learning models, including achieving state-of-the-art performance neural networks , are highly vulnerable to carefully crafted adversarial attacks, i.e. attacks based on minor modifications of the input. In the next years, many algorithms have been proposed to generate samples that can fool neural networks, so-called “adversarial examples”. In today’s post, we’ll discuss 3 different methods of doing so.
Fast gradient sign method
Goodfellow et al. [2] proposed to add a carefully crafted small noise vector in order to fool the neural network. Below you can see an example. We start with the image correctly classified as an African elephant. After adding an imperceptible noise, the neural network recognized an image as a sea snake.
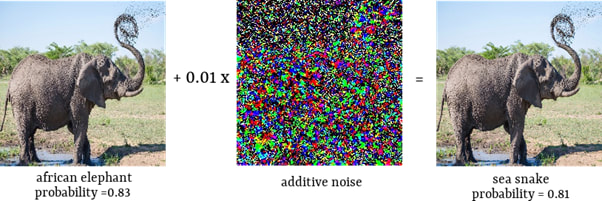
The illustration of the fast gradient sign method to fool a neural network. After adding imperceptibly small noise to the image presenting an African elephant the neural network recognizes it as a sea snake with 81% confidence (Photo by Andrew Rice on Unsplash).
Jacobian-based Saliency Map Attack
Papernot et. al [3] introduced a method called Jacobian-based Saliency Map Attack (JSMA), which tries to alter as few pixels as possible. To achieve this it uses a saliency map, which shows an impact each pixel has on the classification result. A large value means, that changing this pixel will have a significant impact on the outcome of the classification. The JSMA algorithm picks the most important pixel based on a saliency map and changes it to increase the likelihood of the attack target class. The process is repeated until the network is fooled or the maximal number of modified pixels is reached (in that case the attack was unsuccessful). Here is an example:

The illustration of the JSMA algorithm. On the left side, the original image correctly classified as jellyfish is presented. In the middle, you can see the image after the attack, recognized as a sea lion. On the right side, there is an amplified difference between the two images. 146 pixels were changed in order to perform the attack, which constitutes less than 1% of all pixels (Photo by Patrick Brinksma on Unsplash).
One pixel attack
The last method that will be described in this article requires to only change one pixel in the input image in order to fool the neural network [4]. It is based on a differential evolution algorithm. It works as follows: multiple random changes are made to the image and it is checked how these changes influence the class confidence of the network. The goal is to decrease the confidence of the network in the appropriate class. Worst scenarios (little or no change in confidence) are ignored and the search is continued around most promising candidates. As a result, the confidence in the proper class will be very low and a different class will take over.

The illustration of the one pixel attack method introduced in [4]. On the left side, the original image is presented, correctly recognized as an African elephant. On the right side, the image with one pixel changed can be seen, which results in the wrong classification result (Photo by AJ Robbie on Unsplash).
To sum up
It has been proven that neural networks are vulnerable to adversarial attacks. This calls into question their applicability in real-world scenarios, especially in systems where assuring safety is crucial. Thus it is very important to be able to defend against such attacks . In our next post, we will present some methods to achieve this.
Literature
[1] Szegedy, Christian, et al. “Intriguing properties of neural networks.” arXiv preprint arXiv:1312.6199 (2013)
[2] Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. “Explaining and harnessing adversarial examples.” arXiv preprint arXiv:1412.6572 (2014)
[3] Papernot, Nicolas, et al. “The limitations of deep learning in adversarial settings.” 2016 IEEE European symposium on security and privacy (EuroS&P). IEEE, 2016
[4] Su, Jiawei, Danilo Vasconcellos Vargas, and Kouichi Sakurai. “One pixel attack for fooling deep neural networks.” IEEE Transactions on Evolutionary Computation 23.5 (2019): 828-841

Top comments (0)